everybody talks about RAG
Ekaterina Yakunenko, канал @delay_RAGЯ уже больше трёх месяцев время веду Telegram-канал с названием «Делай RAG», в нём есть даже целая серия постов c одноимённым хэштегом о моём непосредственном опыте создания небольшой RAG-системы для бота-проверщика рекламы. Но всё ещё не было ни одного базового установочного поста о сути технологии. Пришло время это исправить!

RAG, Retrieval-Augmented Generation, или, как это часто переводится на русский, — «генерация, дополненная поиском». Генерацией занимается LLM, промпт для которой дополнен (или аугментирован, augmented) результатом поиска (ретривинга, retrieval) из внешней, заранее подготовленной базы знаний.
Впервые этот термин представила команда исследователей в 2020-м году на конференции NeurIPS 2020 в материале Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. У языковых моделей есть «параметрическая» память, то есть то, что «осело» в ней во время обучения, и часто это бывают не совсем достоверные или устаревшие факты, приводящие к пресловутым галлюцинациям. RAG позволяет нейросети получать актуальные и проверенные знания через поиск по заранее заготовленному индексу документов, что делает эту технологию очень многообещающей, например, для юристов.
Мне когда-то рассказали классное сравнение: студент мог ходить на пары весь год, слушать преподавателя, прийти на экзамен и рассказывать на экзамене материал из головы. В таких ответах может быть масса неточностей, но в зависимости от талантов и подвешенности языка экзаменуемого может и «прокатить». Но если этому студенту разрешить на экзамен взять конспекты лекций, которые вели его одногруппники-отличники, то ответ, скорее всего, будет очень хорошим.
У технологии в сущности два компонента: база знаний и логика (или техника) поиска. Я знаю, что есть мнения о том, что «база знаний» — это необязательный момент, что grounding with web-search уже может считаться RAG. Но участвовать в битве за терминологическую чистоту не вижу здесь смысла, тем более, что в этой колонке мы сфокусируемся на поиске.
Поиск может быть реализован разными способами: классический по ключевым словам (BM25), графом знаний, с помощью SQL-баз, эмбеддингами, разными гибридными ансамблями из вышеперечисленных. Эмбеддинговый или векторный поиск — самый популярный, и именно он стал ассоциироваться с RAG.
Да кто такие эти ваши эмбеддинги?
Эмбеддинг — это тип представлений (representations) естественного языка в понятные для программ сущности.
Эмбеддинг — это вектор в многомерном пространстве, а точнее, это последовательность чисел, которая определяет координаты текста на естественном языке в этом многомерном пространстве.
Мы со школы хорошо представляем себе, как выглядит трёхмерная система координат, чертили в ней разные фигуры на уроках геометрии. Попробуйте включить фантазию и представить себе 768-мерное пространство: текст, превращенный в эмбеддинг, будет некоторой точкой в нём, и у этой точки будет координата, состоящая из 768 чисел.
Поправлюсь сразу — называть эмбеддинг точкой некорректно. Это именно вектор: точка — это просто статичная позиция в пространстве, а вектор — это направление относительно других векторов. 768-значной координатой обозначается место в пространстве, в которое вектор «приходит» (дальше будет картинка, где будет понятнее!). Сонаправленность векторов критична при определении семантической (смысловой) близости текстов.
Поиск семантических связей
Самым распространённым способом определения семантической близости между векторами является подсчет косинусного сходства, то есть косинуса угла между векторами («начала» векторов мысленно совмещаются, координаты образуют угол, вычисляется косинус получившегося угла). Получается число от -1 до 1, и чем оно выше, тем выше семантическое сходство между эмбеддингами.
