Знакомство со стековыми графами
В декабре 2021 года Github объявил, что открывает общий доступ к точной навигации по коду для всех публичных и приватных репозиториев с Python на сайте GitHub.com. Точную навигацию в коде обеспечивают стековые графы, новый фреймвввооорк с открытым исходным кодом, созданный в Github и позволяющий устанавливать правила привязки имен для языка программирования при помощи декларативного предметно-ориентированного языка (DSL). Стековые графы позволяют генерировать данные о навигации по стеку для конкретного репозитория, не требуя при этом какого-либо участия в конфигурировании со стороны владельца репозитория и не вмешиваясь в процесс сборки или другие задания, связанные с непрерывной интеграцией. В этом посте будет подробно рассказано, как работают стековые графы, и как с их помощью достигаются такие результаты.
(Этот пост написан на основе доклада, прочитанного автором на конференции Strange Loop в октябре 2021 года. Есть видео с этим докладом, там рассказано гораздо больше!)
Что такое навигация в коде?
Навигация в коде – это совокупность возможностей, позволяющих на глубоком уровне исследовать существующие в вашем коде взаимосвязи и зависимости. Простейшие варианты навигации в коде – это «перейти к определению» и «найти все ссылки». Обе основаны на том факте, что код, который мы пишем, всюду нашпигован именами. Языки программирования позволяют давать определения сущностям – функциям, классам, модулям, методам, переменным и пр. У всех этих сущностей есть имена, поэтому на них можно ссылаться из других частей нашего кода.
Иллюстрация (даже простая) стоит тысячи слов:

В этом модуле Python ссылка на broil в конце файла указывает на определение функции, сделанное ранее в этом же файле (в рамках этого поста я буду подсвечивать определения красным, а ссылки синим.)
Таким образом, наша цель – собрать информацию о списках определений и ссылок и иметь возможность установить, какие определения с какими ссылками соотносятся, и так для всего кода, расположенного на GitHub.
Почему это сложно?
В вышеприведенном примере определения и ссылки располагались близко друг к другу, и не составляло труда наглядно представить отношения между ними. Но так просто бывает не всегда!
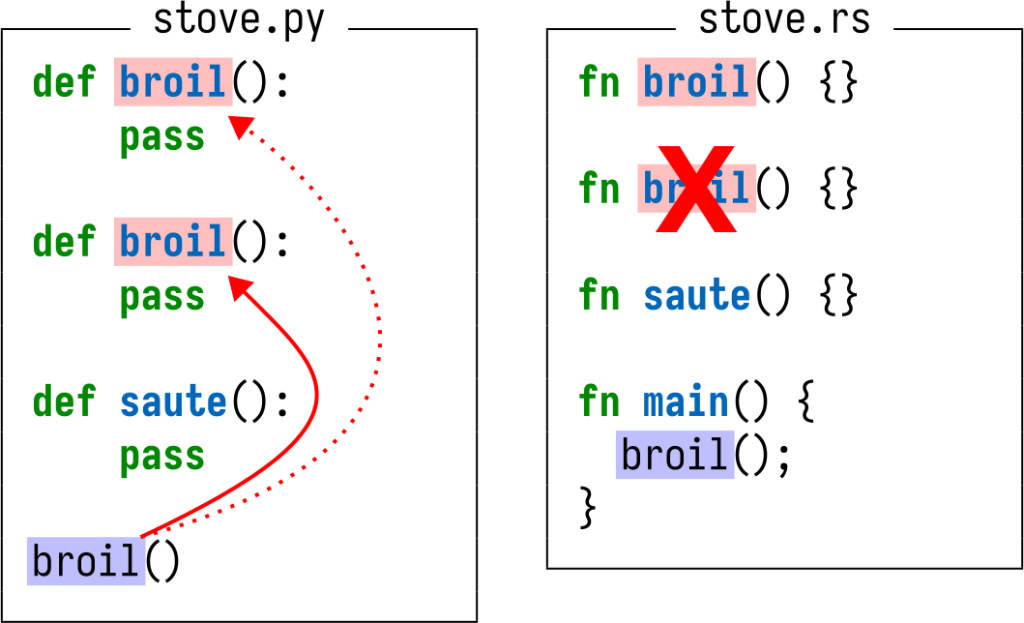
Что делать, например, если у нас множество одноименных определений? В Python имена могут затенять друг друга, и это значит, что ссылка broil должна относиться ко второму из этих двух определений.
