dbt: источники и сиды
Владимир ТрифоновВидео-версия: https://youtu.be/CxeGjK8MN0g
Привет. В прошлый раз мы остановились на домашнем задании. Давайте быстро пробежимся по тому, что должно было получиться.
Первая модель с фильмами:
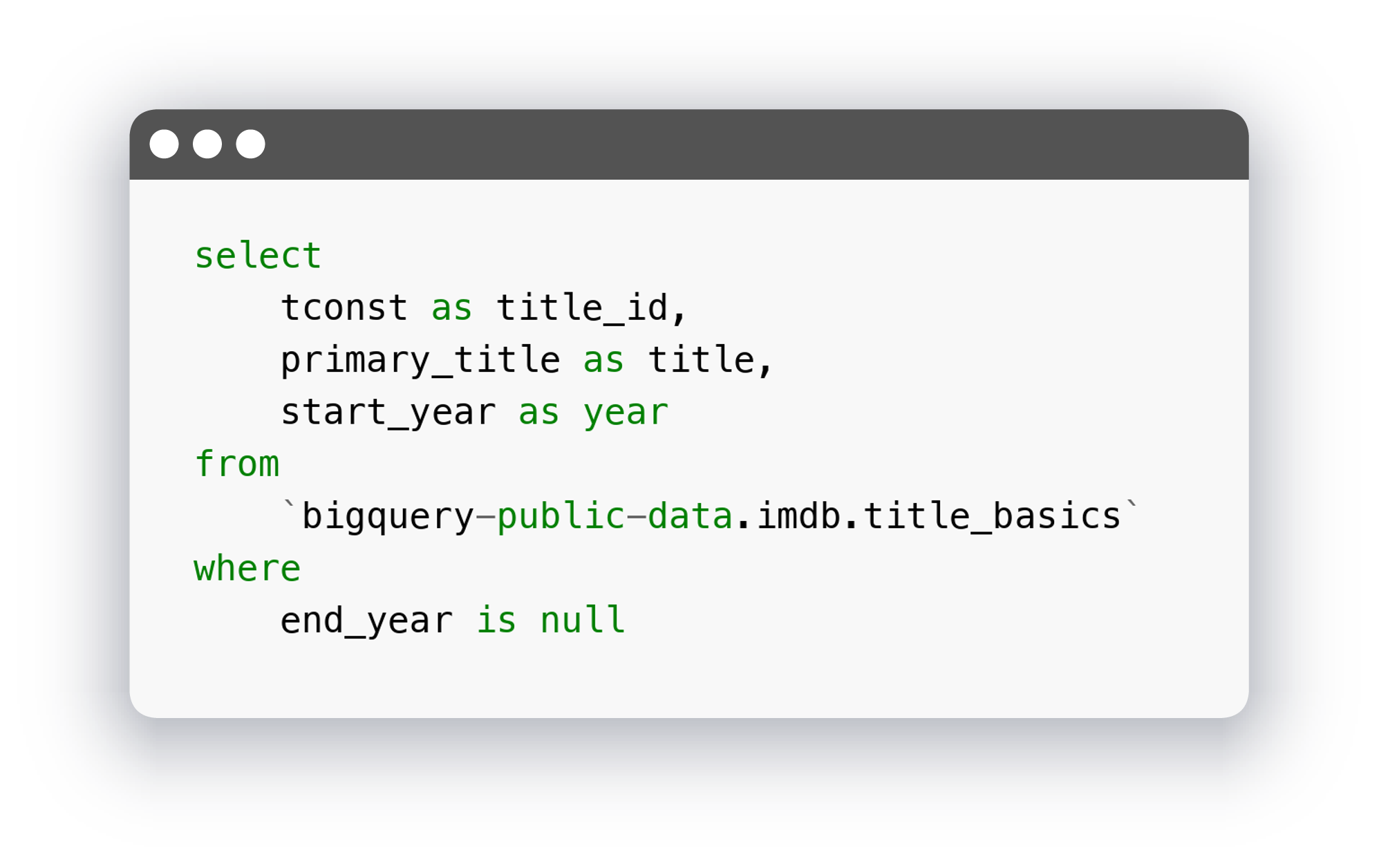
Вторая модель с рейтингами:
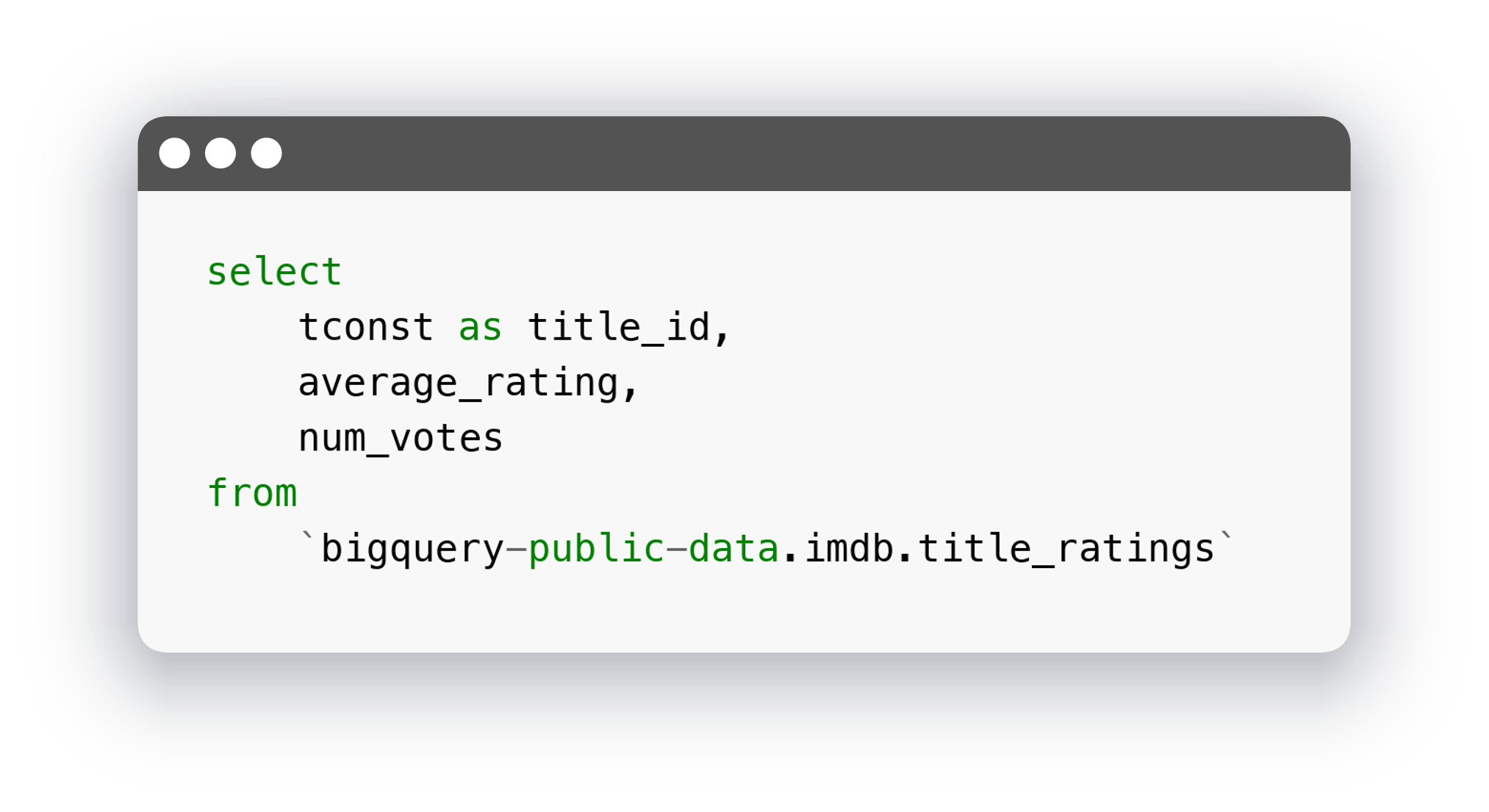
