سفر به آینده
@Chekide_haبرای گرفتن هر تصمیمی، تجربههای گذشتهی ما که در وجود ما ذخیره شدهاند و نیز وضعیت کنونیمان (مثلاً اینکه از خود بپرسیم آیا میتوانم بهجای مورد الف، ب را بخرم یا میتوانم ج را انتخاب کنم؟) دخالت دارند. اما در بحث چگونگی تصمیمگیری، موضوع دیگری نیز مطرح است: پیشبینی آینده.
در قلمرو زندگی جانوری، هر موجودی بهدنبال کسب پاداش است. پاداش چیست؟ پاداش عبارت است از هر چیزی که جسم را به نقطهی تنظیم آرمانی خود نزدیکتر کند. وقتی جسم دچار کمبود آب میشود، آب پاداش است. وقتی ذخیرهی انرژی در حال اتمام باشد، غذا پاداش است. آب و غذا پاداشهای اولیه هستند و بهطور مستقیم به نیازهای زیستی ما اشاره میکنند. اما بهطور شایعتر رفتارهای انسانی ما تابع پاداشهای ثانویهاند، چیزهایی که پاداشهای اولیه بهدنبال آنها بهوجود میآیند. مثلاً دیدن منظرهی یک آبسردکن برای مغز چندان اهمیتی ندارد اما چون ما را یاد فوارهی آب میاندازد، چنانچه تشنه باشیم، مشاهدهی آن برای ما ارزشمند خواهد بود. در مورد انسانها حتی مفاهیم انتراعی نیز میتوانند با پاداش همراه باشند، مثل این احساس که در جامعه برای ما ارزش قائل هستند. و ما برخلاف حیوانات، حتی قادریم اینگونه پاداشها را بر نیازهای زیستی خود مقدم بدانیم. بنابر گفتهی رید مونتگیو «کوسهماهیها هیچوقت دست به اعتصاب غذا نمیزنند.» حیوانات فقط بهدنبال ارضای نیازهای پایهای خود هستند. حال آنکه انسانها از این محدوده پا فراتر میگذارند و به آرمانهای انتزاعی خود بهای بیشتری میدهند. پس وقتی ما در برابر امکانهای متنوعی قرار میگیریم، دادههای درونی و بیرونی را با هم جمع میکنیم تا بتوانیم به حداکثر پاداشی که برای ما بهی نوان فرد قابل تعریف است، دست پیدا کنیم.
چالشی که در مورد هر پاداش، اعم از پاداش انتزاعی یا پایهای وجود دارد، این است که معمولاً نتایج انتخابهای ما فوری آشکار نمیشوند. ما تقریباً همیشه مجبوریم تصمیمهایی بگیریم که در آنها بهدنبال انجامدادن رشتهای از کارها در آینده پاداشهایی به بار میآیند. مثلاً سالها به مدرسه میرویم تا در آینده به مدرک تحصیلی باارزشی دست یابیم. سالها مثل برده کاری را که دوست نداریم انجام میدهیم به این امید که ارتقاء پیدا کنیم. تمرینهای سخت را انجام میدهیم تا به سطح مناسبی از آمادگی جسمانی برسیم.
مقایسهی گزینههای مختلف، بدان معنی است که برای هریک از آنها در اوضاع جاری براساس پیشبینی ارزش خاصی در نظر میگیریم و سپس گزینهای را که دارای بیشترین ارزش است انتخاب میکنیم. به این داستان توجه کنید: فرض کنید کمی وقت آزاد دارم و میخواهم تصمیم بگیرم چه کنم. لازم است به بقالی بروم اما درعینحال دوست دارم به کافی شاپ بروم. از طرفی باید به آزمایشگاه بروم و تحقیق کنم، چون زمان تحویل کار نزدیک است. همینطور دلم میخواهد وقتم را با پسرم در پارک بگذرانم. چگونه باید از این فهرست یکی را انتخاب کنم؟
البته اگر بتوانم در عمل هریک از این کارها را انجام دهم و پاداش مربوط به آنها را نیز دریافت کنم، بر اساس نتایج بهدستآمده، انتخاب بین آنها، کار سادهای خواهد بود. اما متأسفانه سفر به آینده ممکن نیست.