Но эти правила специфичны для каждого языка! В Rust не разрешено, чтобы определения верхнего уровня затеняли друг друга, а для переменных это разрешено. То есть, если транслитерировать этот мой пример с Python на Rust, то, в соответствии со спецификацией языка Rust, в коде будет ошибка. Если бы мы писали компилятор для Rust, то хотели бы, чтобы эта ошибка быстро проявлялась, и программист ее исправлял. А что насчет исследовательской фичи, такой как навигация кода? Мы хотим увидеть какой-либо результат, даже в случае, когда код содержит ошибки. В конце концов, человеку свойственно ошибаться!
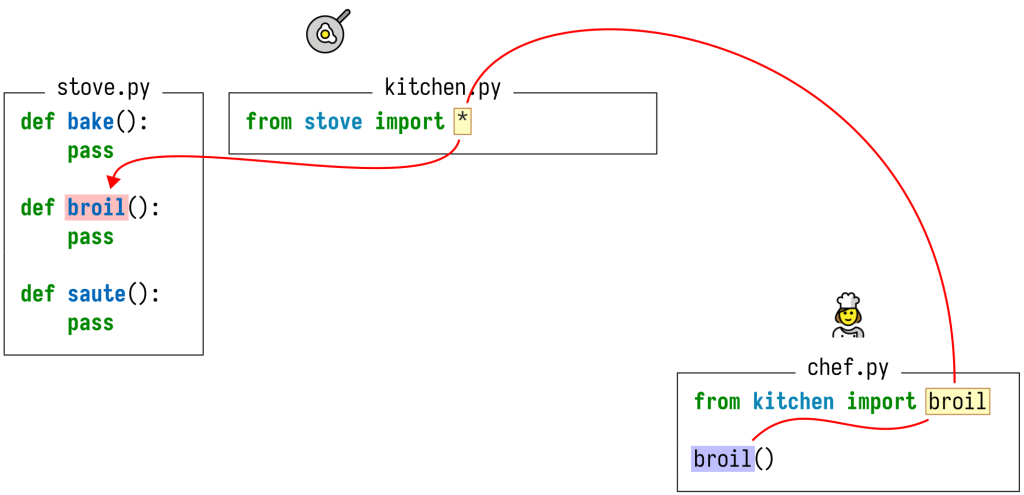
До сих пор мы рассматривали лишь примеры, состоящие из единственного файла каждый. Но когда вы в последний раз работали над программным проектом, в котором всего один файл? Гораздо вероятнее, что ваш код будет разбросан по множеству файлов, множеству пакетов, множеству репозиториев. Языки программирования позволяют ссылаться на определения, которые находятся очень далеко от самой ссылки. Но, как и следует ожидать, правила ссылок на сущности в других файлах отличаются от языка к языку.
В вышеприведенном примере я разделил весь код на три файла, которые находятся в двух отдельных пакетах (репозиториях). Вместо имен пакетов я поставил смайлики. В Python инструкции import позволяют ссылаться на имена, определенные в других модулях, а имя модуля определяется именем того файла, в котором содержится его код. В сумме это показывает нам, что ссылка broil из файла chef.py в пакете “chef” указывает на определение broil в файле stove.py в пакете “frying pan”.
