Проверяем 1Сные мифы. Часть 2
Artem GrimutaВ конце апреля разработчики технологической платформы выпустили финальную версию 8.3.23., в которой появились пару интересных функциональностей про которые мы поговорим отдельно.
В ходе же данной статьи продолжим цикл "Проверка 1Сных мифов" и тему проведения экспериментов над платформой.
Все рассматриваемые эксперименты будем проводить на свежей версии 8.3.23.1688.
ЗначениеЗаполнено() или .Количество()
Одной из популярных задач при работе со списками является определение их заполненности, т.е. проверки на наличие хотя бы одного элемента.
Для решения данной задачи используются следующие подходы:
- с помощью функции "ЗначениеЗаполнено" проверяется наличие хотя бы одного элемента
Если ЗначениеЗаполнено(ВходнойМассив) Тогда // Исполняемая логика КонецЕсли;
- с помощью функции "Количество" определяется общее количество элементов, а затем сравнивается с нулем
Если ВходнойМассив.Количество() > 0 Тогда // Исполняемая логика КонецЕсли;
При этом поведение системы при вычислении "ЗначениеЗаполнено" кажется весьма логичным: глянули есть ли один элемент и завершили, а вот подсчет общего количества элементов ради определения пустой ли он наоборот кажется весьма затратным.
Однако многие разработчики используют именно подход с количеством. Неужели они просто не задумываются и стараются усложнить выполнение кода системы? Или же платформа не выполняет полный перебор элементов?

Чтобы ответить на эти вопросы давайте проведем простой эксперимент в ходе которого будем увеличивать количество элементов в списке и замерять время выполнения данных функций. А так как мы не знаем как устроено хранение списков на нижнем уровне платформы и насколько поведение функций у разных типов может отличаться, то в ходе эксперимента будем сравнивать выполнения у массива, соответствия и таблицы значения.
// Пример реализации:
Для НомерЭксперимента = 1 По КоличествоЭкспериментов Цикл
ЗаполнитьСписокТестовымиДанными(ВходнойМассив, НомерЭксперимента);
НачалоЗамера = ТекущаяУниверсальнаяДатаВМиллисекундах();
// Выполним функцию 1000 раз.
Результат = ЗначениеЗаполнено(ВходнойМассив);
// ...
Результат = ЗначениеЗаполнено(ВходнойМассив);
ВывестиРезультат("Массив_ЗначениеЗаполнено",
(ТекущаяУниверсальнаяДатаВМиллисекундах() - НачалоЗамера) / 1000);
НачалоЗамера = ТекущаяУниверсальнаяДатаВМиллисекундах();
// Выполним функцию 1000 раз.
Результат = ВходнойМассив.Количество() > 0;
// ...
Результат = ВходнойМассив.Количество() > 0;
ВывестиРезультат("Массив_Количество",
(ТекущаяУниверсальнаяДатаВМиллисекундах() - НачалоЗамера) / 1000);
КонецЦикла;
Запустим разработанные тесты и получим следующие результаты:
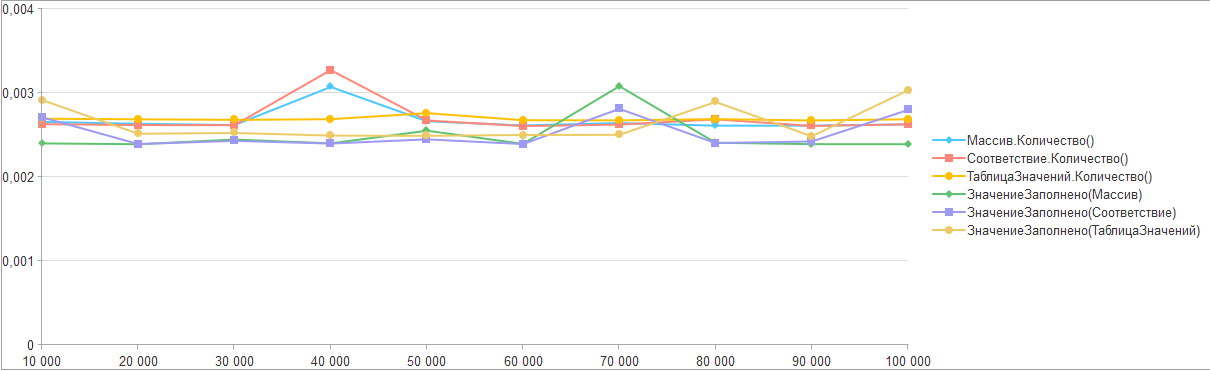
