Проверяем 1Сные мифы. Часть 1
Artem GrimutaТехнологическая платформа постоянно развивается, но мифы о скорости операций продолжают сохраняться и передаваться из поколения в поколение разработчиков.
Цель данной серии статей провести эксперименты на актуальной версии платформы и убедиться в правдивости мифов.
Самой последней версией на текущий момент является 8.3.22.1750. Потому все дальнейшие эксперименты будут на ней.

Операторы "НЕ =" или "<>"
Еще во время моего погружения в 1С я услышал историю, что оператор <> отрабатывает дольше, чем оператор НЕ.
Возможно, данный миф придумал разработчик не любящий переводить язык и зажимать shift, но давайте проверим.
Для этого будем выполнять данные операции от 5 до 100 тысяч раз.
ВсеЭлементы = Новый Массив; Для Счет = 0 По КоличествоИтераций + 1 Цикл ВсеЭлементы.Добавить(Строка(Новый УникальныйИдентификатор)); КонецЦикла; // Оцениванием НЕ. Для Счет = 0 По КоличествоИтераций Цикл Результат = НЕ (ВсеЭлементы[Счет] = ВсеЭлементы[Счет + 1]); КонецЦикла; // Оцениванием <>. Для Счет = 0 По КоличествоИтераций Цикл Результат = (ВсеЭлементы[Счет] <> ВсеЭлементы[Счет + 1]); КонецЦикла;
В результате эксперимента получаем следующую картинку:
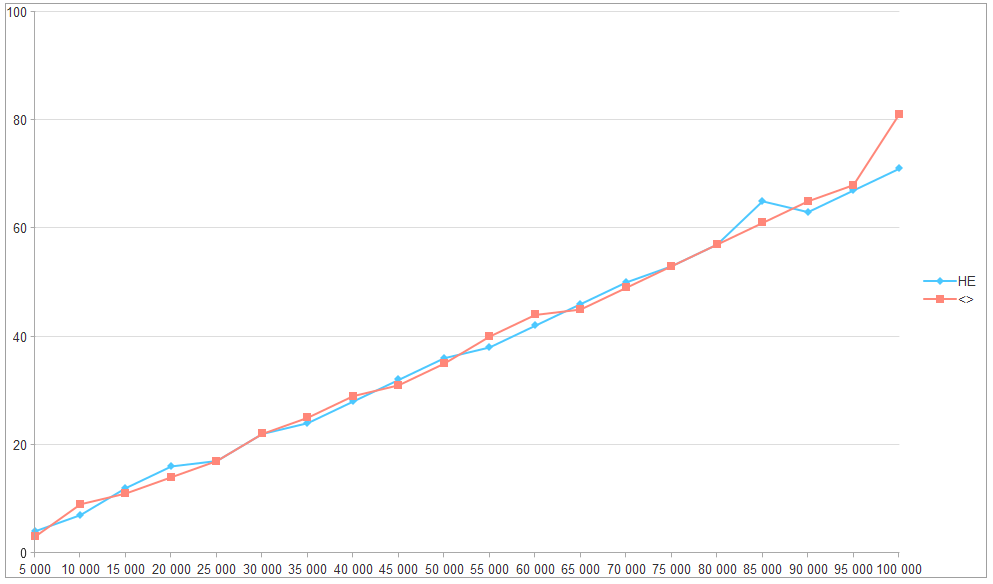
На данном графике отражается количество миллисекунд, затраченное на выполнение соответствующих операций N раз.
Получается, что время отработки операторов практически всегда совпадает, а те моменты, когда отличаются - близки к погрешности.
Что же с запросами? Ведь синтаксис 1С запросов поддерживает и там оба подхода. Так-то да, но запросы выполняются на стороне СУБД. Потому от платформы скорее зависит, как она транслирует их в термины СУБД.
Для того, чтобы ответить на этот вопрос воспользуемся технологическим журналом, который позволяет заглянуть во внутреннюю кухню исполняемого кода.
Журнал будем собирать по событиям "SDBL" и "DBMSSQL", а для анализа операторов выполним запрос:
ВЫБРАТЬ НЕ Справочник.Лево = Справочник.Верх КАК ПолеНЕ, Справочник.Лево <> Справочник.Верх КАК ПолеНЕСимволами ИЗ Справочник.УОП_Столы КАК Справочник ГДЕ Справочник.Ссылка = &Ссылка
Запрос идет к справочнику, т.к. иначе платформа вычисляет значения полей и просто передает значения. Подробно про это мы рассказывали в статье от экспертов "1С-Рарус".