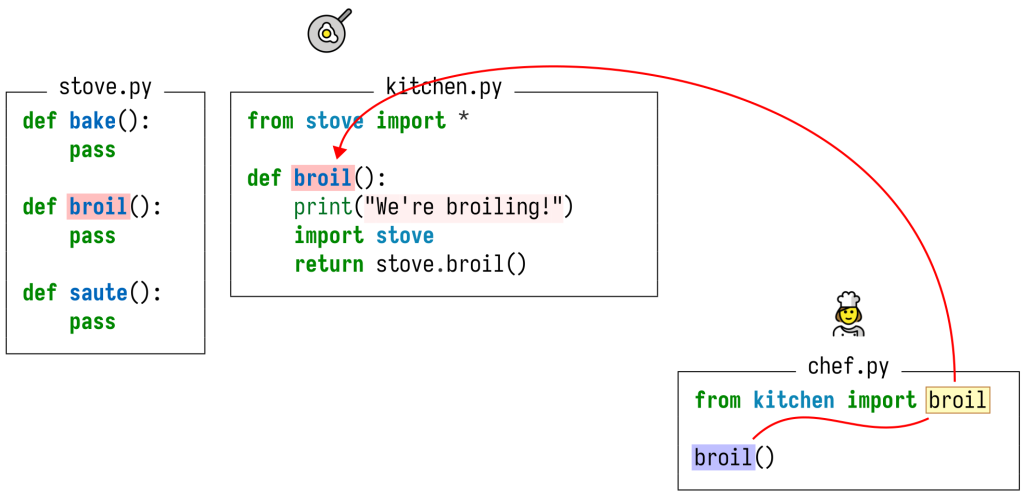
Со временем код меняется и развивается. Что произойдет, когда одна из ваших зависимостей изменит реализацию вызываемой вами функции? В таком случае люди, отвечающие за поддержку пакета “frying pan” добавляют к функции broil кое-какие возможности логирования. В результате ссылка broil в файле chef.py теперь указывает на иное определение. Особенно коварно то, что в данном случае изменился промежуточный файл, а не тот, в котором содержалась ссылка, и не тот, в котором содержалось исходное определение! Если бы мы были неаккуратны, то нам пришлось бы заново проанализировать каждый файл в репозитории и все его зависимости, и так каждый раз, как только изменится любой файл! Таким образом, работа, которую нам приходится проделать, возрастает по мере изменения файлов квадратично, а не линейно, а при таких масштабах как в GitHub это тем более серьезная проблема.
Наша последняя трудность связана именно с масштабом. Как упоминалось выше, мы хотим предоставить описанную возможность для всего кода, расположенного на GitHub. Более того, мы хотим добиться, чтобы ни от кого из владельцев репозиториев не требовалось дополнительно вносить какую-либо конфигурацию вручную. Не следует требовать от вас, чтобы вы сами выясняли, как получить данные для навигации по коду вашего языка и проекта, либо как настроить непрерывной интеграции, чтобы сгенерировать эти данные. Навигация по коду должна Просто Работать.
В масштабе GitHub здесь возникает две проблемы. Первая – чистый объем кода, поступающий на сайт каждую минуту и каждый день. В каждом коммите, который мы получаем, следует ожидать, что изменения внесены лишь в очень немногочисленные файлы из всех имеющихся. Мы должны быть в состоянии полагаться на инкрементную обработку и хранение, повторно используя результаты, ранее уже вычисленные и сохраненные для тех файлов, которые на данном этапе не изменились.
Второй вызов, стоящий перед нами – огромное количество языков программирования, которое нам (в конечном итоге) придется поддерживать. На GitHub хранится код на любых мыслимых языках программирования. Git как таковой не волнует, какой именно язык вы используете в вашем проекте, для Git все состоит из одних байт. Но при реализации такой возможности как навигация в коде, при которой правила привязки имен отличаются для каждого языка, необходимо знать, как разбирать и интерпретировать содержимое этих файлов. Чтобы поддерживать эту возможность в большом масштабе, требуется максимально упростить как инженерам GitHub, так и сторонним языковым сообществам описывать правила привязки имен для языка.
Подытожим:
- В разных языках действуют разные правила привязки имен.
- Некоторые из этих правил могут быть весьма сложными.
- Результаты могут зависеть от промежуточных файлов.
- Мы не хотим, чтобы требовалось вручную конфигурировать каждый репозиторий.
- Для работы в масштабе Github требуется инкрементная обработка.
Стековые графы
Изучив круг проблем, мы решили создать стековые графы, помогающие ответить на эти вызовы. За основу мы взяли фреймворк scope graphs, разработанный исследовательской группой Элко Виссера из Делфтского технологического университета. Ниже будет рассмотрено, что такое стековые графы, и как они работают.