Третья модель с рейтингами фильмов за 2022 год. Обратите внимание на config:
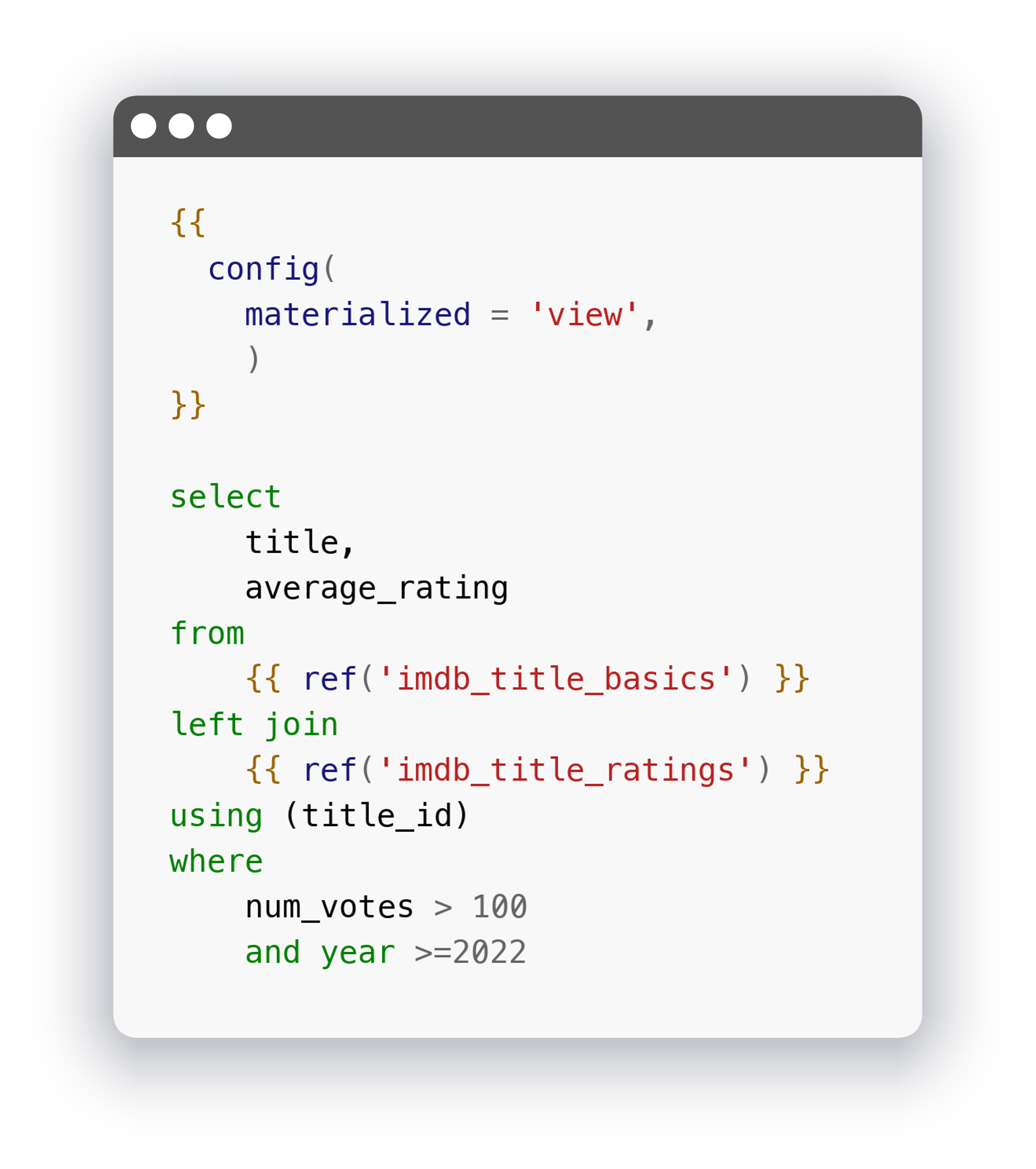
И настройки проекта, где мы указали, что все модели в папке должны быть в виде таблиц:
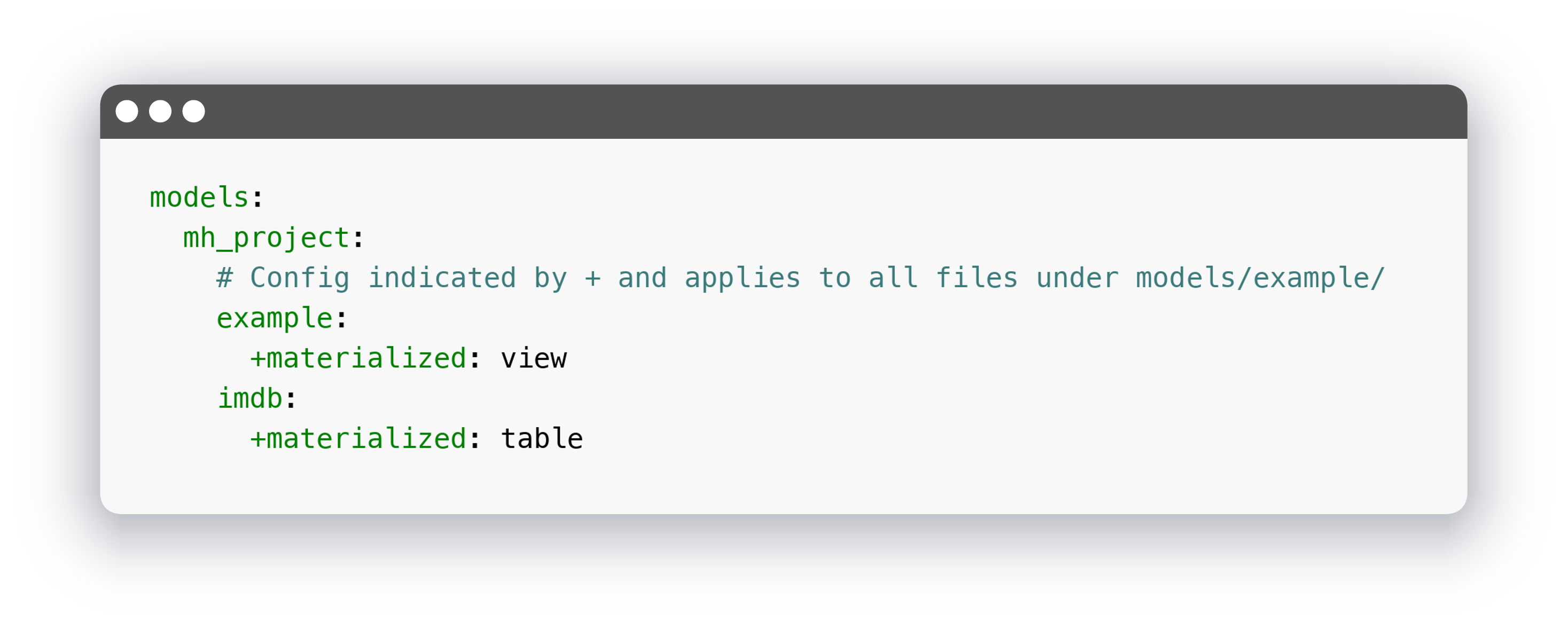
В результате содержимое датасета должно быть таким:
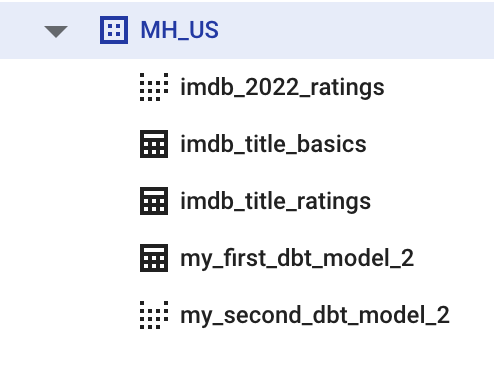
И давайте напоследок удалим наши тестовые модели из проекта. Для этого просто удалите папку example и конфигурацию в dbt_project.yml:
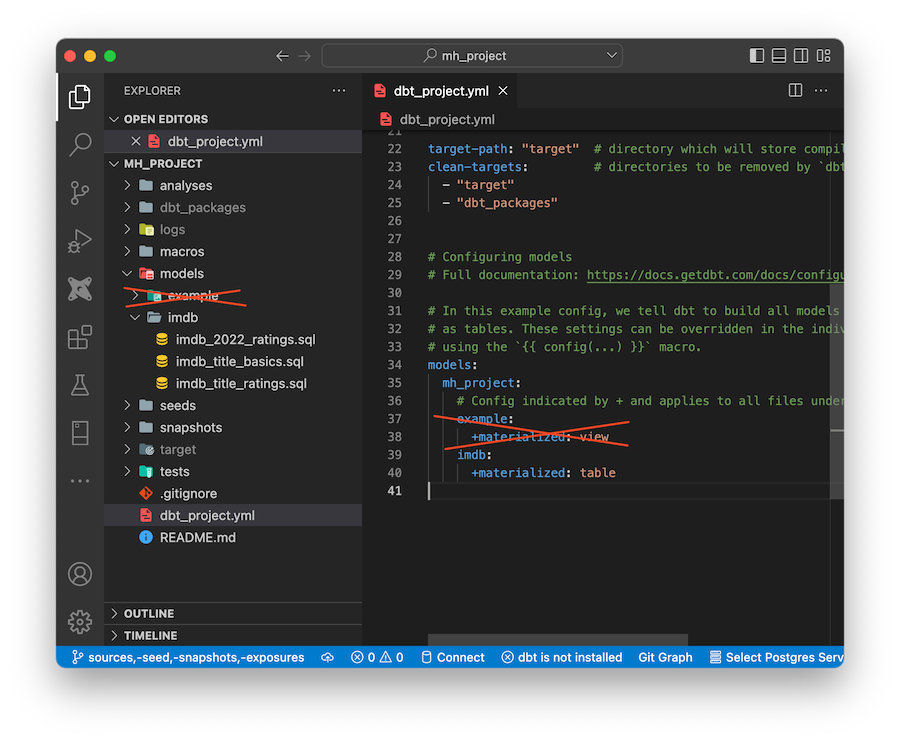
И не забудьте удалить таблицы в BigQuery. Теперь поговорим о вспомогательных частях dbt, которые окружают модели в dbt.
Источники данных
Источник данных это таблицы, на которые вы никак не влияете в вашем конвейере. Проще говоря — это внешние источники данных. Это могут быть данные из CRM, стриминг сессий или хитов, какие-то данные с приборов. Или, как в нашем примере, это могут быть данные о фильмах. Т.е. источник — это точка входа в наш конвейер.