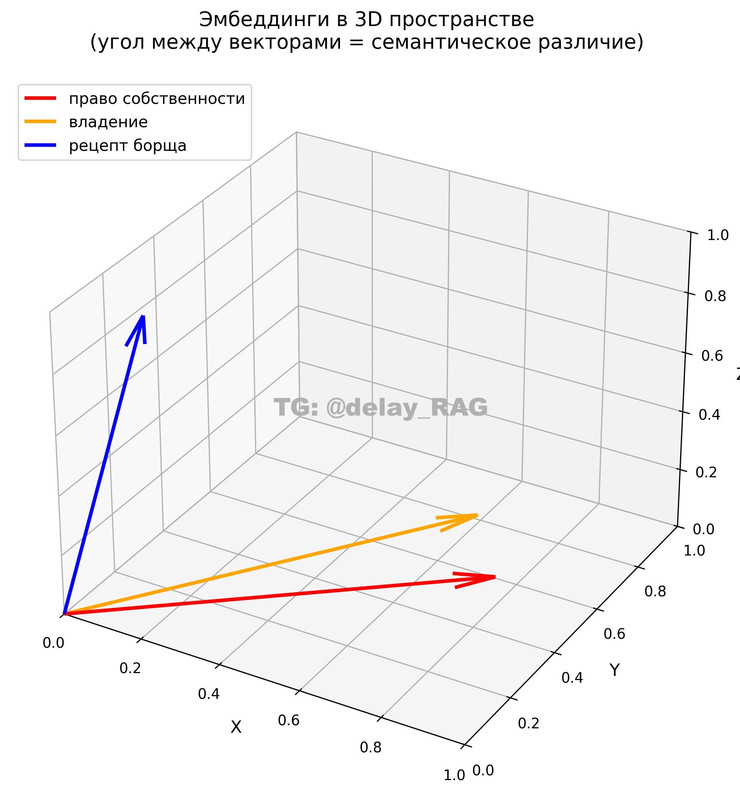
На этом изображении мы видим три эмбеддинга — упрощённо «схлопнутые» до трёхмерного пространства и для удобства визуализации выходящие из начала системы координат. Координаты вектора для «права собственности» = [0.8, 0.5, 0.1], для «владение» = [0.7, 0.6, 0.2], для «рецепта борща» = [0.1, 0.2, 0.9].
Косинусное сходство между ними:
- «право собственности» ↔ «владение»: 0.983 — очень высокий результат
- «право собственности» ↔ «рецепт борща": 0.307
- «владение» ↔ «рецепт борща»: 0.423
Юридические термины из одного тематического пула образуют острый угол, а с борщом у них угол почти 90° — они перпендикулярны, практически не связаны по смыслу.
Косинусное сходство — не единственный способ подсчёта близости эмбеддингов, хоть и самый популярный (именно его просят использовать в документации большинства эмбеддинговых моделей). Другие способы предлагаю даже не обсуждать — это, конечно, не rocket science, но вполне высшая математика.
Размерность
Выше я упомянула 768-мерное пространство. Эмбеддинги могут существовать в пространствах с разным количеством измерений и иметь соответствующее количество чисел в своей координате. Эта характеристика называется размерностью эмбеддинга, и 768 — это наиболее распространённая размерность, неплохо подходящая для юридических задач.
Другие типичные размерности — 312, 1024, 1536, но есть и больше. Больше, в принципе, не значит лучше: линейного влияния размерности на качество нет (хотя это позволяет улавливать больше смысловых нюансов). Качество в большей степени зависит от того, насколько хорошо обучена используемая вами эмбеддинговая модель. Мои личные недавние эксперименты показывают, что на достаточно простых небольших русскоязычных базах модели размерности 256 дают абсолютно сопоставимый результат с 768. При этом они быстрее производят вычисления и требуют совсем немного места в памяти для хранения эмбеддингов. Но всё же 768 — это золотой стандарт, балансирующий между качеством и производительностью, оптимальный для большинства юридических задач и текстов.
Хранение
Где, собственно, лежат эмбеддинги? Я часто вижу ассоциацию, что RAG = векторная база данных. Ещё работая над своим ботом, я поняла, что это совсем не так: мой RAG для бота хранится в формате NumPy, то есть в массиве чисел. Грубо говоря, это просто файл с перечислением координат-последовательностей, который обрабатывается специальной библиотекой Numerical Python для языка программирования Python. Если в вашей базе до 50 тысяч документов, и не требуются непрерывные вычислительные операции, то NumPy более чем достаточно.