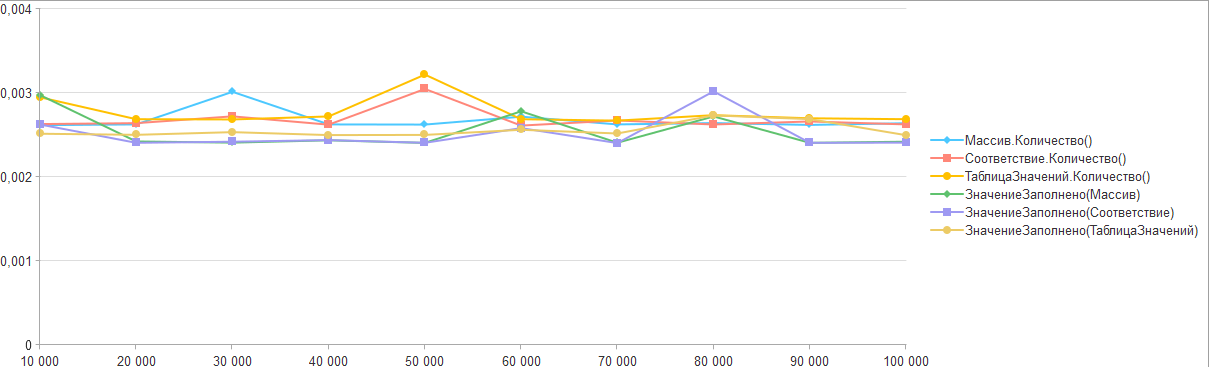
Как можно увидеть: увеличение количества элементов в списках никак не отразилось на времени выполнении функций, а разница во времени выполнения практически отсутствует.
На основании чего можно предположить, что платформа не рассчитывает общее количество каждый раз, а лишь использует некое внутреннее свойство отвечающие за количество элементов коллекции. Что же касаемо функции "ЗначениеЗаполнено", то скорее всего после определения типа входного параметра идет обращение к тому же свойству количества элементов.
Таким образом, разработчики технологической платформы обеспечили эффективное выполнение данных методов и позволили 1С разработчикам выбирать любой из них себе по вкусу.
Перемещение по строке
Несмотря на то, что технологическая платформа постепенно развивается и в ней появляются удобные функциональные блоки иногда их хочется получить чуточку раньше, а желательно сразу их поддержку в предыдущих версиях.
Схожая ситуация произошла с нами при разработке блока обмена с внешней программой с помощью файлов в формате JSON. Проблема заключалась в том, что обмен необходимо было реализовать в программном продукте на 8.2, а удобные средства по работе с ним появились только в версии 8.3.6.1977.

Соответственно для работы с форматом JSON нам требовалось реализовать собственный сериализатор на встроенном языке или же воспользоваться внешней компонентой. Т.к у нас уже были наработоки на встроенным языке, то мы решили остановиться на них.
Однако протестировав их под нагрузкой мы выявили проблемы со скоростью обработки. Одна из которых заключалась в многократном получении текущего символа с помощью функции "Сред".

В связи с этим перед нами стояло две задачи: сократить количество вызовов функции получения текущего символа за счет сохранения их в переменные, а также проанализировать прочие возможности платформы, которые бы позволяли решить эту задачу.
Если поискать в интернете способы получения текущего символа, а также перемещения по строке в 1С, то наиболее популярный ответ будет использовать функцию "Сред" с увеличением начального индекса. Тем самым получится пройти по всей строке.
Для Счет = 1 По СтрДлина(ВходнаяСтрока) Цикл ТекСимвол = Сред(ВходнаяСтрока, Счет, 1); КонецЦикла;
Соответственно для прохода по всей строке платформе придется на каждой итерации доходить до нужного индекса в строке и брать оттуда значение. Для оптимизации данного момента в некоторых языках программирования доступна возможность обхода по символам строки с помощью операторов цикла.
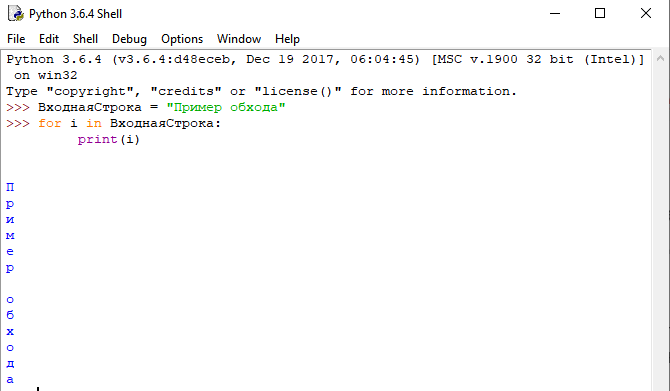
Однако пока в технологической платформ такой возможности нет. Потому поищем иные способы решения.
