Делай RAG: опыт создания векторной базы знаний
Ekaterina Yakunenko, канал @delay_RAG
Эта публикация — это объединённая в один лонгрид серия постов о том, как я работала над RAG-базой для своего бота, проверяющего рекламные креативы на соответствие ФЗ «О рекламе». Пайплайн-воронка, его основные этапы, особенности кода и стоящей за ним логики во всех подробностях.
Этапы пайплайна
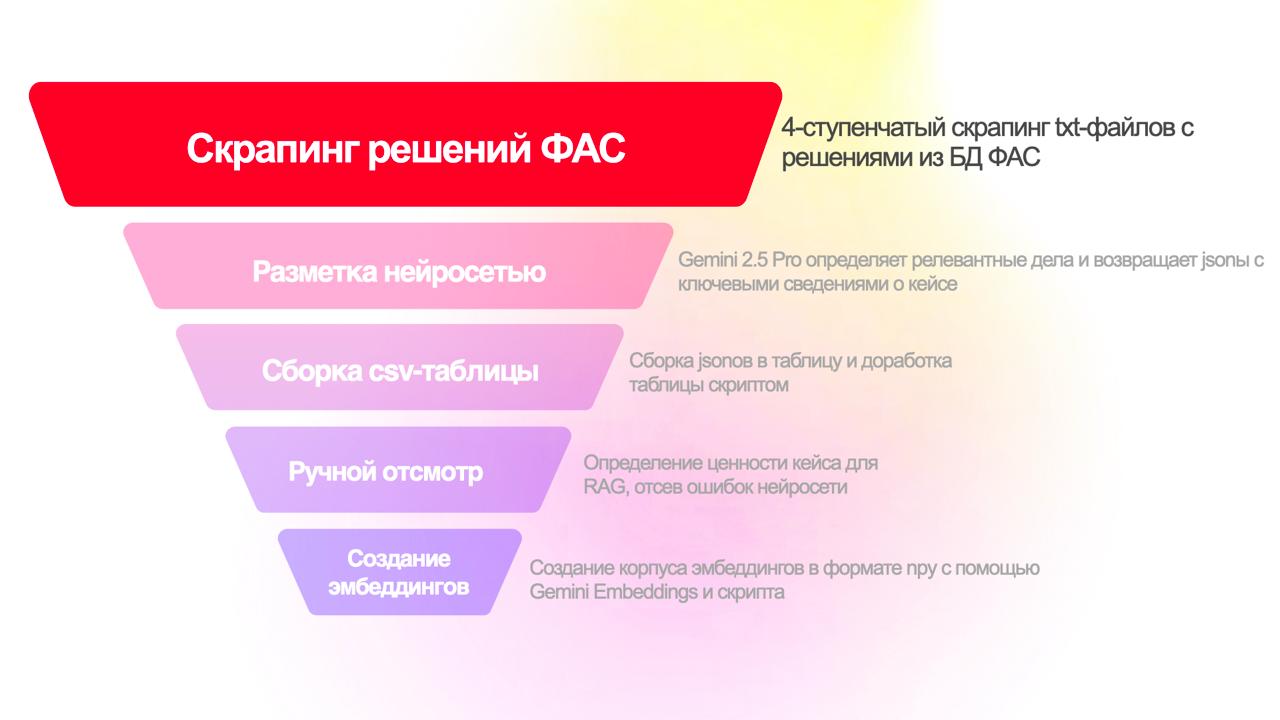
Скрапинг (или скрейпинг) — это автоматизированное извлечение информации с сайтов. То есть скрипт «читает» страницы сайтов, но намного быстрее, чем это делает человек, попутно вытягивая их них всякие нужные данные. Это была первая вайбкодинговая задачка, которую я себе поставила и которую очень быстро выполнила, и это задачка, которая может быть актуальна многим юристам, в том числе не собирающимся делать ни RAGов, ни тем более ботов. В конце этого раздела дам несколько советов о том, на что обратить внимание, если вы хотите сделать свой скрапер.
Я попросила Claude описать функциональность скрапера как-то кратко, но максимально по сути, и он выдал «интеллектуальный веб-краулер с функцией инкрементального обновления данных». Имеется в виду, что скрапер умеет собирать дела за указанный пользователем временной период, причем как смотрит новые (отсутствующие в базе), так и отслеживает появление новых решений в уже известных делах.
Здесь нужно небольшое пояснение. ФАС структурирует базу данных (по крайней мере в части рекламных дел) так: создает карточку дела, которой присваивается UUID (подробнее об этом здесь). Внутри карточки с делом размещаются документы по делу отдельными страничками (определение о возбуждении, решение, предписание и т.д). Соответственно, в разных моментах времени эта карточка может быть пустой или содержать разное количество документов. Меня для целей сборки RAGа интересуют только карточки с решениями. У каждой карточки с документов есть свой UUID (в моих рабочих файлах он обозначен как docID).
Скрапер делает поисковые запросы по 4 фильтрам, затем выкачивает тексты решений в .txt и попутно ведет лог с записями всех caseID и относимых к ним docID. Это если кратко, более подробно расписанные этапы приведены в pdf-аттаче к этому посту в моём канале.
Анализировать проблемные места сайтов, с которых вы хотите что-то скрапить — важно, если вам нужна достаточно полная база без мусора. Вот несколько бутылочных горлышек, с которыми пришлось поработать (причина у них по сути одна — неконсистентное ведение базы знаний, пополняют-то её люди):
I - Выше упоминала, что поиск ведется по 4 параметрам, а именно
1) Управление — Управление контроля рекламы и недобросовестной конкуренции
2) Процедура — Реклама
3) Сфера — Рынок рекламы
4) Доп. критерии — реклама
Подавляющее большинство проходит в параметре «процедура», но далеко не все: рекламный кейс может заваляться и по другим параметрам (например, здесь, в параметре процедура указано «КоАП», а я по нему не проверяю).

