Группировка ошибок в Firebase Crashlytics как душе угодно
Osip Fatkullin at @RaReilly
Недавно на работе прилетела интересная задачка - поправить группировку сетевых ошибок в Crashlytics. Нужно сделать, чтобы было понятно какой именно метод API упал. Вопрос почему это понадобилось делать со стороны приложения предлагаю оставить за скобками и сразу перейти к задаче :)
Дисклеймер: Несмотря на то, что я решаю проблему именно для сетевых ошибок, способы её решения могут пригодиться и в других случаях.
Будет рассматриваться решение для Retrofit.
Почему все ошибки свалены в кучу?
В нашем случае репорты обо всех сетевых ошибках прилетали из двух возможных точек:
Response.checkIsSuccessful()- экстеншен, который бросает исключение в случае, если запрос неуспешныйServerErrorsInterceptor- интерсептор OkHttp, который в случае ошибки парсит тело ответа и выбрасывает созданный на его основеServerExceptionобогащённый дополнительными данными
Всё что написано о логике группировки в документации Crashlytics это:
Crashlytics saves you troubleshooting time by intelligently grouping crashes and highlighting the circumstances that lead up to them.
Так что опираться придётся на свои наблюдения. А наблюдения и DevRel Crashlytics говорят, что исключения группируются по полному имени метода и номеру строки. Важно, что полное имя метода включает в себя пакет и имя класса.
Таким образом intelligent grouping раскладывает наши исключения по двум "кучкам" т.к. все они, как я уже писал выше, выбрасываются из двух точек.
К сожалению, в Crashlytics нет способа настроить группировку исключений, как это можно сделать в Sentry. Есть возможность добавить кастомные ключи в репорт, но они не влияют на группировку, а только служат как мета-информация по которой можно фильтровать исключения. Так что нужно что-то придумывать.
Разбираемся с экстеншеном
Случай с экстеншеном исправить оказалось просто. Вот код до исправления:
fun <T> Response<T>.checkIsSuccessful(): Response<T> = apply {
if (!isSuccessful) throw HttpException(this)
}
Нам интересно видеть откуда эта функция вызвана, а значит checkIsSuccessful должен исчезнуть из стектрейса. В этом нам поможет inline:
// We don't want to see checkIsSuccessful call in stacktrace,
// so make it inline
@Suppress("NOTHING_TO_INLINE")
inline fun <T> Response<T>.checkIsSuccessful(): Response<T> = apply {
if (!isSuccessful) throw HttpException(this)
}
Теперь вызов функции инлайнится в момент компиляции и в стектрейс не попадает - то что нужно.
Фиксим интерсептор
Мы знаем, что при группировке Crashlytics смотрит на имя метода и номер строки, а значит мы можем подделать стектрейс. Для этого нам нужно:
- Общая точка где эту подмену можно сделать - это как раз наш интерсептор
- Информация о методе API который был вызван
Группировать исключения хочется по двум параметрам - метод API и код ответа. Например, ошибки 401 не так интересны для нас как ошибки 500, поэтому группировка по коду ответа будет полезна.
Для имени метода можно было бы взять Request.url, но в этом случае нужно думать о нормализации этого значения. Нужно исключить query-параметры и host, а так же помимо пути учитывать HTTP-метод. Вместо этого будем использовать другой способ.
В OkHttp у Request есть метод tag(type: Class<T>): T, этот метод позволяет получить объекты (теги) прикреплённые к запросу по их типу. Механизм тегов позволяет прикреплять к запросам любые данные, которые позже можно будет прочитать в интерсепторе. Например, Retrofit прикрепляет ко всем запросам объект Invocation в качестве тега. В этом объекте хранится ссылка на метод в интерфейсе API, которому соответствует запрос, а так же список аргументов с которыми он был вызван.