После выполнения запроса получаем следующий текст на стороне СУБД:
SELECT
CASE
// Тут видим NOT.
WHEN (NOT (((T1._Fld22362 = T1._Fld22363))))
THEN 0x01
ELSE 0x00
END,
CASE
// Тут видим <>.
WHEN (T1._Fld22362 <> T1._Fld22363)
THEN 0x01
ELSE 0x00
END
FROM
dbo._Reference539 T1
WHERE
((T1._Fld1608 = @P1)) // Отбор по разделителю данных
AND ((T1._IDRRef = @P2)) // Отбор по ссылке на объект
Таким образом, платформа не пробует привести операторы к единому варианту и возможна ситуация с различной скоростью выполнения операций, но это уже совершенно другая история :)
Поиск в списках
В технологической платформе поддерживаются различные структуры данных для хранения списков, а одной из задач использования списков является поиск элементов в них.
Считается, что поиск в соответствии является самым быстрым. Однако при использовании других типов коллекций не понятно насколько поиск будет выполняться дольше.
Потому выполним сравнение времени поиска одинаковых элементов в следующих коллекциях: массив, фиксированный массив, соответствие, фиксированное соответствие и список значений.
В качестве элементов будут строковые гуиды, а для исключения влияния упорядоченности структур проведем эксперименты, когда элементы упорядоченные.
// Пример поиска в соответствии. Для Каждого ЭлементПоиска Из СписокВсехЭлементов Цикл НайденноеЗначение = ТекСоответствие[ЭлементПоиска]; КонецЦикла; // Пример поиска в массиве. Для Каждого ЭлементПоиска Из СписокВсехЭлементов Цикл НайденноеЗначение = ТекМассив.Найти(ЭлементПоиска); КонецЦикла; // Пример поиска в списке значений. Для Каждого ЭлементПоиска Из СписокВсехЭлементов Цикл НайденноеЗначение = ТекСписокЗначений.НайтиПоЗначению(ЭлементПоиска); КонецЦикла;
В результате запуска экспериментов получаем следующие замеры.
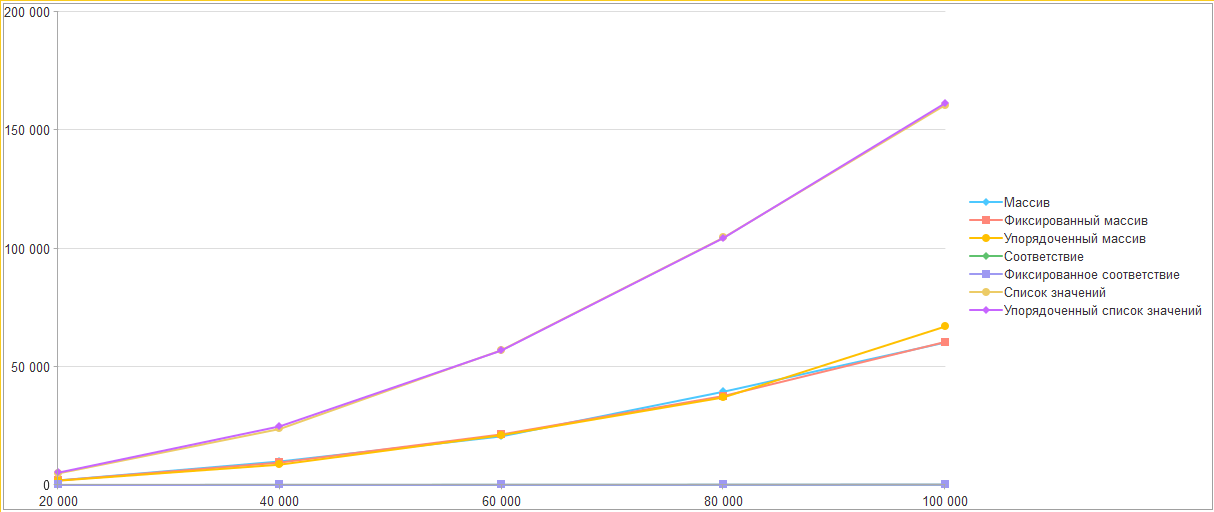
Как можно заметить самой быстрой структурой оказалось соответствие. Причем разница уже заметна и на поиске 20 тысяч элементов, где соответствие справилось за 26 миллисекунд, массивы за 2 секунды, а списки за 5 секунд. Для поиска 100 тысяч элементов соответствию потребовалось 149 миллисекунд, массивам 61 и 67 секунд, а спискам 161 секунду.
