Мониторинг состояния сервисов в Prometheus/grafana
Dmitry BubnovЧасто хочется видеть состояние служб, запущенных в системе и получать своевременные уведомления о проблемах с ними. Попробуем реализовать это с помощью стека Prometheus/Grafana
В статье рассмотрим:
- Сбор данных с node_exporter
- Изменение отображения метрик
- Выборка нужной информации из всех собранных данных
- Немного PromQL - язык запросов Prometheus
- Визуализация данных в Grafana
Я уже пытался писать о стеке prometheus/grafana. Надеюсь, этот пост станет достойным продолжением эпопеи про мониторинг.
Будем считать, что Prometheus/Grafana/Node-exporter уже работает. Если ещё не работает - воспользуйтесь моим плэйбуком.
Node exporter экспортирует состояние всех служб в параметре node_systemd_unit_state.
Выборка нужной информации из всех собранных данных
В качестве даных увидим что-то вроде node_systemd_unit_state{name="nginx.service", instance="10.0.0.1", status="active"}. Видеть всю эту строку в мониторинге не нужно и часто это только сбивает с толку. Нам ведь нужны только имя сервиса и его состояние.
За подписи данных отвечает параметр Legend под строкой запроса. Туда можно вписать что угодно и это будет отображаться в легенде. Воспользуемся переменной name, в которой указано имя нашего сервиса. Если сразу после изменения данные на графике не изменились - нажмите значок глаза над запросом - там, где стрелки и корзинка. Обратите внимание, что переменная должна быть в фигурных скобках: {{name}}
Видеть состояние всех служб нужно не часто. Будем наблюдать только за важными нам сервисами. Для этого отфильтруем запрос по конкретным службам:
node_systemd_unit_state{name=~"(nginx.service|rabbitmq-server.service|memcached.service)"}
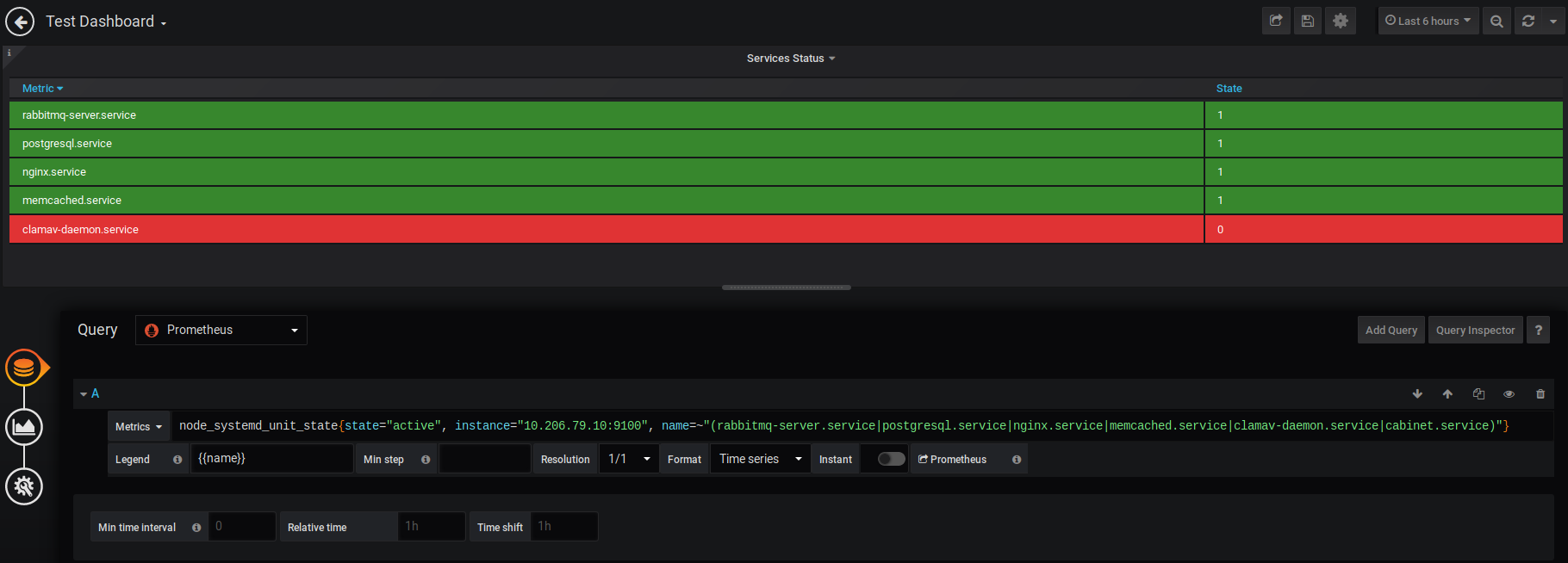
В параметре name указаны службы, за которыми будем наблюдать. Знак =~ означает выбор значений по регулярному выражению. Дальше в скобках перечислены службы, разделенные знаком | что означает ИЛИ. Теперь будем наблюдать только за нужными сервисами.
В параметрах есть ещё одно поле state - оно отвечает за состояние сервиса. нам интересны только активные, поэтому его значение active. Дополнительно можно указать хост, с которого будем отображать данные на этой панели.