У нас есть всё чтобы написать код:
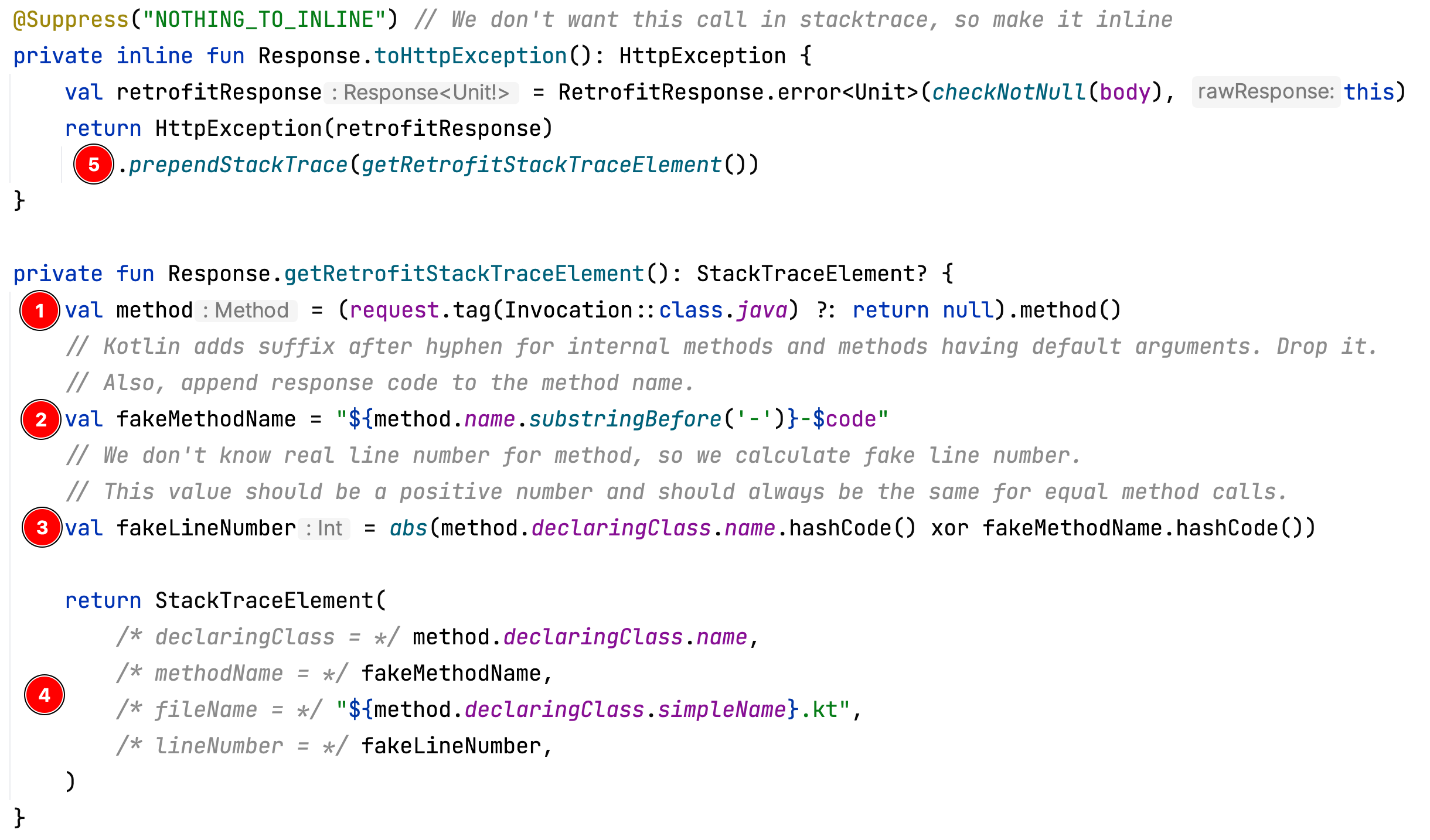
- Получаем метод из тега
Invocation. Для приличия перестраховываемся и возвращаемnullесли тега нет. - Помним, что по имени метода будет совершаться группировка исключений, поэтому имя метода комбинируем с кодом ответа. Предварительно убираем из имени метода любые суффиксы, которые добавляет Kotlin.