II - В подавляющем большинстве дел текст решения выкладывается на странице, и скрапер его собирает и создает на моем компьютере txt-файл. Но некоторые УФАСы выкладывают тексты решений в других форматах, которые подвешивают в карточку отдельным аттачментом, оставляя основной текст страницы пустым или заполненным какой-нибудь фразой.
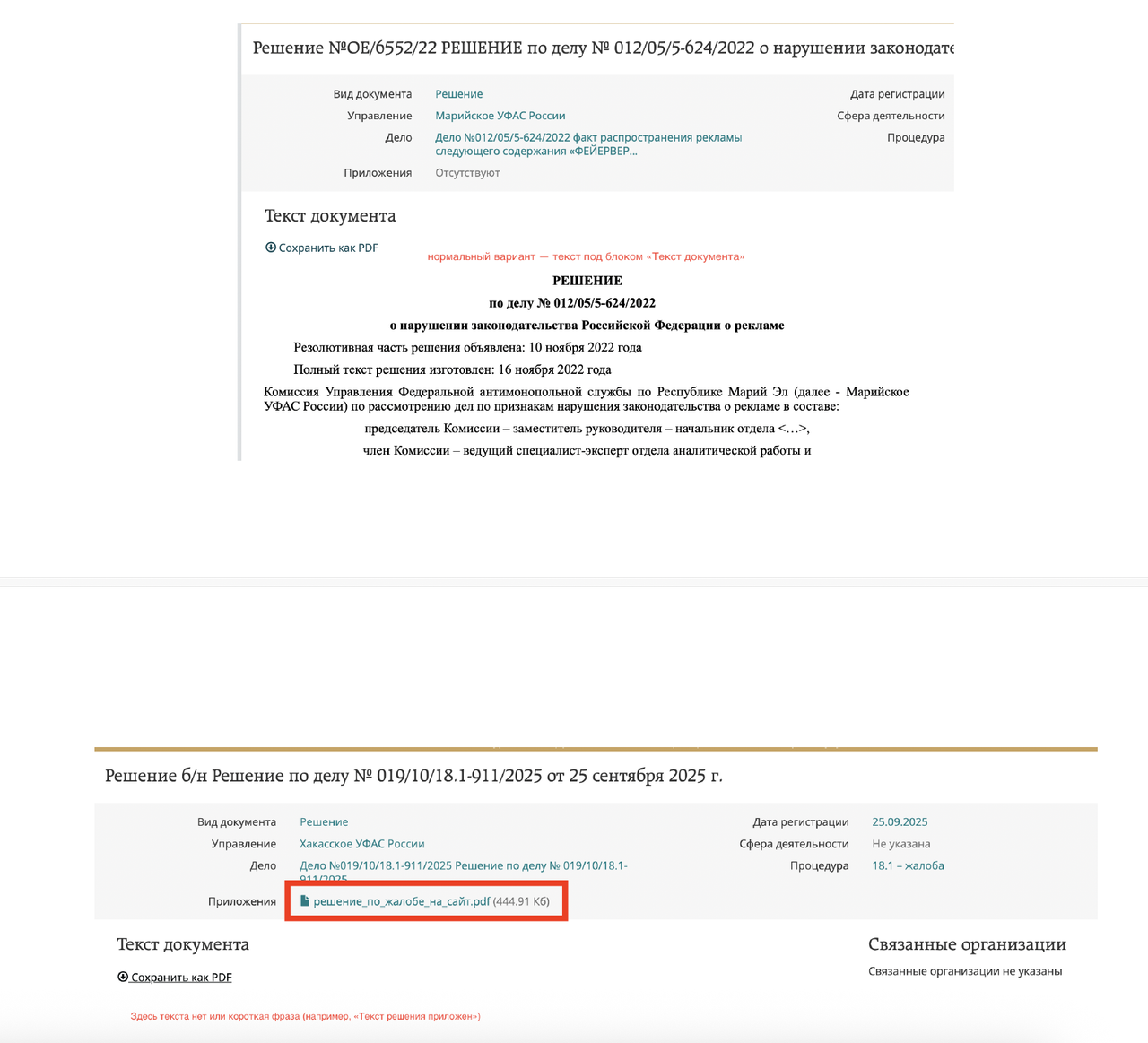
Это остается проблемой, скрапинг таких аттачей я пока не делала. Но опытным путем было установлено, что если в Gemini на разметку послать написанный ерундовый текст, то она может из этого сочинить целое дело, поэтому этот нюанс учтён в пайплайне дальше — на отправку по API на разметку идут только тексты из файлов от 100 кб.
Несколько советов по подготовке к тому, чтобы накодить себе скрапер
1️⃣ Собственно, первый вы уже поняли: нужно изучать, как устроены сайты, с которых вы хотите что-то скрапить и парсить. Нужно и глазами покопаться, и призвать на помощь нейросети: я просто сохраняла в браузере html-файлы с основной страницей поисковых фильтров, со страницей дела (где есть caseID) и страницей решения. Так и нейросети будет легче составлять код скрапера.
2️⃣ Просите закодить небольшую паузу в посылании запросов, чтобы сайт не решил, что на него не совершается DDOS-атака, и не выдал бан вашему IP (особенно если это какой-то реальный IP, с которого вы по работе часто взаимодействуете с сайтом).
3️⃣ Если для каких-то целей вы используете сервисы из трех букв, то на время скрапинга баз решений российских гос.орагнов ковровую активность этих сервисов придется приостанавливать — будьте к этому готовы.
4️⃣ Используйте обязательно логи того, где скрапер побывал и что скачал — если будут какие-то прерывания в соединении, или вы будете скрапить с какой-то регулярностью, это будет совершенно бесценной информацией, экономящей очень много времени.
