Абстрактные войны: public interface против абстракции
AlekseyПочти 30 лет назад в классической книжке по шаблонам проектирования (Design Patterns: Elements of Reusable Object-Oriented Software), авторы сформулировали один из самых известных, но недопонятых принципов в истории программирования:
Program to an interface, not an implementation.
В чём суть принципа? Зачем "программировать в интерфейсы"? Для того, чтобы реализацию этого интерфейса можно было менять без изменений клиентского кода.
Однако, далее авторы объясняют как следовать этому совету:
Don't declare variables to be instances of particular concrete classes. Instead, commit only to an interface defined by an abstract class.
Многие воспринимают это буквально и просто вносят в программу дополнительную сущность (интерфейс или абстрактный класс), которая дублирует список методов одного конкретного класса.
Проблема в том, что использование ключевого слова abstract или interface само по себе, не создаёт интерфейса и не защищает клиента от изменения реализации.
Давайте рассмотрим на примере вымышленной истории, почему использование ключевого слова interface не является ни достаточным, ни необходимым "для снижения зависимости реализации между подсистемами".
Эпизод первый: интерфейсы. Скрытая угроза
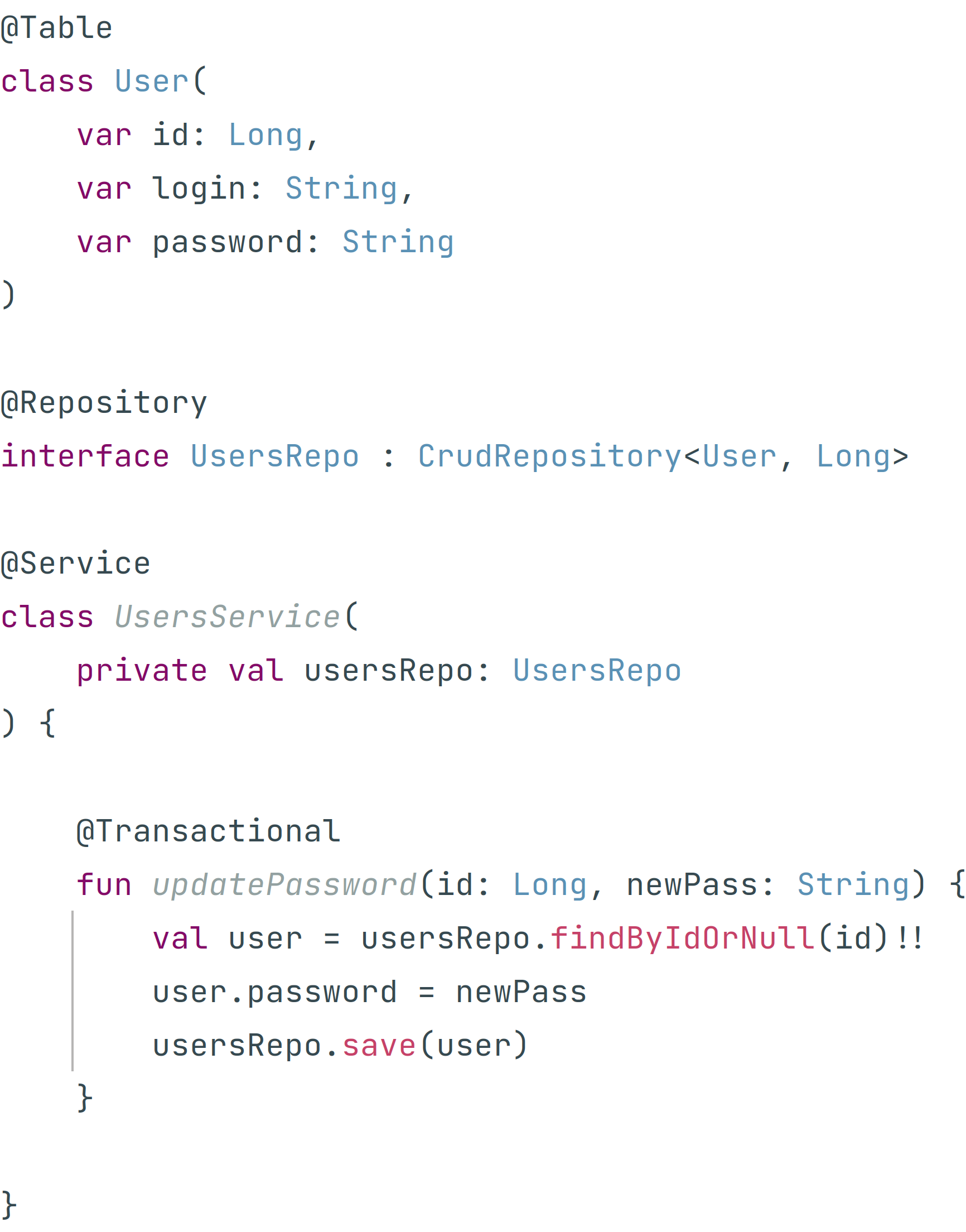
Представим, что некий молодой архитектор Артемий начинает новый проект. Так как ему необходимо минимизировать "time to market", он решает, что собрать на коленке прототип будет быстрее всего на базе JPA. Но он будет "программировать в интерфейсы", чтобы быстро всё переписать на более поддерживаемую технологию, если проект стрельнет.