- К сожалению, мы не знаем строку метода, но нам подойдёт любое положительное число, которое будет однозначно идентифицировать имя метода и статус ответа. Берём xor хэш-кодов по модулю, этого должно быть достаточно.
- Собираем всё что получили ранее в
StackTraceElement, имя класса никак не изменяем, указываем имя файла - по нему будет удобно визуально находить исключения. - Метод
prependStackTraceделает именно то что вы подумали - добавляет новые элементы в начало стектрейса.
Полный код интерсептора смотрите на GitHub. Кстати, там есть ещё один костыль который может быть интересен - чтение тела ответа без вызова .string().
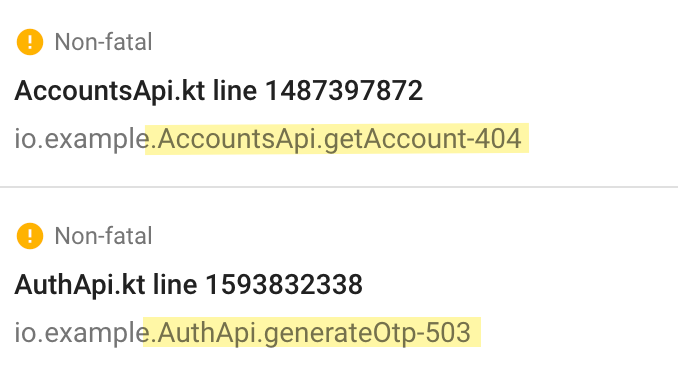
Неадекватно большие номера строк это нормально т.к. под капотом hashCode
Лирическое отступление
Кстати, паттерн когда к объекту можно прикреплять любые данные как теги используется не только в Retrofit. Вы могли встретить его, например, во View. Метод View.setTag(int key, Object tag) это немного другая реализация того же паттерна. Применений тегов можно найти много (сразу отбросим идеи привязывать модели данных к вьюхам):
- В androidx.navigation с помощью тегов к вьюхе привязывают
NavController - В coil, в тег записывается
RequestManager - Повсеместно теги используются для сохранения данных для анимаций
Альтернативное решение
Этот вариант решения мне пришёл в голову пока я писал первую часть. На практике я его не проверял, но решил упомянуть, т.к. подход отличается и в некоторых случаях может оказаться более подходящим.
Если тема покажется вам интересной - ставьте лайки, а я постараюсь опробовать эту идею и написать о результатах.
Мы взяли в качестве точки изменения исключений сам интерсептор. Но можно пойти другим путём:
- Создавать некий "breadcrumb exception" в том месте где мы передаём исключение в Crashlytics. В нашем случае это дерево Timber'а.
- Отфильтровать из стектрейса всё лишнее. Например, выкинуть цепочку вызовов внутри Timber. Таким образом мы получим место в котором был вызван Timber.
- Перед тем как выкинуть исключение, добавлять только что созданное исключение к нему как
causeили подмешивать элемент стектрейса на первое место
Этот подход немного похож на тот, который используют в библиотеках для поиска места ошибки в RxJava: RxJava2Debug и RxDogTag.
В теории такой способ решения должен быть более универсальным, т.к. будет покрывать не только случай с сетевыми ошибками, но и другие случаи. Например, когда вы пробрасываете в Timber исключение из сторонней библиотеки, вы будете видеть место в коде где это исключение было поймано (привет Dns.loockup). Но есть опасение, что у такого подхода будут и проблемы.
Группировка исключений сильно поменяется из-за того, что теперь все исключения будут группироваться по месту где их поймали, а не месту где они были выброшены. В случае когда есть общее место, где вызывается Timber, это может оказаться особенно вредно, хотя и решаемо в некоторых случаях добавлением inline.
В общем, надо пробовать будет ли этот подход приносить больше пользы чем вреда или наоборот.