5️⃣ Помните, что структурированные базы — это вообще-то охраняемый результат интеллектуальной деятельности, и полезно на всякий случай провеять режим допустимого использования. У ФАС об этом вот здесь, например:
Материалы сайта ФАС России являются общедоступными и открытыми для использования в некоммерческих (личных, ознакомительных, образовательных, исследовательских и аналогичных) целях.
Начинается превращение из «гусеницы», сырого текста решения ФАС со всякой не самой важной для целей бота информацией, в идеальную математическую бабочку-эмбеддинг. Начинается превращение с разметки.
Следующий компонент кода пайплайна отправляет каждый выскрапленный текст решения УФАС в нейросеть по API. Почти каждый, как упоминала в выше: код проверяет, точно ли там есть какой-то стоящий траты токенов текст (соломоново решение отправлять тексты из txt-файлов более 100 кб).
Если вы знаете, что такое API и зачем это нужно, процитированный блок можно пропустить.
API (Application Programming Interface) — это такой способ организовать взаимодействие созданной вами программы и какого-то другого сервиса. То есть я обращаюсь к нейросети не привычным образом через чат в браузере, а мой скрипт автоматизированно отправляет ей шаблонные запросы, она возвращает определенным образом структурированные ответы. Так и бот работает, к слову. Главная выгода использования API в моём кейсе — скорость, масштаб и сохранение качества (каждый запрос — как новый чат, не замусоренный контекстом). На данный момент я прогнала уже несколько тысяч текстов, и без скрепленного API союза нейросети и скрипта для такого же результата понадобились бы месяцы непрерывной отупляющей работы.
Промпт ставит нейросети несколько задач по анализу кейсов:
Задача 1: Первичная проверка релевантности ФЗ «О рекламе»
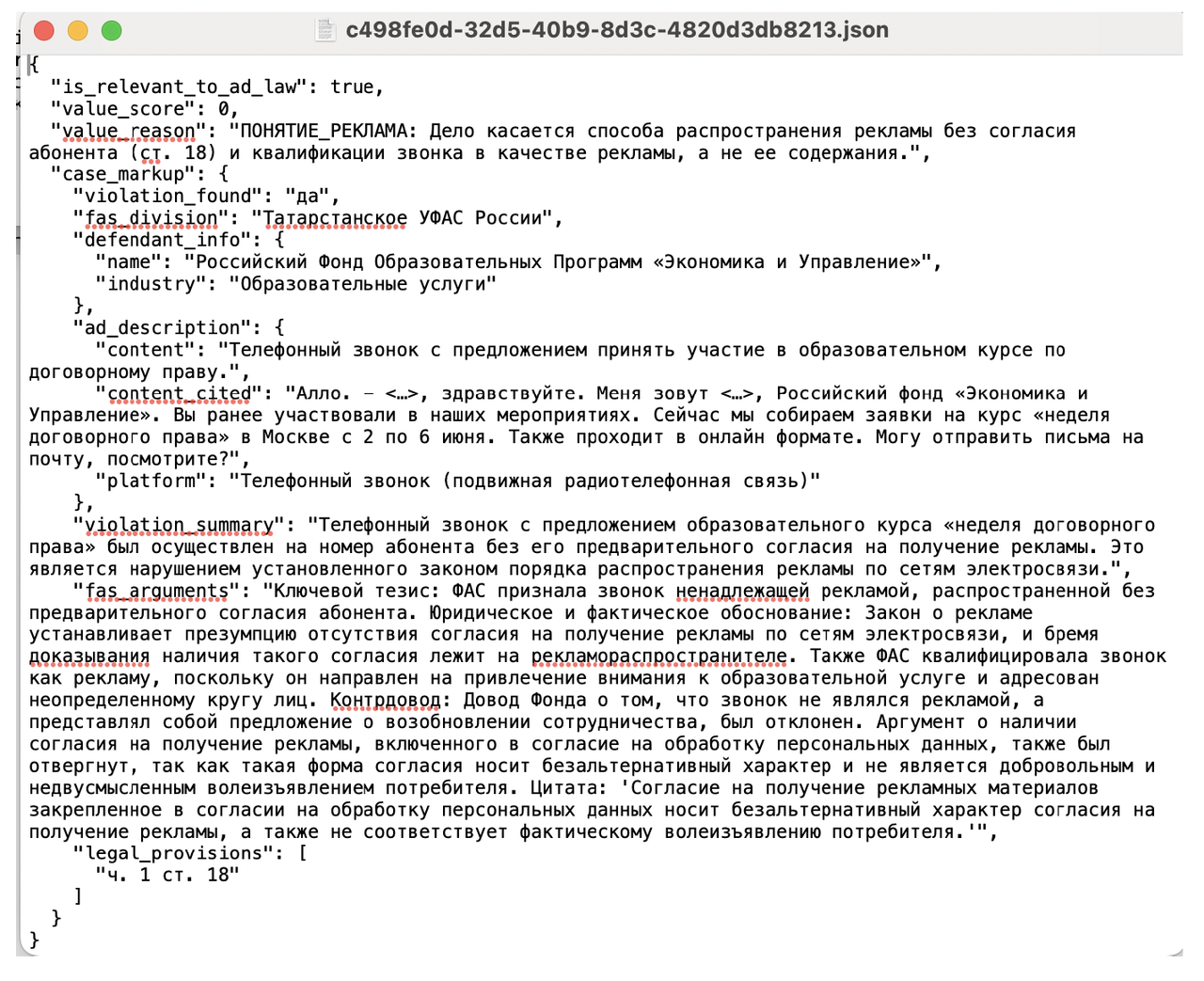
Поскольку, как вы помните, базу данных ФАС заполняют люди, а скрапинг идет по 4 фильтрам, в этих фильтрах оседает всякое не относящееся к рекламе, прежде всего, из дел по госзакупкам. Нейросеть первым делом определяет, относится ли дело вообще к ФЗ «О рекламе», и если нет, то модель должна вернуть минималистичный JSON с флагом is_relevant_to_ad_law: false и коротким объяснением причины, не тратя ресурсы на дальнейший анализ.