Артемий пишет примерно такой код:

Казалось бы всё восхитительно - мы не завязываемся ни на какие детали реализации и в любой момент сможем сменить технологию работы с БД.
И, когда наше приложение перерастает штанишки прототипа, и Артемий решает перейти на Spring Data JDBC, он просто меняет зависимость в скрипте сборки, делает замену по проекту "@Entity" на "@Table" и... О чудо! Всё собирается! И тесты проходят!
Однако, после поспешного релиза в прод выясняется, что ничего не работает. Точнее в режиме чтения приложение работает, а вот никакие модификации не сохраняются. После суток судорожного дебага с лежащим продом, Артемий в доках к Spring Data JDBC выясняет, что она не реализует такую "небольшую деталь" как Dirty Checking и автомагически ничего не сохраняет. Тогда Артемий везде добавляет *Repo.save() и всё, кризис преодолён.
Так на своём горьком опыте Артемий узнал, что использование интерфейсов не гарантирует безопасне изменение реализации.
Почему тесты прошли, спросите вы? Потому что Артемий был сторонником Лондонской школы тестирования - он замокал репозитории в тестах сервисов .
Когда проект ещё подрос, и возникла потребность в реактивном подходе, Артемий уже понимал, что переход на Spring Data R2DBC будет долгим и тяжёлым. Так Артемий узнал, что подлинные абстракции открываются, а не изобретаются (Unit Testing PPP).
Осознав, насколько кодовая база заточена на синхронную работу, вместо миграции проекта на Spring Data R2DBC, Артемий решил сам смигрировать на новый проект.
Эпизод второй: абстракции. Пробуждение силы
Наученный горьким опытом, Артемий понял, что "программирование в интерфейсы" само по себе ничего не даёт в плане гибкости. Зато интерфейсы занимают место на экране, диске и в голове Артемия. А так же увеличивают время компиляции проекта. И усложняют навигацию по коду и его рефакторинг.