یا شاید هم باشد؟

سفر به آینده، کاری است که مغز انسان پیوسته در حال انجامدادن آن است. وقتی داریم تصمیمی میگیریم، مغز ما با شبیهسازی، سرانجامهای مختلفی را که هریک تقلیدی از آینده هستند مجسم میکند. ما میتوانیم در ذهن خود از حال فاصله بگیریم و به جهانی که هنوز وجود ندارد سفر کنیم.
شبیهسازی یک سناریو در ذهن، تنها قدم اول است. برای آنکه بین سناریوهای مختلف یکی را انتخاب کنیم، باید بتوانیم پاداشی را که از هریک عاید ما میشود تخمین بزنیم. وقتی یادم میافتد آشپزخانهام پر از جنس و مرتب است و چیز زائدی در آن نیست، احساس رضایت میکنم. تازه اگر به بقالی نروم میتوانم بهکار آزمایشگاهم برسم و هم بابت آن پول بگیرم و هم تشویق استاد نصیبم شود و هم از بابت پیشرفت شغلیام خرسند شوم. اما فکر اینکه با پسرم به پارک بروم سبب بروز شور و شادی و حس پاداش برخاسته از صمیمیت خانوادگی میشود. تصمیم نهایی من به این بستگی دارد که در شرایط موجودِ سامانهی پاداش ذهن من، کدام آینده پذیرفتنیتر باشد. انتخاب کار آسانی نیست، چون همهی این ارزشگذاریها با تفاوتهای جزئی همراه هستند: شبیهسازی ذهنی رفتن به بقالی با حس ملال توام است. نوشتن طرح برای کسب بودجهی تحقیق مایهی ایجاد حس بیهودگی و بیزاری است. رفتن به پارک با حس گناه برخاسته از انجامندادن کاری مفید همراه است. مغز تحت پوشش رادار خودآگاهی، همهی این گزینهها را یکبهیک شبیهسازی میکند و برآوردی کلی از هریک ارائه میدهد و بدینگونه است که تصمیم نهایی را میگیرد.
چگونه میتوانم این آیندههای فرضی را بهطور دقیق شبیهسازی کنم؟ چگونه میتوانم سرانجام هریک از این حالات را پیشبینی کنم؟ پاسخ این است که این کار شدنی نیست. هیچ راهی وجود ندارد که بر اساس آن بهطور قطعی پایان هر انتخاب را بدانم. شبیهسازی من بر اساس تجربههای قبلی و مدلهای کنونی من برای نحوهی گردش امور در دنیاست. ما نمیتوانیم مانند حیوانات فقط دور خود بگردیم و امیدوار هم باشیم بخت ما را به پاداش برساند. کار مهم مغز این است که بتواند پیشبینی کند. برای آنکه مغز کارش را خوب انجام دهد، باید بهطور پیوسته از همهی تجربههای خود برای بهتر شناختن جهان استفاده کنیم. بنابراین، در این مورد خاص، من براساس تجربههای گذشتهی خود، به هریک از گزینههای موجود بهایی میدهم. با استفاده از استودیوهای هالیوودی ذهنم به آینده سفر میکنم تا ببینم هریک از انتخابهای من در آینده چه ارزشی خواهند داشت و بهاینترتیب، تصمیم میگیرم. آیندههای فرضی را با هم مقایسه میکنم و گزینههای رقیب را به ارز رایجی که همان پاداش در آینده باشد تبدیل میکنم.
ارزش پاداشی که من برای هر گزینه پیشبینی میکنم، نوعی برآورد درونی است که نشان میدهد هر انتخابی تا چه حد میتواند در آینده خوب از آب درآید. خرید از بقالی میتواند غذای مورد نیاز مرا تأمین کند: پس به آن ۱۰ امتیاز میدهم. نوشتن برای گرفتن بودجهی پروژهی تحقیقی کار دشواری است، اما در حرفهی من انجام این کار واجب است: پس به آن ۲۵ امتیاز میدهم. گذراندن وقت با پسرم را دوست دارم: پس برای رفتن به پارک همراه پسرم ۵۰ امتیاز میدهم.