Визуализация данных в Grafana
По умолчанию Grafana отображает наши данные в виде графика. В случае со службами это визуально неудобно. Поэтому будем показывать данные в виде таблицы.
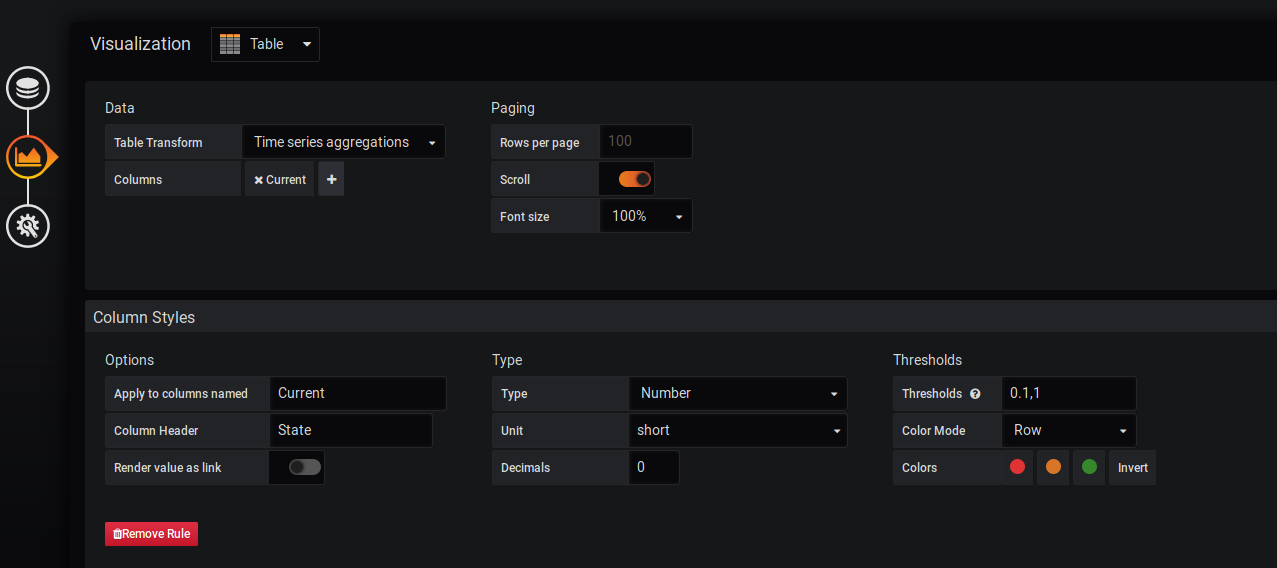
Для этого в раздел Visualization и выбираем таблицу. В Data указываем какие данные будем использовать для отображения. Нам нужно Time Series Aggregation - аггрегированные данные. В Columns выбираем Current - то есть последнее полученное значение. Мы ведь хотим знать актуальное состояние службы, а не средние данные за последний час. Сейчас уже можно видеть как преобразилось отображение данных.
Сейчас в таблице должно быть две колонки - Metric и Current, в которых описаны названия метрики и её значения. Current не очень понятно описывает колонку. Переименуем её.
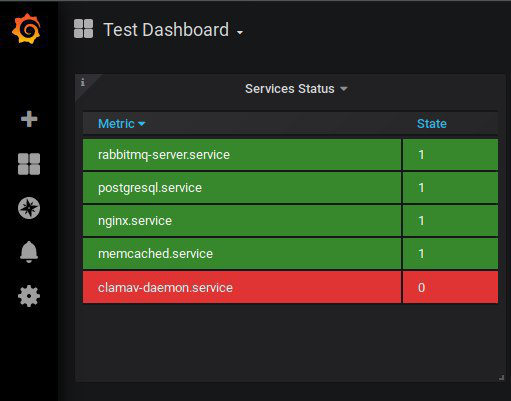
В разделе Column Styles выбираем в Apply to columns named: Current, меняем Column Header на State. Ну теперь то точно понятно =)
И покрасим рабочие службы зеленым, а нерабочие красным. Для этого есть параметр Threshold, где выставляются критические и приемлемые значения метрик. В нашем случае 0 - не работает, 1 - работает. Поэтому всё, что выше 0 будем считать рабочим и красить зеленым, а все, что ниже 0,1 нерабочим. Пример можно увидеть на картинке.
Должно получиться что-то опхожее на первую картинку в этом посте. Об уведомлениях напишу в следующий раз. Здесь просто скажу, что Grafana сама умеет реагировать на изменения и слать алерты на почту, Telegram, Slack и в другие каналы. Но у grafana это реализовано не очень удобно, поэтому все цивилизованное человечество применяет AlertManager и различные плагины к нему.
Пост написан на коленке в час ночи. Ничего сложного в grafana нет, надеюсь этот пост доказал это вам. Ставьте систему мониторинга, экспериментируйте с отображением даных, изучайте PromQL. Всё это позволит вам создать мощную, удобную и красивую систему мониторинга!
Всем добра, да пребудет с нами АДСМ