Поскольку нам приходится полагаться на инкрементные результаты, важно, чтобы во время индексирования (то есть, пока мы получаем пакеты с новыми коммитами), можно было полностью рассмотреть каждый файл в отдельности. Наша цель – извлечь «факты» о каждом файле, описывающие определения и ссылки из этого файла, а также все возможные сущности, в которые может разрешаться каждая из ссылок.
Рассмотрим следующий пример:

В нашем конечном результате должна быть предусмотрена возможность закодировать такой факт: ссылка на broil и соответствующее определение находятся в разных файлах. Но, чтобы анализ был инкрементным, нужно рассмотреть каждый файл в отдельности. Я зайду в каждый из файлов и покажу, какую информацию GitHub может извлечь, рассматривая его в отдельности.
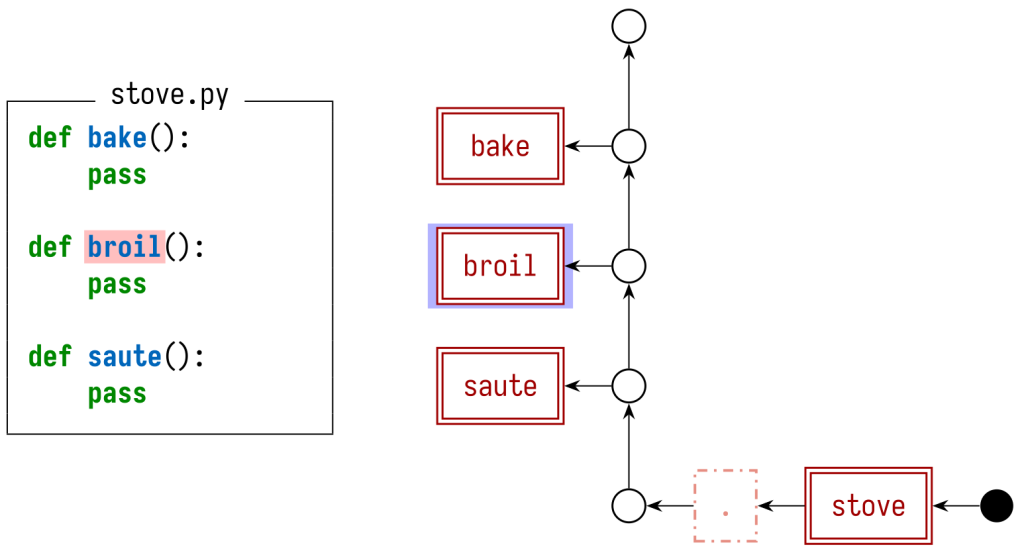
Взглянув сначала на stove.py, видим, что в нем содержится определение broil. Из имени файла становится понятно, что это определение находится в модуле stove, и, следовательно, полностью квалифицированное имя будет stove.broil. Этот факт можно представить, создав структуру в виде графа (и в этом графе также можно поместить другие символы, содержащиеся в файле). Каждое определение (включая сам модуль) получает красный узел в двойной рамке – он называется узел определения. Другие узлы, а также паттерн, в соответствии с которым мы соединяем эти узлы ребрами, устанавливают области видимости и правила затенения для этих символов. Мы не станем внедрять в других языках программирования такие же правила затенения как в Python, поэтому получится другим и паттерн расположения ребер, соединяющих все сущности.
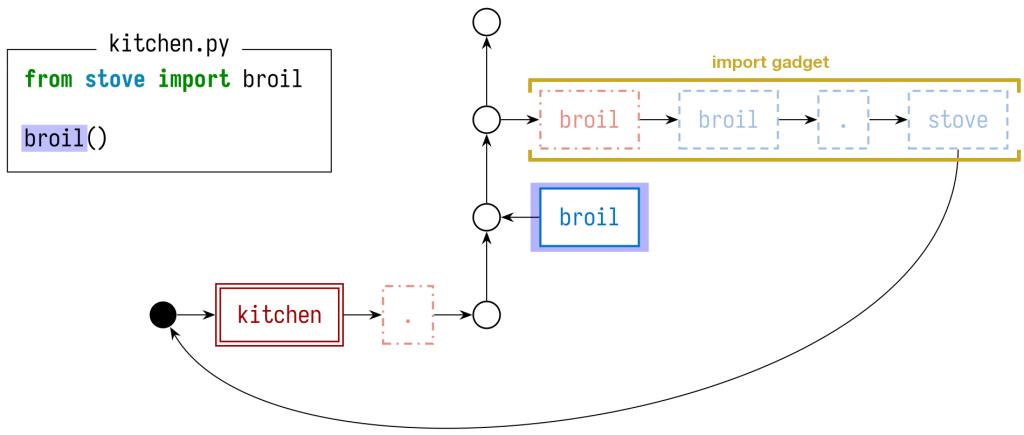
То же самое можно проделать с файлом kitchen.py. Ссылка broil представлена в виде ссылочного узла – он синий, с одиночной границей. В графе также присутствует конструкция import, как характерная деталь узлов, затрагивающих при работе символы broil и stove.
