planner
Ludwig HuangDatabase Query Planner
Based on NanoDB.
In this article, I will introduce query planner in databases, mainly about some non-trivial operations and processes.
Sections: Preparation, Processing Model, Planning, and Expression Evaluation (Subqueries).
Preparation
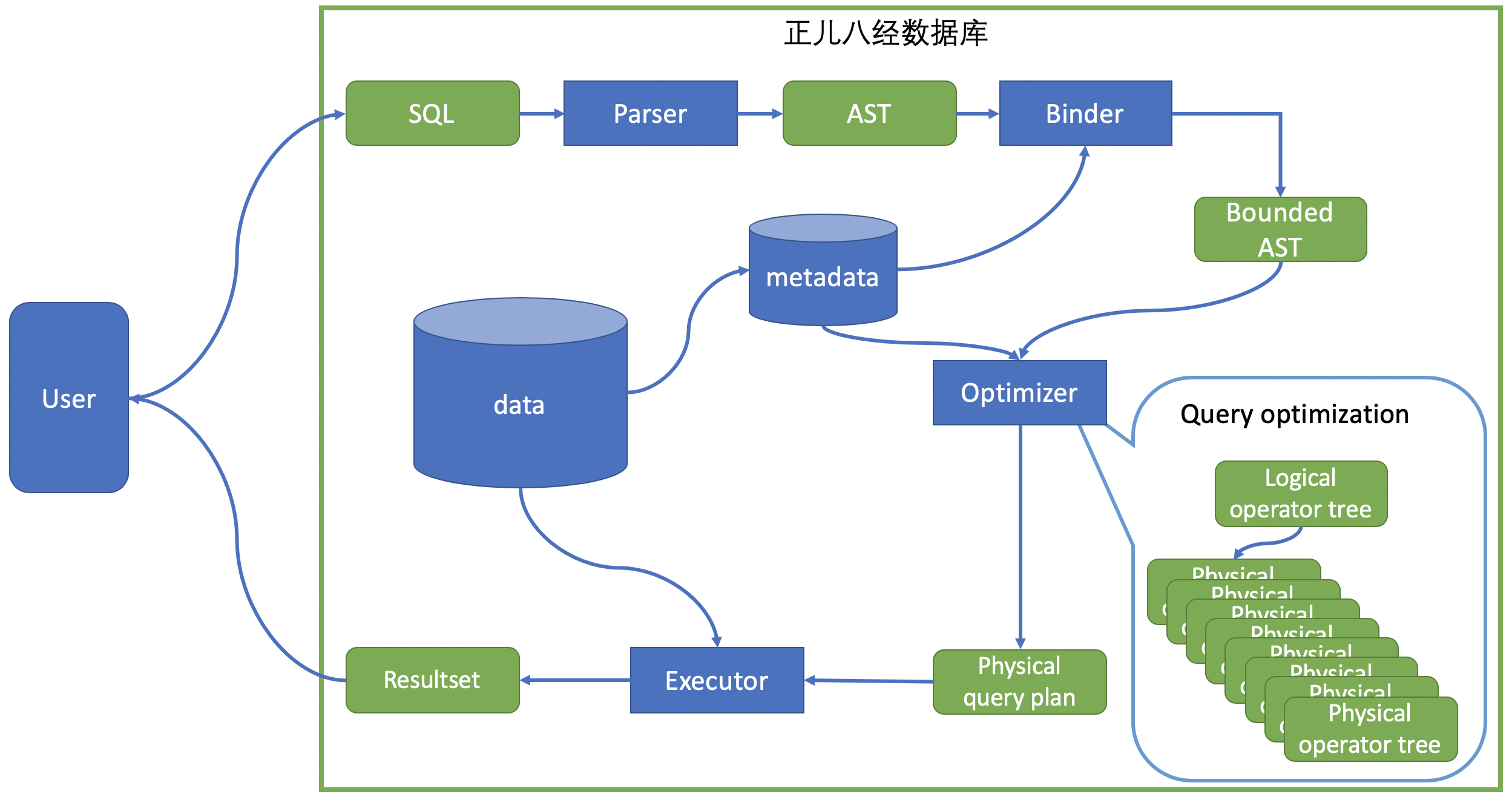
Before dive into query planner, we need to have enough knowledge about how a query runs. [1] [2]
- Client sends SQL stmts (Statements) to database system (via network or just local terminal). Database assigns an process/thread for the query stmts.
- In Query Parsing and Authorization, database will validate the priority of user and determine whether it is safe to execute or not. And also, the stmts will be parsed to an AST (Abstract Syntax Tree) and bound to particular tables. In this step, database also check if there is any syntax errors, including check if the table exists.
- [Optional] In Query Rewrite, database might rewrite the SQL to more efficient version. (It is advanced feature, not included in this article)
- In Query Optimizer, database will do two main stuff: Planning and Optimizing. The two main stuff generate a physical plan for each stmt.
- In Plan Executor, database takes the physical plan and execute it using query executors.

More briefly, database takes a SQL stmt. Parser and binder parse the SQL to bounded AST. Optimizer (also planner) takes the AST and generates a query plan. Executor does stuff according to the plan nodes and produces result set.