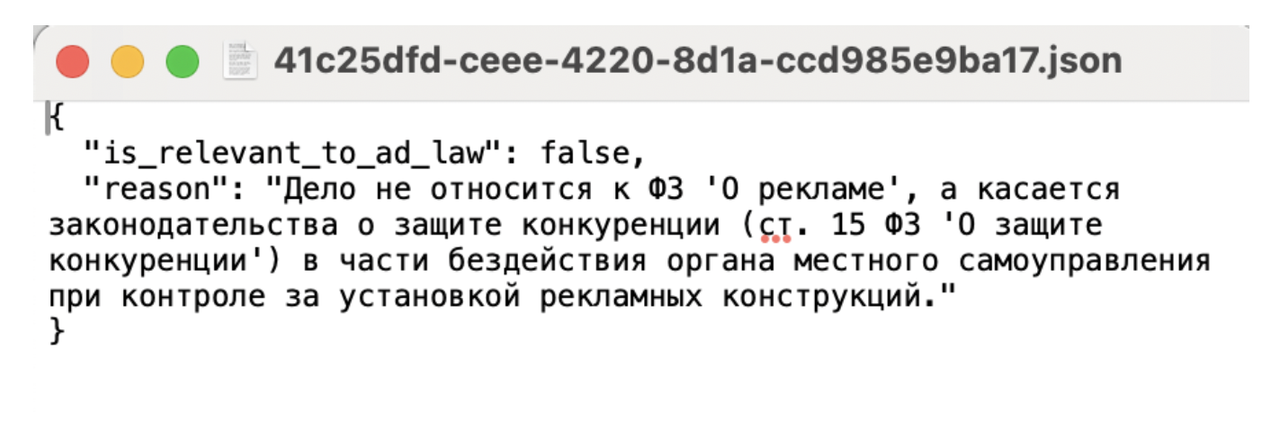
Если вы знаете, что такое JSON и зачем это нужно — процитированный блок можно пропустить.
JSON (JavaScript Object Notation) — это текстовый формат для структурированного хранения данных, который организует информацию в виде пар «ключ:значение». В приведенном выше тексте ключ — «is_relevant_to_ad_law», а значение — «false». Направляя каждый API-запрос, я запрашиваю одну и ту же информацию, и мне нужно, чтобы нейросеть её располагала не беспорядочно, как токены лягут, а именно структурированно. Если по ключу «is_relevant_to_ad_law» значение становится «true», то будет дальнейший анализ, где ключей уже намного больше. Из таких пар «ключ-значение» легко собираются таблички. Но таблички — это лишь вершина айсберга, в этих массивах легко можно вылавливать другие данные с помощью скриптов без парсинга всего текста.
Задача 2: Оценка ценности дела для RAG-базы
Прошедшие первичный отсев герои попадают на, собственно, разметку. В этой задаче у меня два основных соображения:
I - Мой бот проверяет только субстантивную часть, а всё, что касается каналов размещения и прочих нюансов реального мира (лицензии, соответствие рекламным тезисам реальному положению дел) — не трогает. Поэтому и в базе знаний этих дел мне нужно (забегая вперед скажу, что соотношение «субстантивные»-«технические» в практике делится год от года примерно 60/40 в пользу то одной категории, то второй).
II - У меня есть убеждение, что хорошему RAGу по нишевому юридическому вопросу не требуются десятки тысяч документов. Качество retrieval не станет сильно лучше, если в базе будут сотни написанных под копирку дел о том, что слова «парилки ашкудишки» на окне табачной лавки являются запрещенной рекламной табака. Нужны дела прецедентного характера, где УФАСы на высоком уровне юридической аргументации рассуждали о тонких, интересных, неочевидных вопросах, за которые мы так любим рекламное право. Без таких дел в базе, на мой взгляд, мой проект не имел бы смысла.
Исходя из этих соображений нейросети повелено делать грейдинг (регрессию?) ценности дела для базы знаний от 0 до 10 по обозначенным мной критериям. Подробно о критериях рассказано в pdf-аттаче к этому посту, а если коротко, то:
0 баллов получают все дела по вопросам размещения рекламы в материальном мире (то есть нерелевантные задачам бота);
1-3 балла — банальные прямолинейные нарушения простых требований и запретов (пиво рекламировали, дисклеймеры на БАДы забыли и т.д.);
4-7 баллов — комбинации нарушений, нарушения по определенным видам продукции, достаточно очевидные нарушения, не требующие великой аргументационной мысли, но по важным статьям;
8-10 баллов — все, что задает тон всей практике, где нет очевидного решения, пограничные случаи, слои метаиронии, всякое интересное и дающее смысл профессии.
А зачем мне нужны все эти баллы — будет ниже об этапе ручного отсмотра.
Задача 3: Структурированное извлечение данных
После оценки нейросеть извлекает ключевую информацию и составляет из неё JSON. Моделька вытягивает дату решения, название УФАСа (раньше это делалось скриптом, но при сборке пайплайна кое-что отвалилось и пришлось заставлять модель), информацию о нарушителе и отрасли, в которой он работает, детальное описание содержания рекламы с прямыми цитатами её описания, платформу размещения, суть нарушения, аргументацию ФАС с сильными цитатами из решения, а также список нарушенных норм (пункт-часть-статья) ФЗ О рекламе.