اما در اینجا با مسئلهی ظریفی مواجهیم: جهان بسیار پیچیده است و تخمینهایی که در ذهن خود انجام میدهیم با جوهر ثابت و دایمی نوشته نمیشوند. ارزشگذاریهای ما دربارهی مسائل پیرامونی، پیوسته در حال تغییرند. چراکه در بسیاری از موارد، پیشبینیهای ما با آنچه که در عمل اتفاق میافتند متناسب نیستند. کلید یادگیری مؤثر، به حساب آوردن این خطاهای پیشبینی (Prediction error) است: یعنی تفاوت بین سرانجام پیشبینیشدهی یک انتخاب با سرانجامی که در عمل روی میدهد.
در مثالی که زدم، پیشبینی ذهنم این بود که رفتن به پارک با بیشترین میزان پاداش همراه است. اگر میتوانستم در پارک دوستان خود را نیز ببینم، وضع باز هم بهتر میشد. حتی شاید این اتفاق باعث میشد دفعهی بعد برای رفتن به پارک امتیاز بالاتری در نظر بگیرم. اما اگر در عمل میدیدم تابهای پارک شکستهاند و باران هم میبارد، بار دیگر برای رفتن به پارک امتیاز کمتری قائل میشدم.
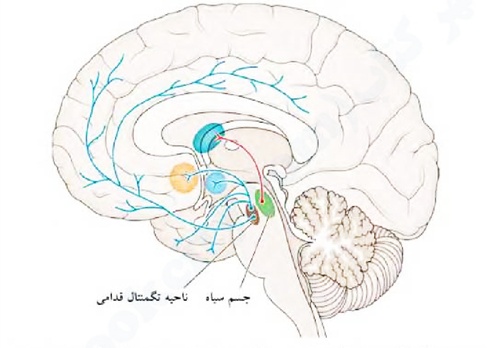
طرز کار این سامانه چگونه است؟ سامانهای کهن و بسیار کوچک در مغز وجود دارد که کارش بهروزکردن ارزیابی ما از جهان است. این سامانه از گروههای سلولی کوچکی واقع در مغز میانی تشکیل شده که پیامهای خود را با نوروترنسمیتری به نام دوپامین انتقال میدهند.
وقتی بین پیشبینی ما و رویداد واقعی ناهمخوانی وجود داشته باشد، سامانهی دوپامینی مغز میانی سیگنالی میفرستد که بر اساس آن جدول ارزشگذاری مجدداً تنظیم شود. این سیگنال به باقی قسمتهای سامانه اعلام میکند که آیا اوضاع بهتر از حد پیشبینیشده خواهد بود (افزایش دوپامین) یا بدتر (کاهش دوپامین). سیگنال خطای پیشبینی به بقیهی قسمتهای مغز اجازه میدهد پیشبینیهای خود را با آنچه که دفعهی بعد در واقعیت میتواند روی دهد نزدیکتر کنند. دوپامین مانند یک اصلاحکننده خطاهای ما عمل میکند و نوعی برآوردکنندهی شیمیایی است که همیشه در جهت بهروزکردن پیشبینیهای ما عمل میکند. بنابراین، ما میتوانیم بر اساس حدسهای بهینهای که دربارهی آینده داریم، تصمیمهای خود را بهترتیب اولویت، طبقهبندی کنیم.
اصولاً هدف مغز، کشف عواقب نامنتظره است - و این حساسیت، اساس توانایی حیوانات برای سازگاری و یادگیری است، پس تعجبی ندارد که معماری مغز در زمینهی یادگیری از راه تجربه، در همهی گونههای جانوری از زنبورعسل گرفته تا انسان یکی باشد. این نکته نشان میدهد که مغز با اصل بنیادی یادگیری از راه پاداش از مدتها پیش آشنا بوده است.