Что же касается фиксированных структур хранения - их результаты повторяют их динамические аналоги. Упорядоченность структур также практически не повлияло. Потому можно предположить, что данные характеристики не являются значимыми при поиске платформенными методами.
Если поиск в соответствии настолько хорош, то давайте оценим приблизительную стоимость перелива из исходной коллекции в новое соответствие.
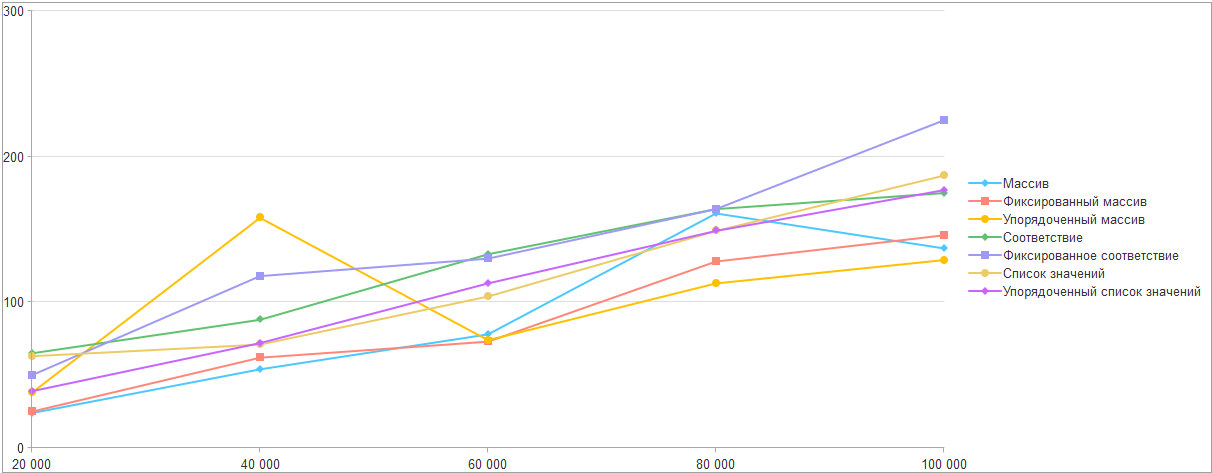
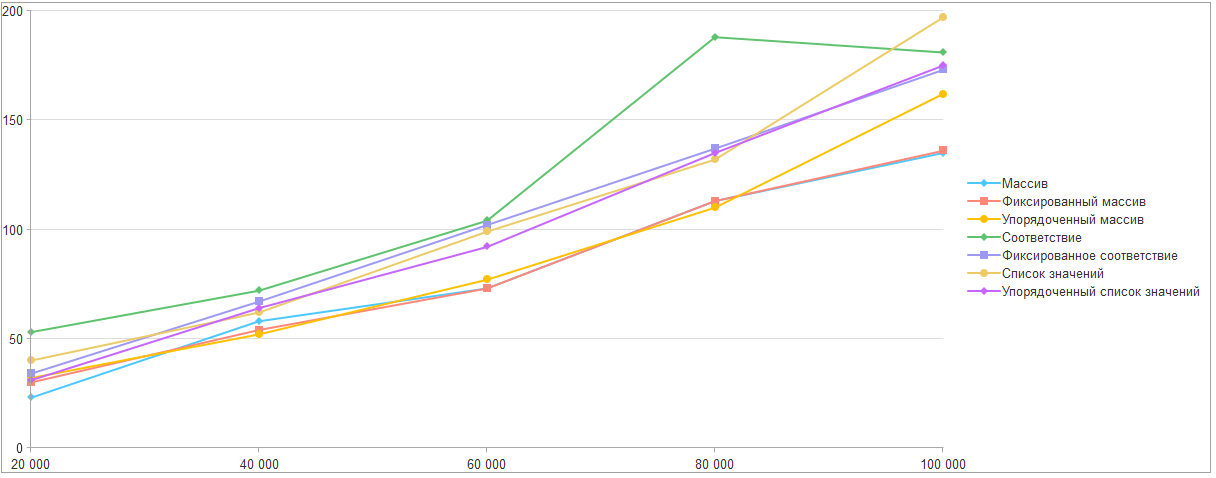
По результатам двух запусков получаем максимум 215 миллисекунд при переборе фиксированного соответствия и добавления 100 тысяч элементов.