Поскольку мы рассматриваем этот файл в отдельности, мы пока еще не знаем, во что разрешается ссылка broil. Здесь import означает, что она в принципе может разрешаться в stove.broil, определенный в каком-то другом файле — но это зависит от того, а есть ли файл, определяющий этот символ. На самом деле, в данном примере такой файл содержится (мы его только что рассматривали!), но это необходимо игнорировать, выясняя факты о kitchen.py один за другим.
Однако, во время запроса мы в силах объединить данные из всех файлов того коммита, который сейчас рассматриваем. Можем загрузить графы по каждому из файлов, получив единый «консолидированный» граф для целого коммита:
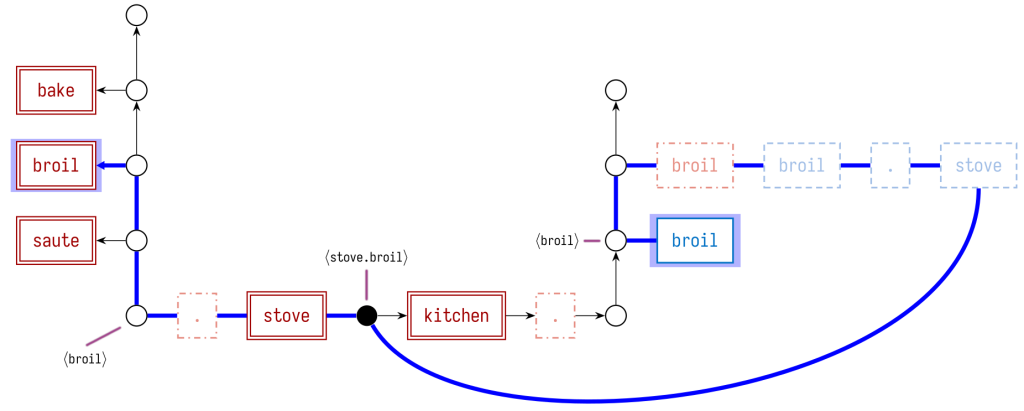
Внутри такого консолидированного графа каждая действительная привязка имен представлена путем от узла ссылки до узла определения.
Тем не менее, не каждый путь в графе соответствует действительной привязке имени! Например, если рассмотреть только структуру графа, есть совершенно нормальные пути от ссылочного узла broil до узлов с определениями saute и bake. Чтобы исключить эти пути, мы при поиске путей также должны поддерживать символьный стек. Каждый синий узел забрасывает символ в стек, а каждый красный узел выталкивает символ из стека. Важно, что нам не разрешается перейти к “выталкивающему” узлу, если его символ не совпадает с символом, расположенным на вершине стека.
В паре мест на том пути, что подсвечен выше, мы показываем содержимое символьного стека. Самое важное, что, когда мы доходим до той части графа, где содержатся узлы определений saute, broil и bake, символьный стек содержит ⟨broil⟩, гарантируя, что только валидный путь из всех обнаруженных нами окончится на определении broil.