Например, можно постоянно брать только первый символ, а после его получения выполнять обрезку строки.
Пока ЗначениеЗаполнено(СтрДлина(ВходнаяСтрока)) Цикл ТекСимвол = Лев(ВходнаяСтрока, 1); ВходнаяСтрока = Сред(ВходнаяСтрока, 2); КонецЦикла;
С одной стороны, это действительно позволяет сократить время на получение текущего символа, но прироста к скорости это точно не даст из-за постоянного получения и переприсваивания оставшейся части строки.
Если попробовать копнуть чуть дальше, то на помощь может прийти функция "КодСимвола", которая позволяет получить код символа Unicode по переданному индексу. Однако для корректного сравнения с прочими способами потребуется воспользоваться функцией обратного преобразования "Символ".
Для Счет = 1 По СтрДлина(ВходнаяСтрока) Цикл КодТекСимвола = КодСимвола(ВходнаяСтрока, Счет); ТекСимвол = Символ(КодТекСимвола); КонецЦикла;
К сожалению, применение данного способа также не дает хоть какого-либо преимущества.
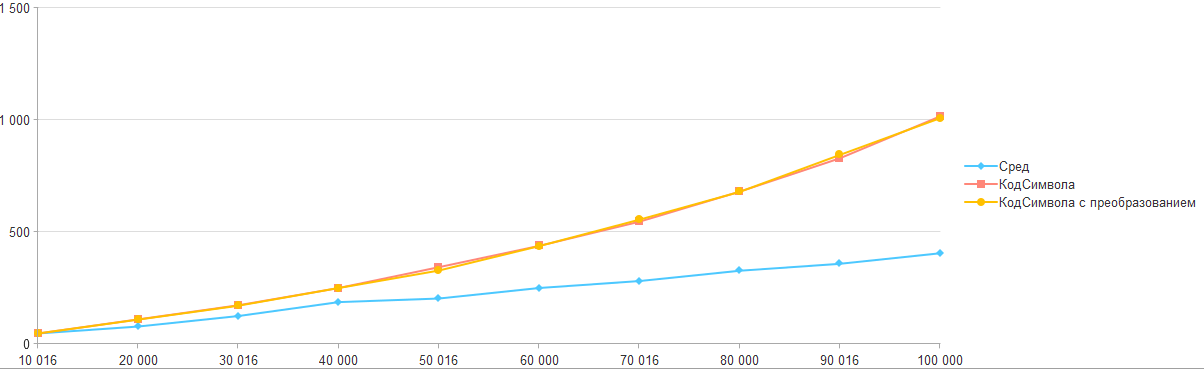
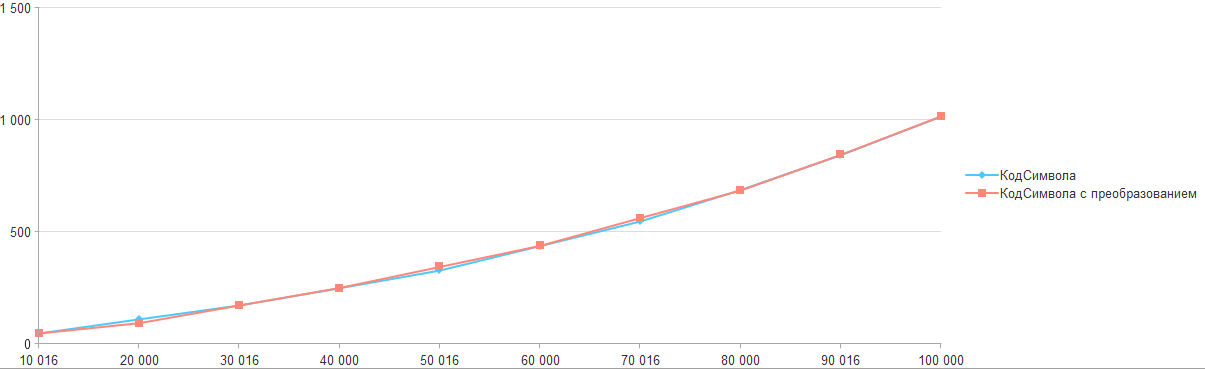
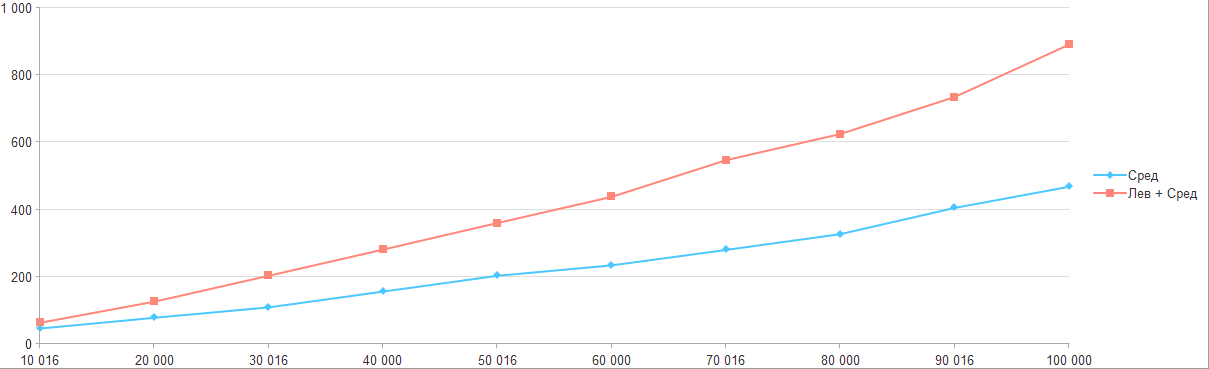
Соберем все результаты в общий график:
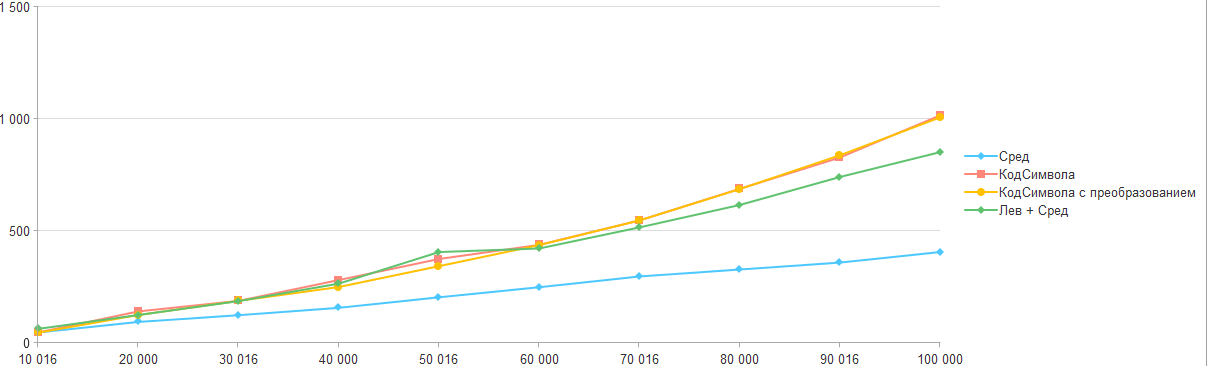