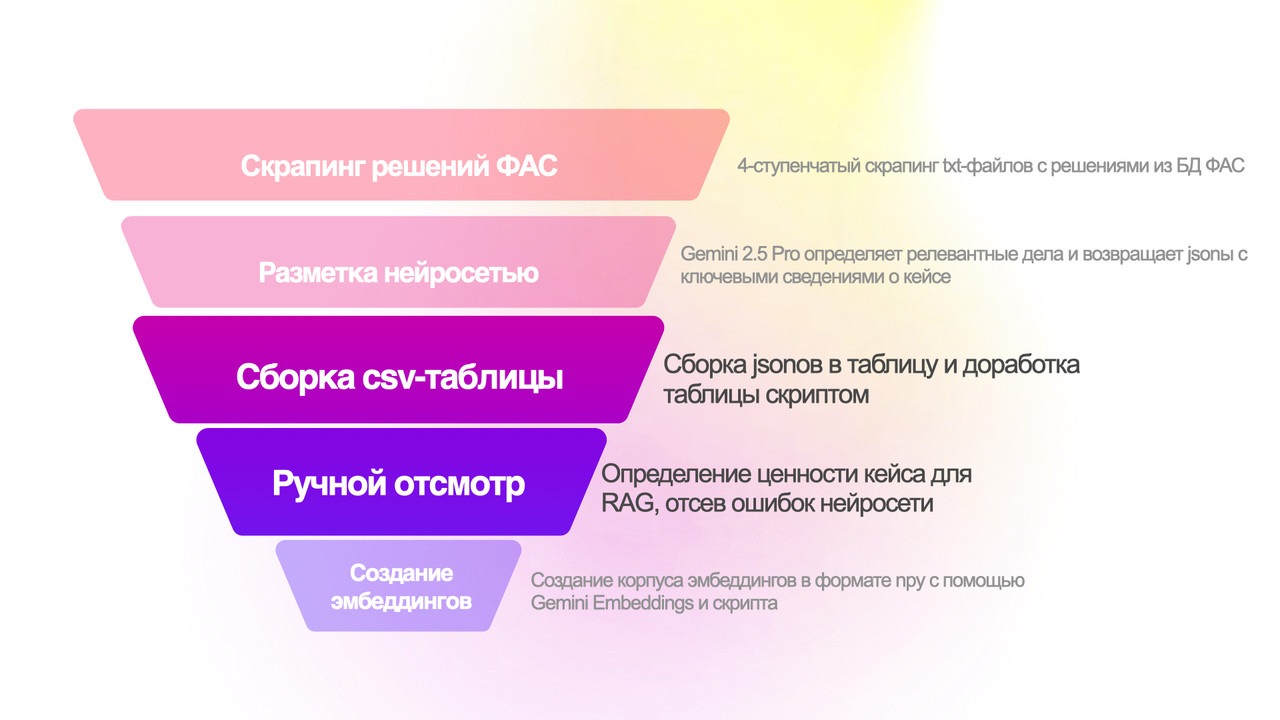
Этап ручной проверки и сборка таблиц — это в сущности один и тот же этап, но сборка таблиц технически реализована достаточно нетривиально.
Центральная функция этой части кода — собрать таблицу с релевантными для RAG (субстантивными) делами. Каждый ключ в JSONе становится колонкой таблицы.

Затем таблица с релевантными делами дополняется скриптом тремя колонками:
I - колонка с полным текстом решения ФАС из папки, в которую помещаются все txt с решениями на этапе скрапинга;
II - колонка с caseID. Как упоминала ранее, в базе решений на сайте ФАС используются UUID двух типов: для карточки с делом и для отдельных документов. Бот предлагает вам ссылки именно на карточку с делом, она проще формируется, чем ссылка на текст решения (т.к. в ссылке на текст решения есть компонент с названием УФАСа). Но в нейросеть для разметки отправляется файл с ID документа в названии, и JSON сохраняется тоже с docID (см. скриншот выше – в строке с названием окна указан именно docID).
III - колонка с «тематическими тегами». Тематические теги — это описание статей из ФЗ «О рекламе» максимально короткими ключевыми словами по типу «некорректное_сравнение», «БАД_дисклеймер».
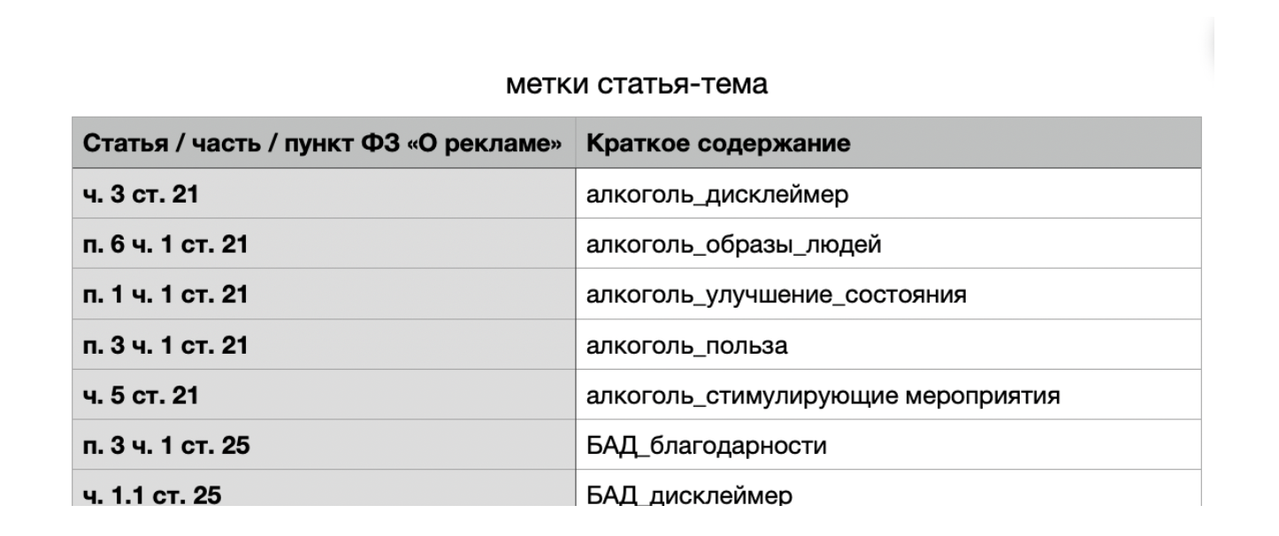

Основной функционал этих тегов — они помогают оценивать равномерное наполнение базы знаний кейсами разной тематики (чтобы не было перекоса, например, в рекламу финансовых услуг, и было побольше решений по темам, которые достаточно редко затрагиваются (например, правила о государственном языке)). У тегов есть еще и задел на будущее — они будут основой для reranking-а, который я планирую реализовать для повышения точности выдачи кейсов из базы, связью с кластером эмбеддингов для руководств ФАС, который я тоже хочу до Нового года всё же сделать.