Следовательно, можно сделать вывод: перенос из коллекции другого типа в соответствие и поиск в нем дает прирост и чем больше элементов в списке, тем значительнее.
Реквизиты по ссылке через точку (Ссылка.Ссылка.Реквизит)
Одним из способов получения данных является использование объектной модели и получение значений обращаясь через точку. Например, Сотрудник.Должность.ПолноеНаименование.
Использование данного подхода не рекомендуется и чуть позже объясню почему, но меня всегда интересовало, как платформа реагирует на ситуацию обращения к ссылке на саму себя. Например, Сотрудник.Ссылка.Должность.ПолноеНаименование или Сотрудник.Должность.Ссылка.ПолноеНаименование.
Ведь ссылка представляет из себя гуид, который четко указывает на конкретный объект базы данных. Следовательно логично предположить, что если пользователь написал Ссылка.Ссылка.Код, то платформе не требуется дважды рассчитывать значение, а достаточно выполнить Ссылка.Код. Однако логично ли это самой платформе?
Для того, чтобы ответить на этот вопрос повторно запустим сбор технологического журнала и выполним следующий код на встроенном языке 1С:
// Где ЗначениеСсылки - ссылка на объект справочника Столы. ЗначениеРеквизита = ЗначениеСсылки.Ссылка.Код;
После сбора получаем два выполненных запроса. Первый запрос получает версию данных объекта:
SELECT T1._Version FROM dbo._Reference539 T1 WHERE ((T1._Fld1608 = @P1)) // Отбор по разделителю данных AND (T1._IDRRef = @P2) // Отбор по ссылке
Второй же получает все реквизиты объекта:
SELECT T1._IDRRef, T1._Version, T1._Marked, T1._PredefinedID, T1._OwnerIDRRef, T1._Code, T1._Description, T1._Fld22361, T1._Fld22362, T1._Fld22363, T1._Fld22364, T1._Fld22365, T1._Fld22366, T1._Fld22367, T1._Fld22368RRef, T1._Fld22369RRef, T1._Fld22370, T1._Fld22371RRef, T1._Fld1608 FROM dbo._Reference539 T1 WHERE ((T1._Fld1608 = @P1)) // Отбор по разделителю данных AND (T1._IDRRef = @P2) // Отбор по ссылке
Аналогичное поведение будет при выполнении Ссылка.Код и Ссылка.Ссылка.Ссылка.Ссылка.Код.
Т.е. технологическая платформа, анализируя информацию о версиях данных, пытается сократить количество выполняемых запросов.
Однако важно отметить, что если у объекта метаданных есть табличные части, то при получении реквизитов через точку происходит выборка всех реквизитов, в том числе и табличных частей. Именно поэтому получение данных через точку является не лучшей идей.
Хорошо, а что с получением данных с помощью явного запроса?
Выполним следующий запрос на получение реквизита "Код":
ВЫБРАТЬ Справочник.Ссылка.Ссылка.Ссылка.Код ИЗ Справочник.УОП_Столы КАК Справочник ГДЕ Справочник.Ссылка = &Ссылка
На уровне СУБД будут выполнены левые соединения на каждое обращение через точку, а вот проблема получения всех реквизитов и табличных частей уйдет.
SELECT T4._Code// Получаемый реквизит. FROM dbo._Reference539 T1 LEFT OUTER JOIN dbo._Reference539 T2 ON (T1._IDRRef = T2._IDRRef) AND (T2._Fld1608 = @P1) LEFT OUTER JOIN dbo._Reference539 T3 ON (T2._IDRRef = T3._IDRRef) AND (T3._Fld1608 = @P2) LEFT OUTER JOIN dbo._Reference539 T4 ON (T3._IDRRef = T4._IDRRef) AND (T4._Fld1608 = @P3) WHERE ((T1._Fld1608 = @P4)) // Отбор по разделителю данных AND ((T1._IDRRef = @P5)) // Отбор по ссылке на объект.