Давайте создадим наш первый источник. Для этого добавьте файл sources.yml в папку models со следующим содержанием:

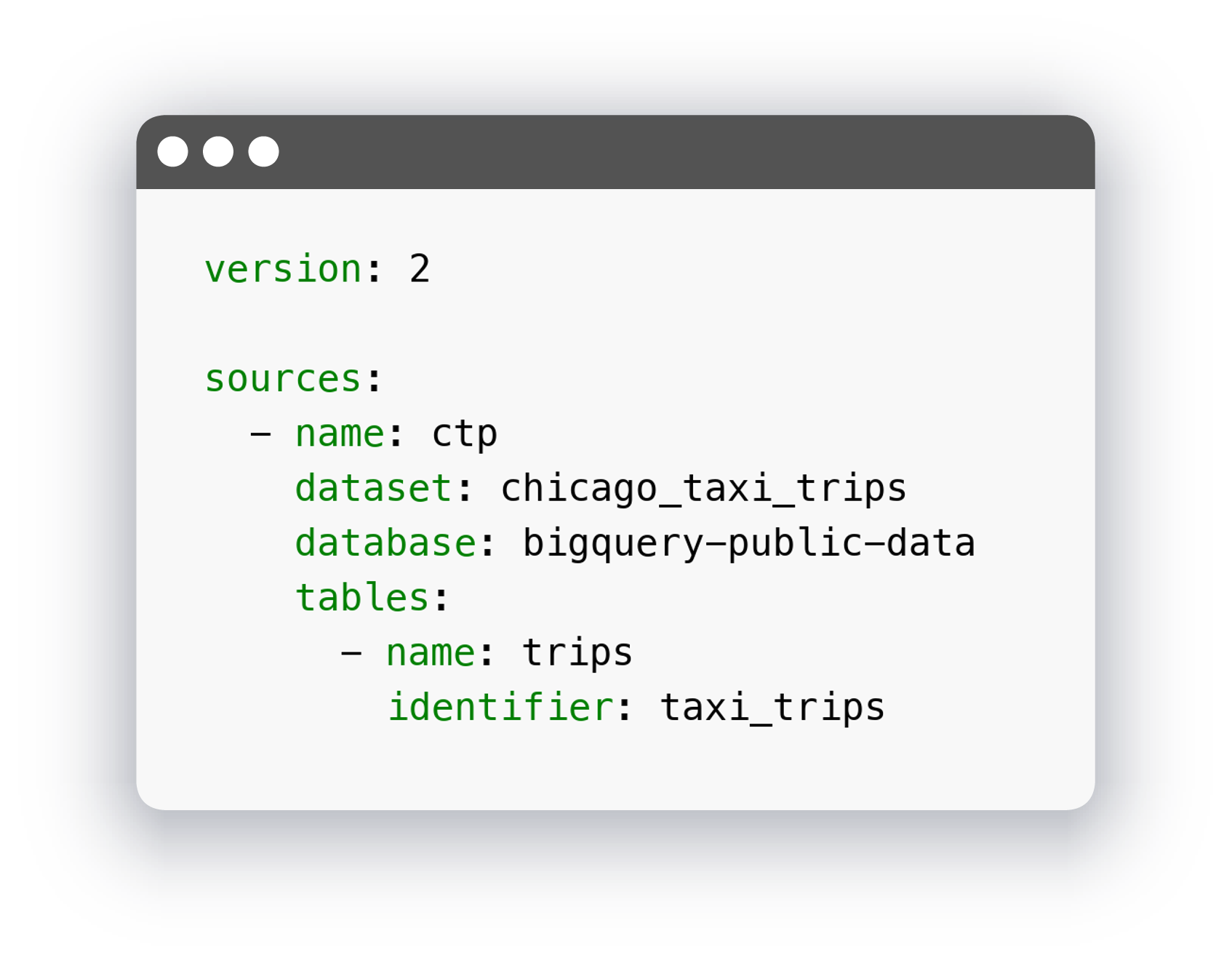
Для примера я взял таблицу с поездками чикагских такси из bigquery-public-data.chicago_taxi_trips.taxi_trips. В данном случае мы определили источник, указав в качестве имени название датасета, в параметре database – проект в BigQuery. И определили список таблиц в этом датасете в параметре tables.