И затем я перехожу к ручному отсмотру. Делаю я его по нескольким причинам:
- Нейросеть иногда плохо справляется с частью промпта, которая просит её считать нерелевантными дела, требующими наличия каких-то лицензий и разрешений, где содержание рекламы не совпало с реальностью. В каждом батче обязательно будет 20-30 таких дел, и, на мой взгляд, они не особо нужны для задачи, которую решает бот.
- Нейросеть получает каждый новый кейс на рассмотрение без знания обо всех предыдущих, и ей невдомек, что база знаний распухнет от однотипных решений по фразе «мы лучше, чем ломбард!».
- Мне просто это нравится! 🤗 Мне нравится рекламное право в целом, это расширяет мой профессиональный кругозор. Всё, что нейросеть оценивает на 6-9 баллов, как правило, довольно интересно смотреть.
- Я убеждена в том, что база знаний не должна быть свалкой документов, она требует кураторского подхода, и мои объемы не такие, чтобы всё отдавать на откуп нейросети.
Но нужно сказать, что вся эта система оценок действительно работает, и если лень, то можно и отдать всю задачу нейросети: просто смело брать из каждого батча дела от 5 баллов. Но и при мануальном отсмотре я полагаюсь на эти оценки: примерно с 5 баллов уже просматриваю по диагонали, подмечая только кейсы по редко освещаемым в практике вопросам, даже если там простая правовая позиция, и «поднимаю» им оценку (примеры можно посмотреть в pdf-аттаче здесь). В принципе я читаю только колонку violation_summary, иногда смотрю аргументы ФАС с цитатами. Количество осечек при суммаризации минимальное, и я каждый раз радуюсь тому, как нейросети упростили такой тип задач.
Итогом этого этапа является то, что я беру и руками копирую строки с оценкой выше 4 или 3 (зависит от батча) и вставляю в файл с основной базой, святая святых, RAG.csv.
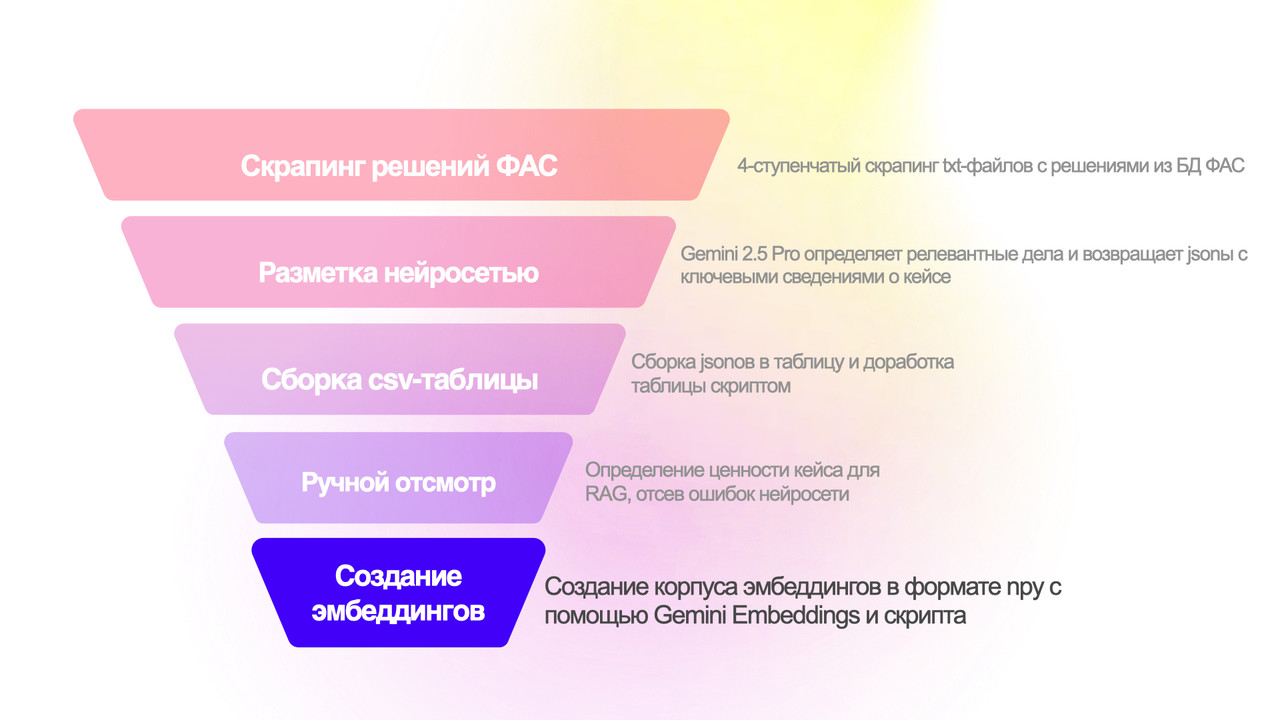
Итак, последний этап — сборка корпуса эмбеддингов. Для того, чтобы лучше понять его суть, рекомендую сначала прочитать мой вводный материал о RAG-технологии everybody talks about RAG.
Этап делится на 2 основных сущностных шага — подготовку «чанков», то есть текстов, которые и будут превращаться в эмбеддинги, и само превращение в эмбеддинги, то есть векторизацию.