Но есть нюанс: когда вы загружаете какой-то текст, для которого нужно найти самые близкие эмбеддинги из вашей базы, то косинусное сходство подсчитывается между ним и всеми векторами в базе по очереди. И для оптимизации этого процесса и быстрого поиска по векторам и существуют векторные базы. Оптимизация актуальна, если в вашей базе десятки и сотни тысяч документов, она постоянно обновляется, и в неё на постоянной основе поступают многочисленные и одновременные запросы. Базы построены по другой логике, они дополнительно индексируют векторы и ориентируются в них графовым методом, обеспечивая быстрое вычисление (и иногда требуют хороших вычислительных мощностей). Есть и некоторые промежуточные техники между этими двумя основными способами.
Создание
Чтобы где-то эмбеддинги хранить, их хорошо бы сначала откуда-то взять. В основном они создаются с помощью эмбеддинговых нейросетей — их огромное количество и от крупных вендоров, и от индивидуальных разработчиков, оптимизированных под какие угодно языки и типы текстов.
Эмбеддинговые модели — это не LLM, хотя и те, и другие используют архитектуру transformer и обучаются на текстовых корпусах. До массового распространения трансформерных нейросетей существовали и другие методы создания эмбеддингов — более простыми нейросетями или чисто алгебраические. Вообще важно отметить, что эмбеддинги придумали вовсе не для RAG-систем, это давно существующая фундаментальная NLP-технология, на которой завязаны поисковые и рекомендательные системы (например, в стриминговых сервисах), машинный перевод, антиплагиат, различная маркетинговая аналитика.
Эмбеддинговая нейросеть работает следующим образом:
- Токенизация: текст разбивается на токены (части слов или слова). «Недействительный договор» → [не], [действ], [ительный], [договор]. Каждому токену соответствует начальный вектор из таблицы. Каждая эмбеддинговая модель имеет собственную таблицу — это большая матрица, где каждой строке соответствует токен из словаря модели. Поэтому корпус эмбеддингов должен быть создан той же эмбеддинговой моделью, что обрабатывает пользовательский запрос.
- Контекстуализация: это процесс, когда каждый токен «смотрит» на все остальные токены через механизм внимания (attention) и обновляет свой вектор с учётом окружения: например, слово «лист» получает разные векторы в контекстах «лист бумаги» и «осенний лист».
- Многослойная контекстуализация: архитектура transformer содержит 12-24 слоя. На этом этапе контекстуализация последовательно применяется 12-24 раза, где каждый слой углубляет понимание: первые слои улавливают грамматику (что с чем согласуется), средние — роли слов (кто делает, что делают), последние — абстрактный смысл всей фразы. То есть на каждом слое берётся результат предыдущего слоя и проводится новый раунд контекстуализации.