Таким образом, при использовании обращений через точку из встроенного языка, платформа выполняет одно соединение, но выполняет получение всех реквизитов и табличных частей, а при выполнения с помощью явного запроса - наоборот.
Инициализация структур
Следующий эксперимент будет скорее не проверкой мифа, а желанием понять есть ли разница в моменте и способе инициализации структуры.
Синтаксис встроенного языка поддерживает следующие варианты инициализации:
- В параметрах инициализации указываются свойства и значения
ВходныеПараметры = Новый Структура("Свойство1, Свойство2", 1, 2); - В параметрах инициализации указываются свойства, а значения указываются после
ВходныеПараметры = Новый Структура("Свойство1, Свойство2");
ВходныеПараметры.Свойство1 = 1;
ВходныеПараметры.Свойство2 = 2; - Свойства не указываются при инициализации, а добавляются позже с помощью метода "Вставить"
ВходныеПараметры = Новый Структура;
ВходныеПараметры.Вставить("Свойство1", 1);
ВходныеПараметры.Вставить("Свойство2", 2);
Для сравнения данных вариантов будем генерировать код программно, а затем замерять время его выполнения.
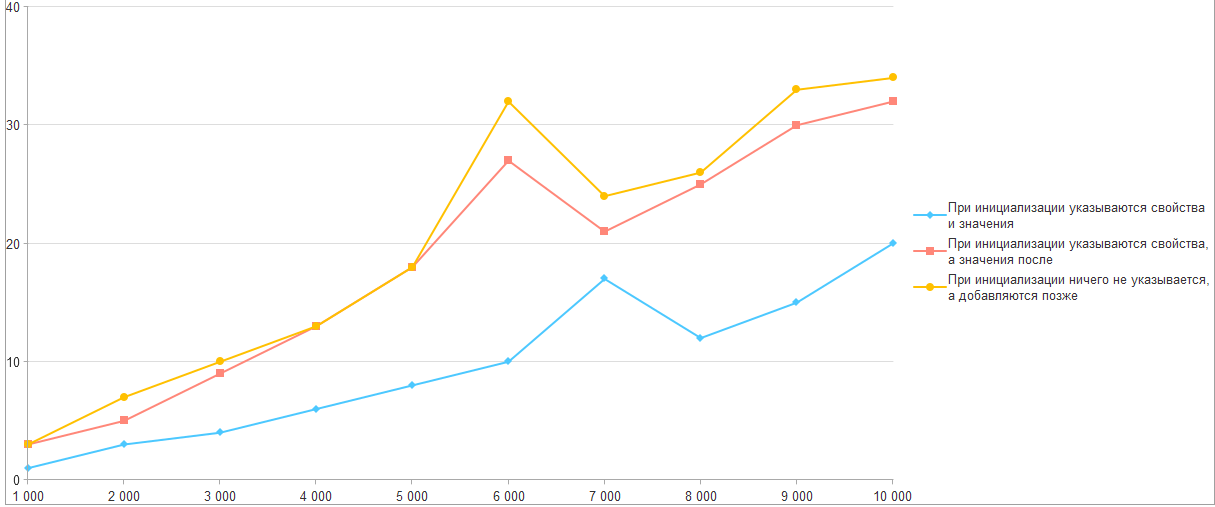
Удивительно, но факт: время выполнения вариантов отличается, и интервалы между ними сохраняются.
Наиболее эффективным способом оказалась инициализация структуры на стадии конструктора со всеми свойствами и значениями.
Так что если вы увидели общую инициализацию и посчитали ее не красивой стилистически - возможно ее сделали для оптимизации выполнения.
Вместо заключения
В одном из своих докладов на 1C-RarusTechDay 2022 я рекомендовал не верить мифам, а всегда их проверять на практике.
В данной статье мы рассмотрели лишь несколько экспериментов, но если у вас идея эксперимента и лень проверять, то пишите в комментариях - постараюсь рассмотреть в следующих статьях :)
Больше полезных материалов на официальном канале 1С и точка.