Поэтому в новом проекте Артемий решил программировать без лишний церемоний, зато с учётом всего своего опыта. На этот раз Артемий отложил выбор технологии для работы с БД и начал с тривиальных suspend-репозиториев на базе ассоциативных массивов:
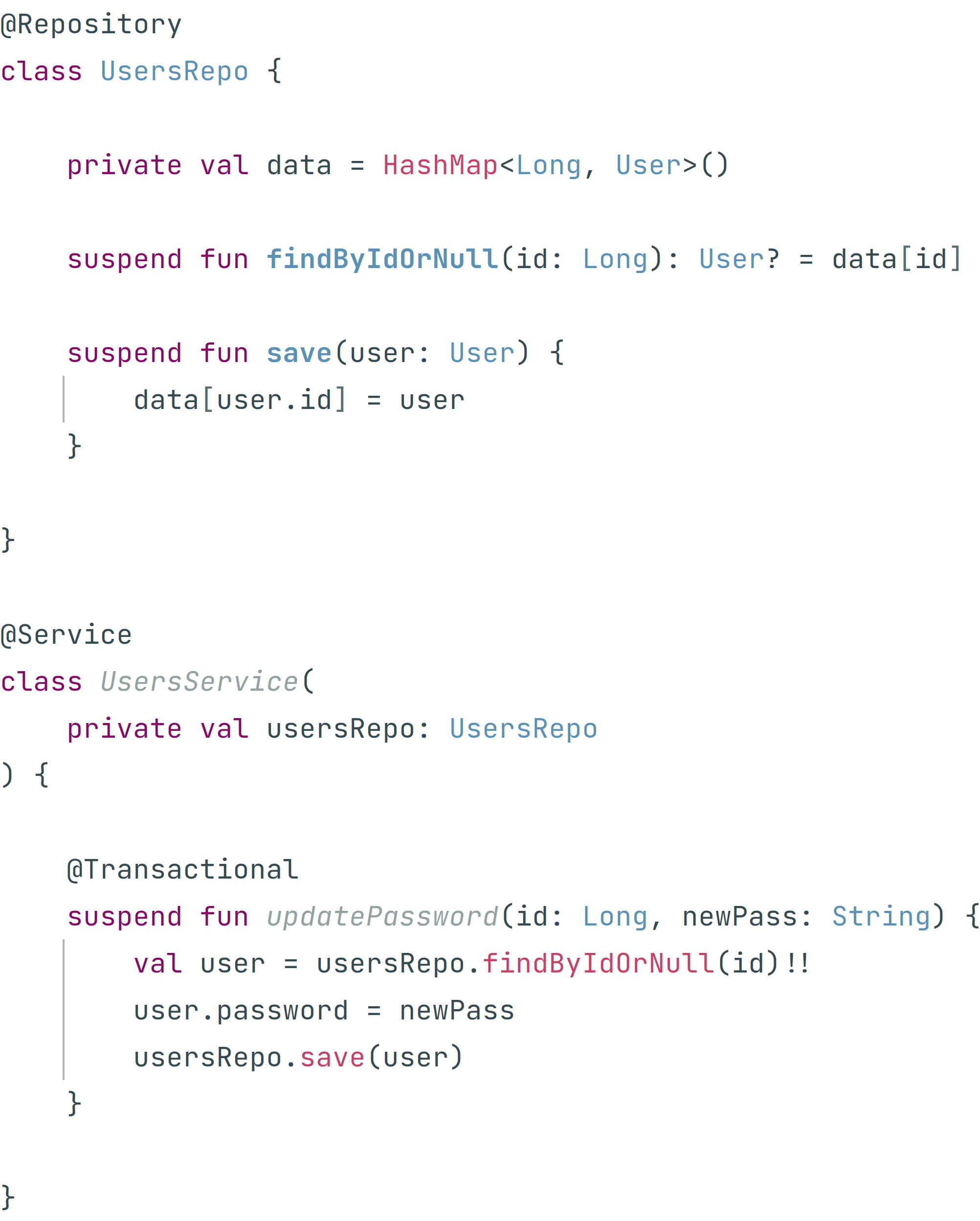
Начав работать в таком стиле Артемий каждый день радовался как ребёнок тому, что теперь не приходится постоянно возиться с чёртовыми прицепами в виде интерфейсов.
Однако, когда пришёл день Д - день выбора технологии работы с БД - Артемий по старой памяти напрягся. У нового проекта не ожидалось большого количества пользователей, поэтому Артемий решил использовать Spring Data JDBC.
Кроме того, имеющиеся in-memory репозитории решили сохранить для триальной версии. Вот бы у нас сервисы зависели от интерфейсов, чтобы мы могли в рантайме подменять реализацию репозиториев.
Я думаю примерно так думали парни из JetBrains когда делали рефакторинг extract interface. Для которого в Котлине ещё нет галки "use interface where possible"🤦♂️. Но всё равно можно вытащить интерфейс, а потом без рефакторинга просто поменять местами имена интерфейса и класса, а уже потом рефакторингом назвать их как надо.
Тут опытный читатель скажет "А если я программирую библиотеку/фреймворк и мне надо чтобы клиенты могли подключать собственные реализации репозиториев?". На что я ему отвечу "Вот тогда вам нужны интерфейсы". Но это должны быть тщательно спроектированные интерфейсы, а клиенты этих интерфейсов должны изо всех сил стараться незавязываться на реализацию по умолчанию.