Также можно использовать различные структуры графов, чтобы обработать другие мои примеры. А именно:
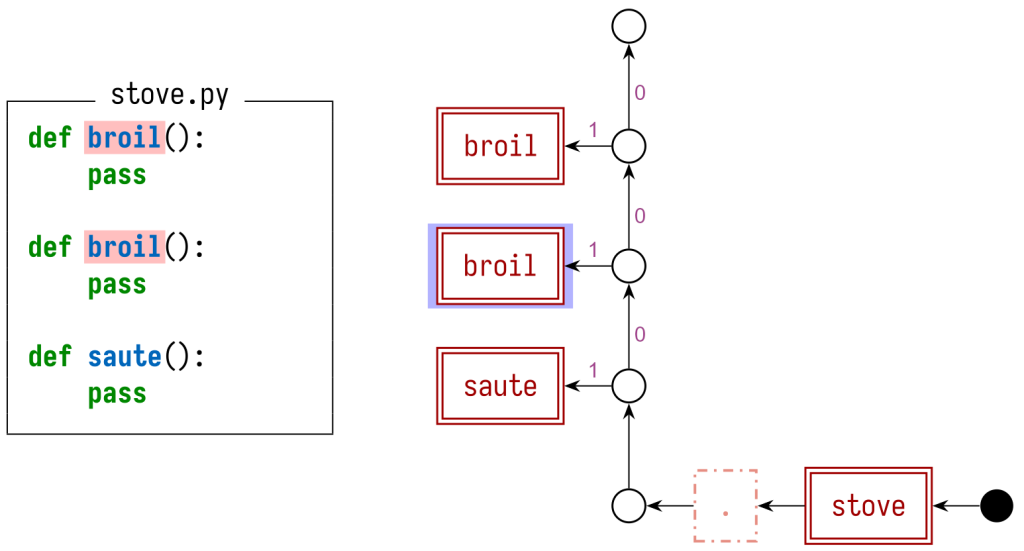
В этом графе мы аннотируем некоторые из ребер, присваивая им значение приоритета. Пути, в которых содержатся ребра с более высоким значением приоритета, предпочтительны по сравнению с теми, в которых значения приоритета ниже. Это позволяет нам правильно обработать поведение затенения, предусмотренное в Python.
Что касается других языков программирования, не реализующих такое же поведение затенения как Python, сущности будут соединяться ребрами в соответствии с иным паттерном. Например, вот как выглядел бы стековый граф для моего более раннего примера на Rust:
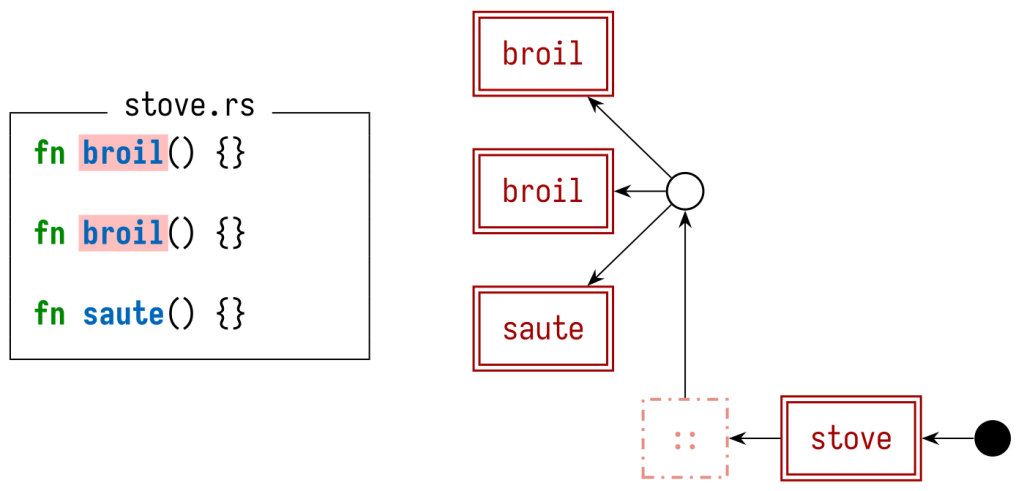
Для того, чтобы смоделировать правило Rust, в соответствии с которым одноименные определения высшего уровня приводят к конфликту, у нас есть всего один узел, с которого свешиваются все определения. При помощи значений приоритета можно выбрать, показать ли все конфликтующие определения (присвоив им всем одинаковые значения приоритета), либо только первое (присваивая значения приоритета последовательно).