Processing Model
Same with bustub, NanoDB also executes a query plan under iterator model. The relational operator is represented as a plan node. A query plan is a tree constructed by several plan nodes. Every plan node has a Next function.
A plan node must implement prepare, initialize, getNextTuple:
prepare: Prepare for output schema and cost statistics (introduced later in another article).initialize: Initialize (re-new) the plan node to initial state. For example, when aNestLoopJoinnode has run out of the right child, it will callinitializeof right child.getNextTuple: As name illustrates, the node will retrieve the next raw tuple from tables or the next tuple from its child node. (Apply an predicate if necessary)
The execution is very straightforward. The data/tuple flows from base tables to the root node. A tuple is processed one node by another. After several filters, updaters, it finally reaches the root node and becomes one member of the result set.
Planning
For now, we do not consider about optimization. The planning is only about translating AST to an executable physical plan -- SQL Translation. By the way, planner is also responsible for detecting semantics error.
A general SQL stmt represents as "SELECT ... FROM ... GROUP BY ... HAVING ... WHERE". In NanoDB, a query stmt is organized as below:
- "SELECT"/"Projection":
getSelectValues=> a list of selected expressions - Expression: column value, mathematical formula, subquery
- "FROM":
getFromClause=> no table, base table, subquery, join of tables/subqueries - "WHERE":
getWhereExpr=> a predicate expression - Predicate expression: =, <, ≤, >, ≥, IN, EXISTS
- "GROUP BY" & "HAVING":
getGroupByExprs&getHavingExpr=> group by expressions & having predicate (similar to "WHERE") - "Limit Offset", "Order By" ...
In NanoDB, the planner constructs a query plan from bottom to up. The scheme below describes how planner works in high-level:
PlanNode plan = null; if (FROM-clause is present) plan = generate_FROM_clause_plan(); if (WHERE-clause is present) plan = add_WHERE_clause_to(plan); if (GROUP-BY-clause and/or HAVING-clause is present) plan = handle_grouping_and_aggregation(plan); // Other clauses: LIMIT & OFFSET, ORDER BY, DISTINCT... if (ORDER-BY-clause is present) plan = add_ORDER_BY_clause_to(plan); plan = add_SELECT_clause_to(plan); // Projection node
FROM
A FROM-clause might be:
- no-table:
SELECT 2 * 3 AS six. In this case, create aProjectNode. - base table:
SELECT a FROM tbl. Create aFileScanNodefor a table. - subquery:
SELECT a FROM (SELECT * FROM tbl). Make a query plan for the subquery. - join:
SELECT a FROM (SELECT * FROM tbl1) JOIN (SELECT * FROM tbl2) ON tbl1.a = tbl2.a. A join is very different from others, because it can be nesting. So, when encounters a join clause, planner will callmakeSelectrecursively. Only until left child and right child have been constructed as plans, the join will create aNestedLoopJointo join those plans.
It is very straight forward to create a plan of FROM-clause.
WHERE
A WHERE-clause might be:
- =, <, ≤, >, ≥: boolean expression. Add the expr as predicate to current plan (
SelectNode). - IN, EXISTS: subquery expression. Add a
FilterNodeas the parent node.
NanoDB provides a helper method for this tedious work -- addPredicateToPlan.
GROUP BY/HAVING
NOTE: Aggregation expressions are not allowed to appear in WHERE/ON/GROUP BY.
An aggregation expression can appear in SELECT and HAVING. So, the planner needs to traverse all the expressions to determine whether it is a function call or not. If an expression is a function call, the expression processor records the expression and its name. After mapping function call to its unique name, create a HashedGroupAggregateNode with group by expression and having predicate and also mapping.
Our responsibility is easy: just mapping function call to its unique name, and create a node. -- The execution of GroupAggregateNode might be confusing. Brief speaking, it will walk through the child node to generate a linked hash map of group values and output values. Then, it can return the values one by one. [3]
Expression Evaluation
An expression might be: mathematical formula, predicate, function call, subquery. Most of them are trivial, only subquery involves a lot. Therefore, I only introduce how to evaluate subquery.
A subquery can appear in SELECT, WHERE, HAVING as an expression. If a subquery does not reference columns in outer node, it is very straightforward to figure out -- just make a subquery plan for it.
But for a correlated subquery, it is a challenge actually. In NanoDB, the planner uses an approach about environments: build an environment-chain so that when referencing an outer column, the node can search in its parent.
An environment provides schemas for tuple to find out where it goes. The relation between environment and plan node is one-to-one mapping. A plan node will store current tuple in its environment so that its child subquery can retrieve tuple easily.
To build an environment-chain, walk through each possible clause to find all subqueries. Then, create a empty environment. Add the environment to the subquery plans as a parent environment. Finally, set the environment to the clause plan node.
Therefore, a subquery expression can reference outer query's columns.
Summary
In summary, we have built a naïve planner to generate a executable query plan. It involves: JOIN, GROUP BY/HAVING and subquery... But the planner is too silly to execute query well, we need an optimizer.
Reference
[1] Architecture of a Database System - fntdb07
[2] Executing SQL Statements - IBM document
[3] Operator Execution - bustub-3
Published by Tech Blog - Huang Blog.