Так что если перед вами стоит задача перемещения по строке, то пока самый оптимальный способ является обычное получение через "Сред", а остальные подходы слишком проигрывают.
Вместо заключения
Первая часть данного цикла "Проверяем 1Сные мифы. Часть 1" оказалась весьма удачной и обсуждаемой. Потому не продолжить ее было бы неправильно, а главное вопросов касаемых скорости выполнения платформенных функций еще достаточно. Уже даже есть заготовка для следующей статьи данного цикла :)
В рамках же данной статьи были рассмотрены две теории: действительно ли функция "ЗначениеЗаполнено" выполняется быстрее, чем "Количество() > 0", а также какие платформенные методы позволяют наиболее быстро посимвольно перебрать строку.
Результаты проверки первой теории оказались весьма неожиданными. Ведь оказалось, что при выполнении метода "Количество()>0" система не выполняет постоянный пересчет элементов, а потому разницы выполнения "ЗначениеЗаполнено" - не было.
А вот поиск наиболее эффективного метода для перебора строки доказал, что пока самый оптимальный является метод "Сред" и это не очень радует. Т.к. чаще всего он выполняется не очень оптимально. Если же вы знаете еще какие-то способы перебора - пишите в комментариях официального канала и их обязательно проверю.
Больше полезных материалов на официальном канале 1С и точка.