Чанки
Обычно под чанками понимаются части документов, имеющие определенную длину (в символах или токенах). Но поскольку я делала RAG для бота по наитию, я не знала, что по классике чанкуются именно тексты. Я пошла по пути изготовления (на этапе разметки) резюме решений нейросетью. И именно резюме отправляются на векторизацию (я схлопываю в один текст содержимое двух колонок из csv-таблицы).
Я и сейчас думаю, что, учитывая характер исходного материала, это правильный путь: УФАС в решениях пишут много не несущих никакой (для моей задачи) ценности заклинаний, повторяют одно и то же, что просто нарезка текста решения на чанки блага не сделает.
Эту операцию скрипт проделывает моментально без моего особого участия.
Эмбеддинги
Далее код пайплайна обращается по API к эмбеддинговой модели (сейчас у Gemini она одна — gemini-embedding-001), по очереди векторизует каждый чанк, и все получившиеся координаты собирает в один файл формата NumPy. Как я пишу в своем лонгриде про RAG, RAGи вполне могут быть реализованы не в виде векторной базы данных, а просто вот таким массивом чисел. Учитывая мой объем (менее 2000 решений, в перспективе не более 3000), этого более, чем достаточно.
Если возникает необходимость корпус эмбеддингов расширить, то имеющиеся векторы не пересчитываются, так как уже обработанные записываются в кэш. Полностью пересчитать пришлось один раз, когда переезжала на другую эбеддинговую модель (на ранее упомянутую, её представили в середине октября).
Я делаю эмбеддинги 768 размерности и использую float64, то есть каждое число в эмбеддинге весит 8 байт: это как бы обеспечивает более высокую точность семантического подбора. Наверное. Я верю на слово всему, что мне говорят нейронки по этому вопросу 🙂
Вот и всё! RAG.csv и корпус эмбеддингов в .npy в паре представляют собой RAG. Коротко напомню, что происходит дальше (или чем занимается код в backend_logic.py):
1️⃣ пользователь вводит в боте запрос или грузит картинку, скрипт обрабатывает текст или описывает текстом картинку;
2️⃣ полученный текст тоже становится эмбеддингом с помощью той же самой эмбеддинговой модели (корпус эмбеддингов и входящие эмбеддинги должны делаться одной и той же моделькой из-за используемых ими таблиц токенизации);
3️⃣ для эмбеддинга запроса косинусным сходством высчитываются топ-10 наиболее похожих эмбеддингов;
4️⃣ топ-10 эмбеддингов откатываются обратно в текст и вставляются в шаблон промпта для нейросети;
5️⃣ нейросеть готовит заключение с учетом того, что нашлось эмбеддинговым поиском, цитирует релевантный кейс в заключении.

И здесь уместно рассказать, что я предпринимаю для повышения точности отбора (a.k.a костыли):
- предобработка креатива — при обработке входящего текста или подготовке описания выкидывается все, что может «зашумить» эмбеддинговый поиск (часы работы, номера телефонов, сайты, всевозможные идентификаторы и т.п.);
- нейросети дается задача критично относиться к тому, что принесено в промпте из RAG, и если действительно релевантного кейса нет, то не обращать на них внимания.
С самого начала у меня появилась идея делать привязку к тематическим тегам для повышения релевантности выдачи, то есть этакий гибрид с фильтром по ключевым словам, который активируется не сразу, а после первого эмбеддингового отбора. Именно это я понимаю для себя как reranking, хотя это не совсем он, и именно это я бы хотела в обозримое время реализовать.
Об организации работы пайплайна
Почему воронка — это воронка? С самого первого парсинга базы ФАС в середине июня до самого последнего в начале ноября мой код сходил в почти 10 тысяч карточек дел, а в базе знаний бота всего 1800+ решений. На каждом этапе воронки что-то отсекается: из-за особенностей ведения базы самой ФАС и моих представление о том, каким должен быть RAG для бота.

Технические особенности пайплайна
Помимо описанных выше этапов и их программной логики, в пайплайне много технических фич, призванных делать пайплайн многоразовым и оптимизированным. В самом конце этой публикации привела перечень ячеек кода и их функций, а здесь немного подробнее расскажу о ранее упоминавшимся механизме «сессий». Из-за того, что я отсматриваю кейсы глазами, мне удобнее строить эту работу по годам. И скрапинг тоже организован по годам. И чтобы не путаться, где какой год уже был проверен и переведен в векторы в рамках многоразового пайплайна, я придумала логику «изоляции запусков» или сессий.
В коде есть переменная CURRENT_SESSION, и при каждом запуске скрапера этой переменной присваивается уникальный ID, который дописывается в JSON, возвращаемый нейросетью после разметки. Таблица, которую я отсматриваю, собирается как раз с учетом этих ID, чтобы в неё не попадало то, что я уже видела. Вся эта история несколько раз ломалась (почему — будет ниже), и мне приходилось дописывать аварийные коды по типу «собери в таблицу всё, что было скачено за последние 4 часа».
Есть и пара толковых механизмов. Например, я упоминала кэширование, чтобы не тратить лишнее время на проходы скрапера и деньги на API-запросы в нейросеть. Кэширование реализовано в виде:
- большого логгера, записывающего все ссылки, по которым скрапер когда-либо ходил;
- логики проверки наличия JSONа с нужным docID (если JSON есть, значит решение уже было размечено);
- специального кэша для корпуса эмбеддингов, чтобы по новой корпус не создавать.
Всё это работает и на отказоустойчивость — если падает соединение с Интернетом или какие-то проблемы на стороне Gemini API. Также из кэширования вырастает логика дополнительного прогона скрапера по тем ссылкам, на которых он был раньше, но не нашёл решения — вдруг решение появилось, и его можно скачать и далее отправить на разметку.
Да как вообще этот пайплайн выглядит, это какая-то программа?