Давайте сделаем представление, выводящее список поездок за последнюю неделю:
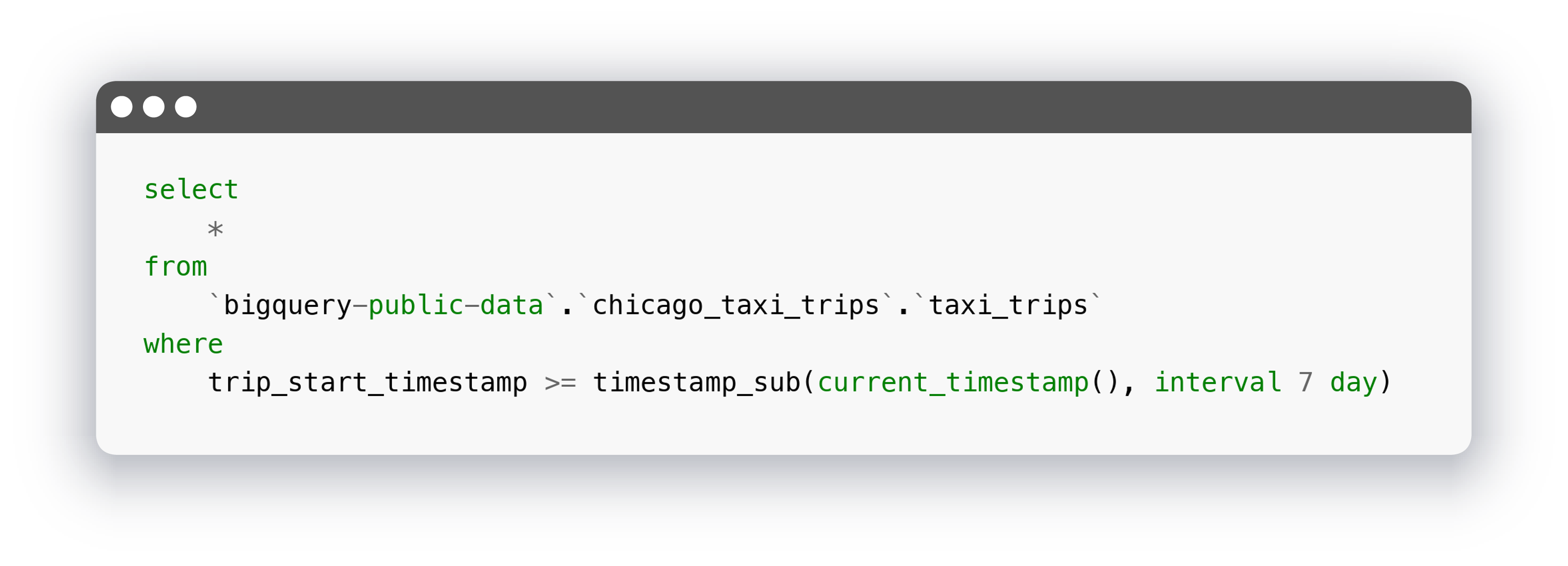
Как мы видим, dbt автоматически подставил название базы данных и сформировал идентификатор таблицы. Иногда бывает так, что названия таблиц не очень удобны для нас. Тогда мы можем указать реальные названия в файле конфигурации и там же указать удобные для нас:
И обратиться к нему следующим образом:

А в результате получим все тот же скомпилированный идентификатор таблицы. Подробнее про настройки источников можно почитать в документации.
Как запускать модели
К этому моменту у вас, наверное, возник вопрос о том, как можно запускать отдельные модели. Вот мы, например, сделали модели для imdb, а теперь мы сделали модель для такси и нам пересчитывать информацию о фильмах нет никакой нужды. Для этого в dbt есть гибкая система запуска моделей. Сейчас я вкратце расскажу об этом.
Для того, чтобы запустить конкретную модель нужно указать название модели после флага -s:
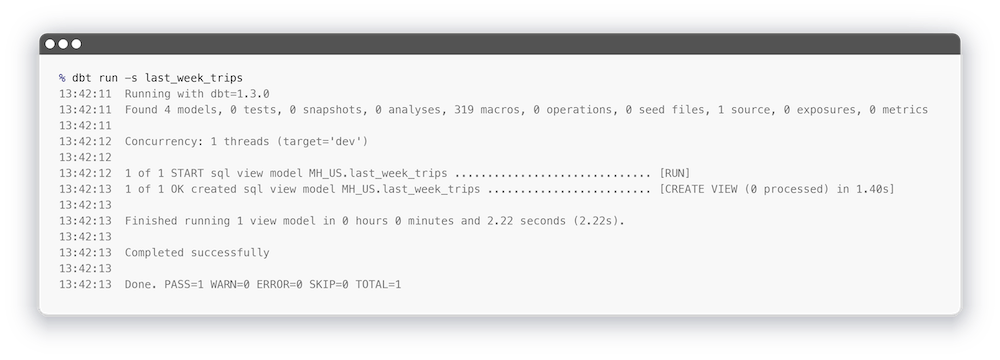
Также вы можете запустить модели, которые зависят от какой-то модели или источника, добавив + к названию:
Тут мы видим, что для запуска всех моделей зависящий от источника нужно указать конструкцию вида source:<source_name>.<table_name>+. Название таблицы указывать необязательно: тогда посчитаются все модели, зависящие от таблиц в датасете <source_name>.