- Сборка итогового эмбеддинга: превращение множества векторов (по одному на каждый токен) в один вектор для всего текста запроса. Есть два основных метода сборки: mean pooling (усредняет все векторы токенов (складывает и делит на количество)) и max pooling (берёт максимальное значение по каждому измерению из всех векторов, что выделяет наиболее выраженные признаки). То есть mean помогает составить «общее впечатление», а max — выделить «самые яркие черты» текста.
Для иллюстрации можно взять стандартную договорную формулировку «Договор считается расторгнутым», вот как будет выглядеть её превращение в эмбеддинг:
- Токенизация: [Договор], [счита], [ется], [растор], [гнутым]
- Начальные векторы: Каждый из 5 токенов получает по таблице размерности 768 собственный начальный вектор
- Attention и контекстуализация: Токены [растор] [гнутым] обращают внимание на [Договор]
- 12 слоёв обработки: По каждому токену уточняется и углубляется понимание юридического смысла
- Итоговый вектор: 768 чисел, располагающих фразу в 768-мерной системе координат
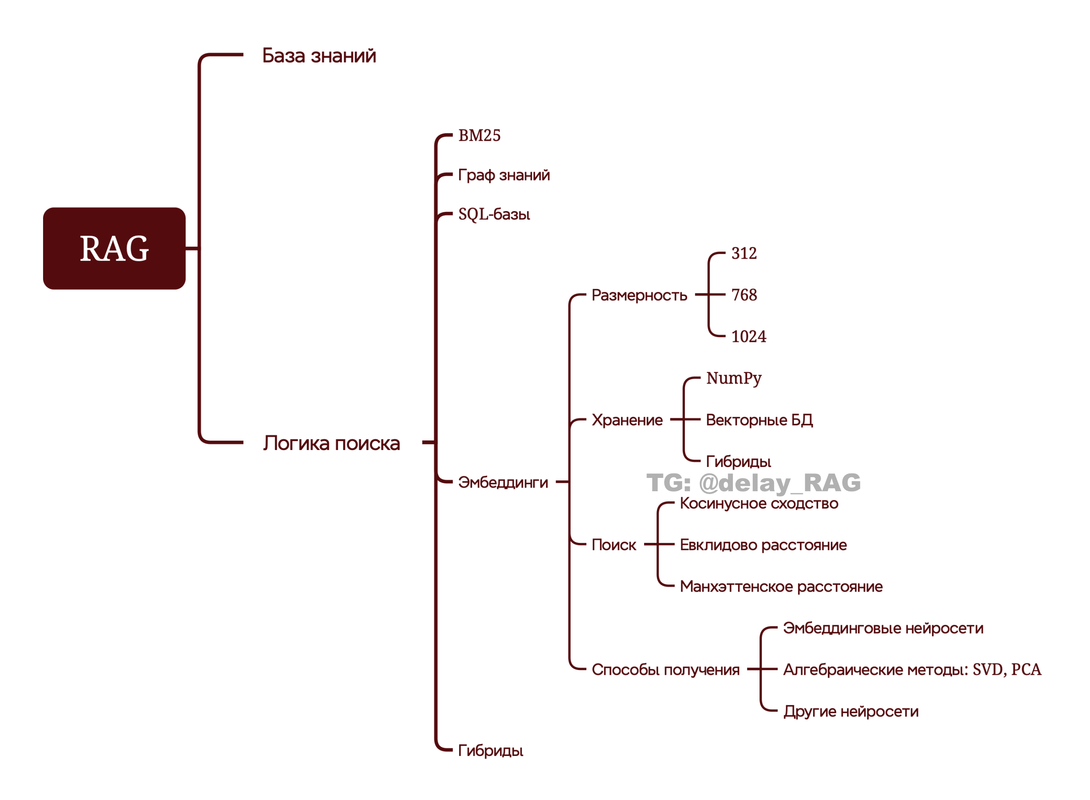
Если суммировать всё вышеописанное, то получается вот такая базовая майндкарта (её при желании можно ветвить и дальше):
Лирическое и практическое
Есть несколько теорий, почему создание эмбеддингов позволяет перенести заложенный людьми смысл в числовое представление, при том, что единого убедительного объяснения нет. Я скопирую ответ Claude на эту тему:

Учитывая, что фразы на разных языках превращаются в близкие эмбеддинги (видела это воочию!), и семантическая близость сохраняется даже при мультимодальности источников (то есть, например, вектор картинки и вектор текста, описывающего картинку), лично мне ничего не остаётся, кроме как смотреть на это как на необъяснимое чудо.
С другой стороны, когда начинаешь делать RAG-системы, розовые очки надолго не задерживаются: у технологии немало фундаментальных ограничений.
Эмбеддинги могут плохо улавливать отрицания («действителен» и «недействителен» могут оказаться слишком близко), теряют точные формулировки и цитаты при векторизации, не улавливают иронию и подтекст. Эмбеддинги страдают от так называемого семантического дрейфа — близость векторов не всегда означает истинную смысловую близость, особенно для специализированной терминологии.
Для юридических RAG-систем эти ограничения могут быть критичными из-за особой важности точности формулировок и тонких теоретических и выработанных практикой различий. Эмбеддинги плохо различают модальность («должен», «может», «вправе»), игнорируют структуру юридических документов — иерархию норм, кросс-референсы, соотношение общих и специальных норм. Это не непреодолимые проблемы: прямо сейчас различные команды исследователей вырабатывают техники повышения точности поиска, о чём можно почитать в моих статьях из цикла «Rise of RAG»: первая и вторая.
Но, кажется, здесь уместно небольшое напоминание: юрист может быть вооружён самой сильной нейросетью и самым высокоточным и сложнейшим RAGом, уметь писать самые убойные промпты и управлять контекстным окном лучше Сэма Альтмана. Но если что-то пойдёт не так, то объясняться с работодателем и клиентом всё равно юристу. Вывод каждый читатель сделает свой :)