Следующая проблема - Артемий перестраховался и везде добавил suspend, который стал лишним. Хорошо, что ломать не строить. Можно воспользоваться структурной заменой для поиска всех suspend-методов в классах заканчивающихся на Repo и удаления из них модификатора suspend:
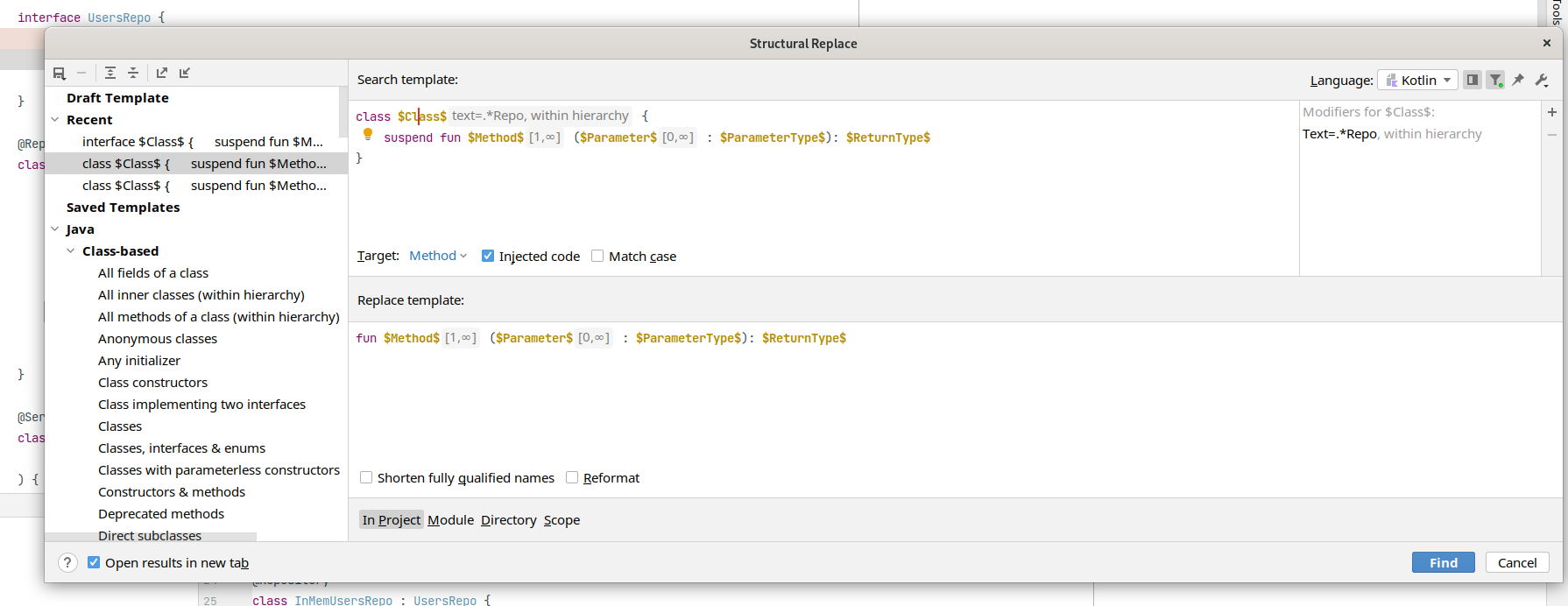
Потом то же проделать для интерфейсов. Или вообще сначала убрать suspend, а потом выделить интерфейс. В итоге у Артемия получился такой код:
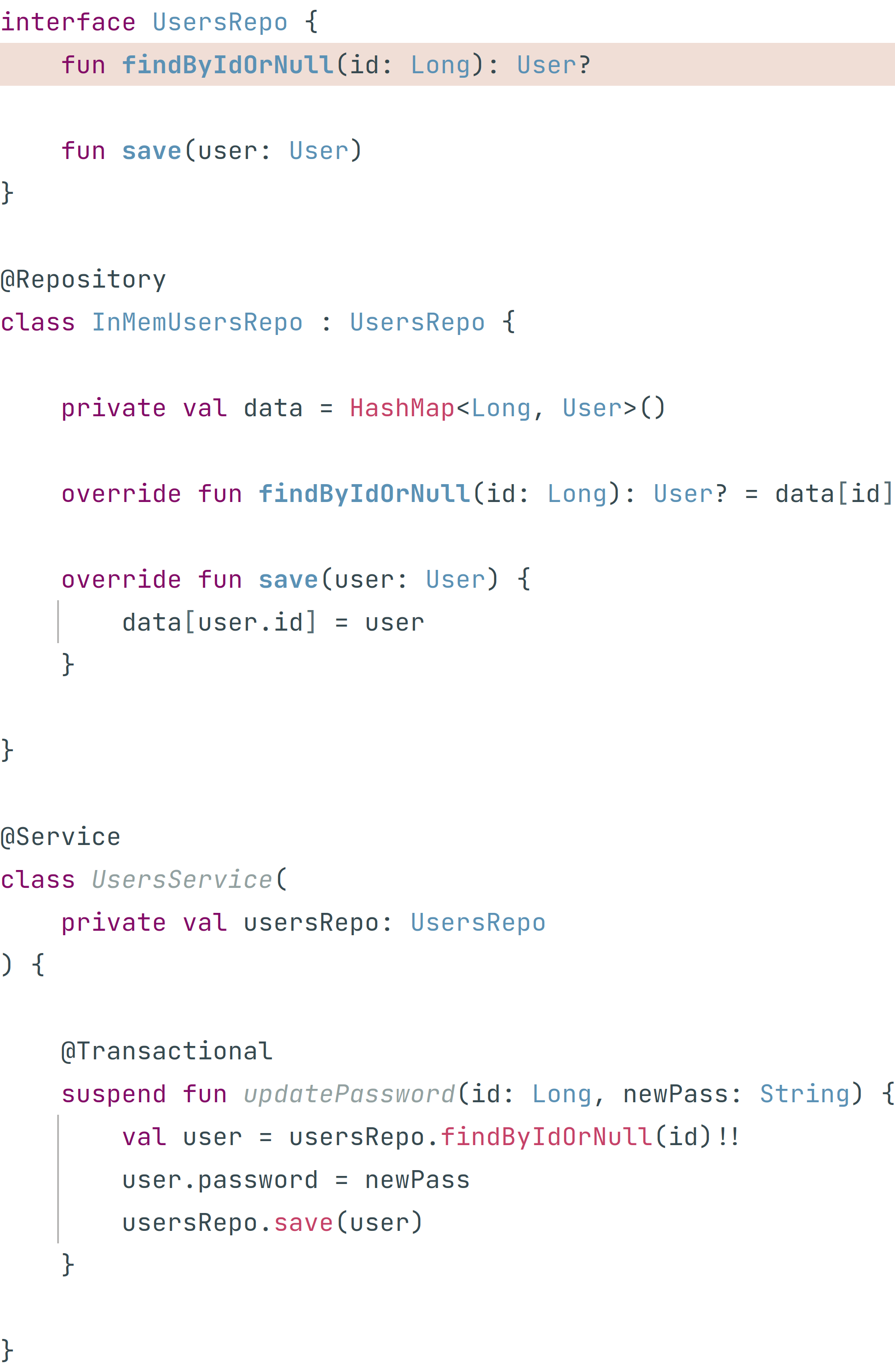
Теперь Артемий может спокойно добавить "реализации" с помощью Spring Data JDBC и у него всё будет работать. Он в этом уверен, потому что перестал использовать моки в тестах.
У Анкл Боба есть принцип стабильных зависимостей, который гласит, что зависимости между модулями должны идти в направлении более стабильных модулей. А стабильность он приравнивает к абстрактности модуля - отношению интерфейсов к конкретным классам.
Именно по причинам описанным в истории выше я определяю степень стабильности по другому: "Стабильность определяется по значимости для бизнеса, вероятности изменений в будущем и количеству входящих связей. Значимость для бизнеса и вероятность изменений определяются посредством гадания на кофейной гуще.".
Функциональная архитектура > Чистая архитектура
В Эргономичном подходе я отказался от Чистой архитектуры по умолчанию именно потому, что интерфейсы и инверсия зависимостей сами по себе не дают никаких выгод, а ресурсы и разработчика и компьютера жрут. Если же "программировать в абстракции" (пускай и в виде конкретных классов), то мигрировать на интерфейс будет делом пары минут. И это всё совершенно бесплатно.
В примере in-memory репозитория у меня всё равно осталась деталь, на которую можно случайно завязаться - репозиторий возвращает изменяемый объект и клиент точно так же может забыть позвать save и всё будет работать. До миграции.
Если же использовать неизменяемую модель данных, то на такую деталь завязаться уже не получится. На мой взгляд, разделение ввода-вывода и чистого ядра и их связь через data-driven интерфейсы (передачу неизменяемых структур данных) даёт на порядок большую степень защиты от завязки на детали реализации, чем интерфейсы.
Именно поэтому в Эргономичном подходе я по умолчанию использую функциональную архитектуру ака функциональное ядро/императивная оболочка.