Также вы можете запустить пересчет всех моделей, от которых зависит данная, указав + перед названием модели:
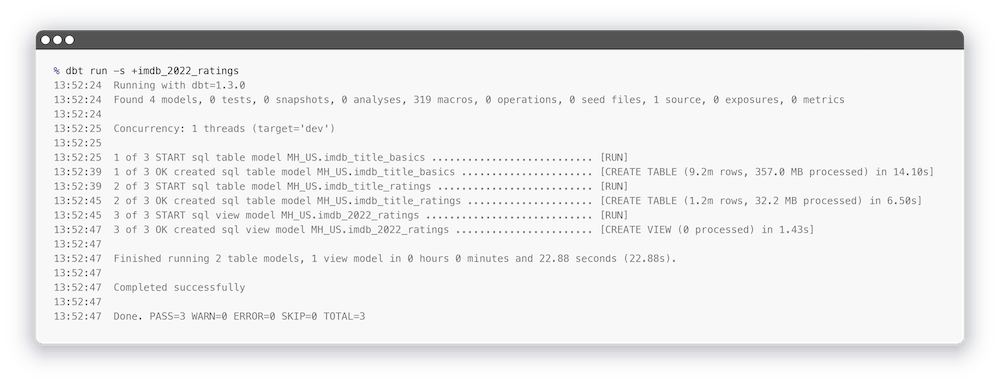
Закончим тут наш небольшое отступление и вернемся к способам выбора моделей для запуска позже.
Еще источники можно тестировать и проверять их свежесть. Про это мы поговорим в уроке про тестирование. А пока перейдем к сидам.
Сиды (seeds)
Сиды — это csv-файлы, которые хранятся в папке seeds. Dbt загружает их в базу данных и они становятся доступными через метод ref(<имя файла>). Сиды находятся у вас репозитории и поэтому на них тоже распространяется версионирование.
В качестве сидов лучше всего использовать статические данные, которые редко меняются. Например:
- Связки названий стран и их кодов
- Тестовые адреса почты, телефоны или имена пользователей, которые не надо учитывать при расчете
- Список идентификаторов сотрудников, которые не нужно использовать в расчетах
Не стоит использовать в качестве источников сырые данные, которые экспортировали в csv. Их лучше загрузить напрямую в БД.