Это ноутбук (файл в формате .ipynb) в среде Jupyter Lab. Это не совсем стандартная среда разработки типа VS Code, в которой делаются приложения, то есть не IDE (Integrated Development Environment). У меня достаточно особый вайб-кодерский путь, и я использую именно ноутбуки.
В ноутбуках код поделен на ячейки, и выполняя каждую ячейку, ты сразу видишь результат ее работы в виде каких-то отчётов о выполнении (формат отчетов также кодится).
Ноутбук в варианте последнего прогона ячеек можно послать кому-то, кто откроет его в своём Юпитере и увидит все те же отчёты (или прямо в нейросети, почти все читают .ipynb). Ноутбуки классно подходят для анализа данных, если вам не нужен непременно какой-то интерфейс (хотя и просто код в разных форматах в Юпитере можно править как в редакторе). И в целом этот формат достаточно неплохо подходит для пайплайна — я убеждена, что это сильно проще, чем делать себе какой-то программный интерфейс. Можно быть достаточно гибкой в том, чтобы быстро добавить «аварийные» ячейки (если с сессиями не задалось) или аналитические (анализ эффективности пайплайна я сделала перед тем, как писать этот пост).
Но! Нюанс использования ноутбука в том, что надо хорошо понимать, какие ячейки с какими у тебя связаны — если не запустишь ячейку с импортами библиотек или активацией API-ключа, то другая нужная ячейка не заработает. Сколько раз я об это спотыкалась… А если Юпитер вылетел посреди скрапинга, то вылетает и вся история с сессиями, потому что переменная CURRENT_SESSION живет только в памяти. Чем больше ячеек — тем более тормозной ноутбук. И всё в таком духе.
Что еще можно было бы исправить и добавить?
За несколько месяцев работы по наполнению базы у меня несколько раз менялись параметры разметки и скриптованных добавлений в JSONы, которые возвращает нейросеть. Пару раз менялся промпт для разметки. И, собирая датасет с практикой ФАС по рекламным делам, я споткнулась на том, что JSONы получились неоднородные, и их нужно было дополнительно нормализовывать и унифицировать, делая дополнительные API-прогоны через нейросеть.
То есть для текущей версии пайплайна напрашивается какой-то механизм версионирования промпта и унификации всех json-ов. И вообще, кажется, нужно ветвить пайплайн на работу ещё и с датасетом, ведь его тоже нужно будет пополнять и дальше.
На этом всё! Спасибо всем, кто читал об этой моей работе. Для меня она оказалась одной из самых интересных в рамках всего проекта. И пусть процесс и неидеален, опыт получился совершенно бесценный.
______________
Описание ячеек кода пайплайна:
Cell 1 (Config): Загружает библиотеки, настраивает пути к папкам и авторизует в Google API. Автоматически ищет API-ключ в файле окружения .env, а если не находит — просит ввести вручную.
Cell 2 (Period): Принимает от пользователя диапазон дат для скрапинга и генерирует уникальный ID сессии, который потом прописывается во все файлы для трекинга.
Cell 3 (Functions): Содержит логику парсинга сайта ФАС и осмотра страниц. Использует список разных поисковых запросов (4 фильтра), чтобы найти максимум документов, которые могут не попасться в одном общем списке.
Cell 4 (Scraping): Запускает скачивание метаданных и текстов решений, обновляя главный лог. Умная проверка обновлений — смотрит, не появились ли решения в уже просмотренных ранее делах.
Cell 5 (Prompt): Хранит огромный системный промпт для LLM с инструкциями по анализу для разметки. Жесткое требование вывода в JSON с флагом value_score, фильтрующим нерелевантные дела.
Cell 6 (Gemini Processing): Отправляет тексты в Gemini API и сохраняет ответы в JSON. Реализована сложная система повторных попыток (retries) и жесткие таймауты через signal, чтобы процесс не зависал.
Cell 6.5 (Session Analysis): Строит воронку потерь для текущего запуска (сколько скачали -> сколько обработали). Показывает процент потерь на каждом этапе, помогая понять, виноват сайт ФАС или API Gemini.
Cell 7 (Results Assembly): Собирает разрозненные JSON-файлы текущей сессии в единую CSV-таблицу. Автоматически превращает номера статей закона (из JSON) в понятные тематические теги (из справочника).
Cell 7C (Rebuild Session): Позволяет пересобрать таблицу RAG для любой прошлой сессии. Сканирует метаданные всех JSON-файлов и предлагает меню выбора доступных прошлых запусков.
Cell 7.5 (Tags Check): Проверяет, для каких статей закона не нашлось описания в справочнике тегов. Выводит список «сирот», помогая дообучать систему тегирования вручную.
Cell 8 (Embeddings): Создает векторные представления (эмбеддинги) для готовой таблицы. Сохраняет векторы сразу в трех форматах (float64, 32, 16) для баланса между точностью и размером памяти.
Cell 8a (Re-embedding): Полностью пересоздает базу векторов с нуля. Фишка: Делает автоматический бэкап старых файлов перед перезаписью.
Cell 9 (Search Test): Тестирует работу RAG, выполняя семантический поиск по запросу. Выводит не только текст, но и коэффициент сходства (cosine similarity), показывая уверенность модели.
Cell 10 (Stats): Выводит итоговый отчет по количеству файлов в системе. Показывает реальные размеры файлов эмбеддингов в мегабайтах.
Cell 11 (Trash Analysis): Собирает все дела, которые нейросеть посчитала нерелввантными для RAG (value_score=0). Позволяет проверить, не выкидывает ли нейросеть важные дела по ошибке.
Cell 12 (Diagnostics): Глубокая отладка проблем с потерей сессий. Использует анализ времени создания файлов (ctime) как запасной вариант, если метаданные ID сессии были утеряны.
Cell 13 (Global Funnel): Считает общую эффективность пайплайна за всё время. Показывает финальный КПД системы (процент ссылок, ставших знаниями).