Давай сделаем список тестовых идентификаторов такси и модель, которая исключит их из общего списка. Для этого создадим файл test_cars.csv:
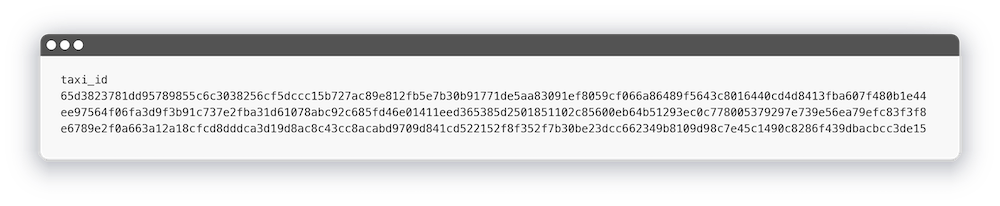
Я просто взял три случайных идентификатора из таблицы с такси и добавил в файл. Давайте теперь запустим команду dbt seed:
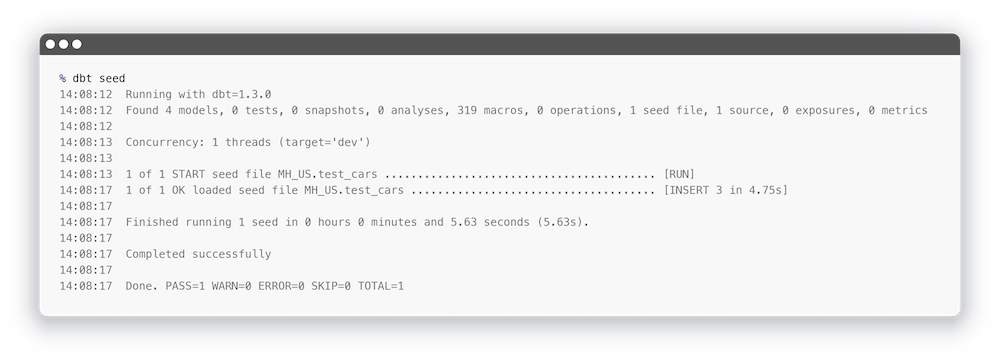
И посмотрим, что у нас получилось в BigQuery:
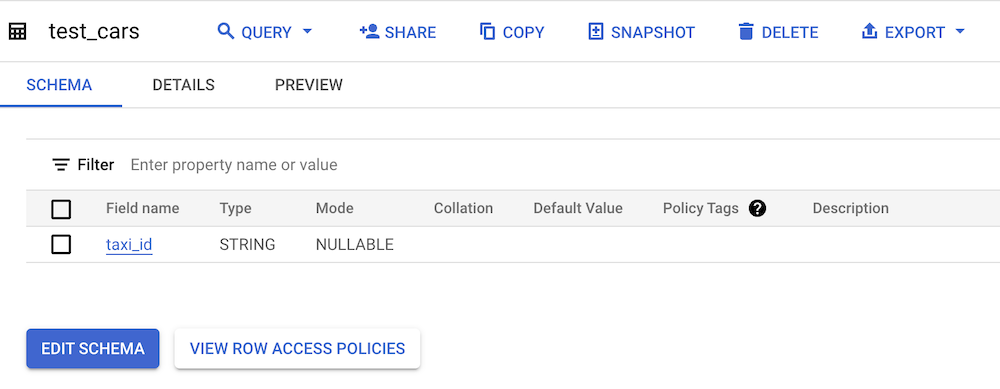
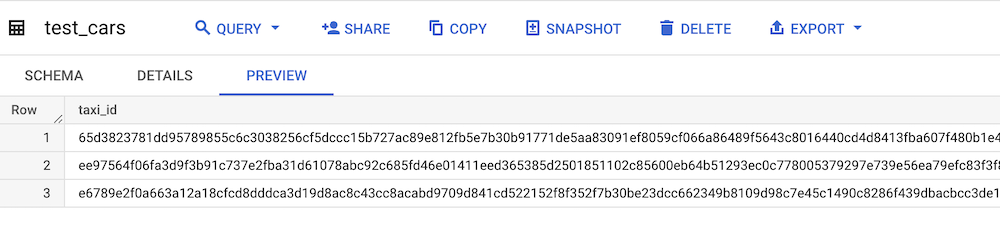
Dbt загрузил данные в таблицу, взяв название столбцов из файла. Давайте теперь обновим нашу модель:
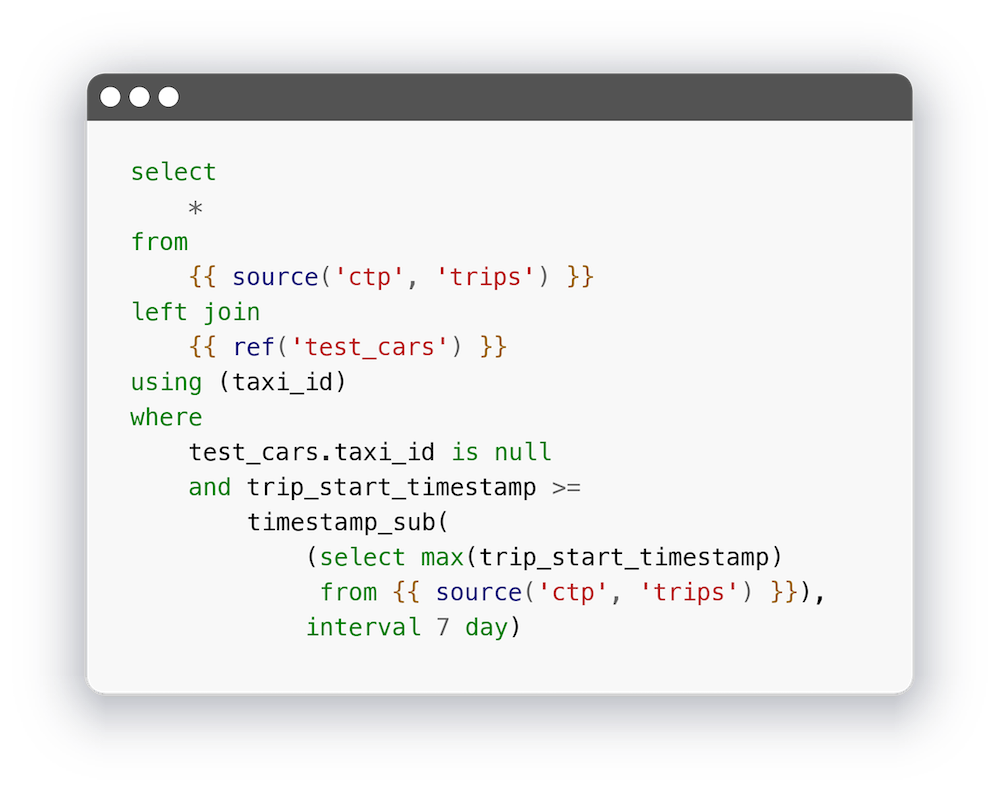
Я немного доработал код, который выбирает данные из таблицы потому, что она обновляется не так регулярно, как таблица с фильмами.)
Как мы видим, мы можем обращаться к сидам также, как и к обычным моделям. Дополнительную информацию по ним можно почитать в документации.
Домашнее задание
Сделайте источники для двух таблиц, к которым обращаются наши модели imdb. А также выберите три случайных фильма, добавьте их идентификатор в файл imdb_test_ids.csv и исключите их из последней модели.
В следующем уроке мы поговорим о снэпшотах, экспозициях и метриках. До встречи!