Имея стековый граф, можно реализовать возможность «перейти к определению»:
- Пользователь щелкает по ссылке.
- Мы загружаем стековые графы для каждого из файлов в коммите и консолидируем их.
- Выполняем поиск пути, начиная со ссылочного узла, соответствующего тому символу, по которому щелкнул пользователь, учитывая при этом символьные стеки и значения приоритета – так гарантируется, что мы не создадим никаких недействительных путей.
- Все действительные пути, которые мы найдем, ведут к определениям, на которые указывает ссылка. Их мы отобразим во всплывающей подсказке.
Создание стековых графов при помощи Tree-sitter
Я описал, как использовать стековые графы для выполнения навигации в коде, но еще не упомянул, как их создавать из исходного кода, который вы загружаете на GitHub.
Для этого обратимся к Tree-sitter свободному фреймворку для синтаксического разбора (парсинга) кода. Сообщество Tree-sitter уже написало парсеры для самых разнообразных языков программирования, и мы уже используем Tree-sitter во многих частях GitHub. Поэтому естественно выбрать этот фреймворк для построения стековых графов на его основе.
Парсеры Tree-sitter уже позволяют нам эффективно разбирать код, загружаемый нашими пользователями. Например, парсер Tree-sitter для Python строит конкретное синтаксическое дерево (CST) для файла stove.py:
$ tree-sitter parse stove.py
(module [0, 0] - [10, 0]
(function_definition [0, 0] - [1, 8]
name: (identifier [0, 4] - [0, 8])
parameters: (parameters [0, 8] - [0, 10])
body: (block [1, 4] - [1, 8]
(pass_statement [1, 4] - [1, 8])))
(function_definition [3, 0] - [4, 8]
name: (identifier [3, 4] - [3, 9])
parameters: (parameters [3, 9] - [3, 11])
body: (block [4, 4] - [4, 8]
(pass_statement [4, 4] - [4, 8])))
(function_definition [6, 0] - [7, 8]
name: (identifier [6, 4] - [6, 9])
parameters: (parameters [6, 9] - [6, 11])
body: (block [7, 4] - [7, 8]
(pass_statement [7, 4] - [7, 8]))))
Tree-sitter также предоставляет язык запросов, позволяющий нам отыскивать паттерны внутри CST:
(function_definition name: (identifier) @name) @function
Этот запрос нашел бы все три определения методов из нашего примера, аннотировав каждое определение в целом при помощи метки @function, а имя каждого метода при помощи метки @name.
В рамках разработки стековых графов мы добавили в Tree-sitter новый язык конструирования графов, на котором можно собирать произвольные графоподобные структуры (в том числе и стековые графы – но не только) из разобранных конкретных синтаксических деревьев. Существуют стансы, то есть, строки, определяющие конкретные признаки тех узлов и ребер графа, которые должны создаваться на основании каждого найденного запроса Tree-sitter и определяющие, как новоиспеченные узлы и ребра должны присоединяться к уже имеющейся структуре графа. Например, следующий фрагмент кода создаст узел с определением стекового графа для моего примера с определениями методов на Python:
(function_definition
name: (identifier) @name) @function
{
node @function.def
attr (@function.def) kind = "definition"
attr (@function.def) symbol = @name
edge @function.containing_scope -> @function.def
}
При помощи такого подхода можно инкрементно создавать стековые графы для каждого файла исходников, который мы получаем. При этом нам приходится анализировать только содержимое исходников, не прибегая к какому-либо инструментарию, специфичному для языка, либо к системам сборки. (Единственная языково-специфичная деталь здесь – это набор правил построения графов для конкретного языка!)
И это еще не все!
Этот пост уже получился достаточно длинным, а мы лишь слегка копнули тему. Возможно, у вас возникли такие вопросы:
- Выполнение полноценного поиска пути при каждом запросе «перейти к определению» кажется расточительным. Можем ли мы предварительно рассчитать больше информации за время индексирования, не жертвуя при этом инкрементностью?
- Все приведенные примеры очень тривиальны. Позволяет ли такой метод справиться с более сложными примерами?
Что, например, делать со следующим файлом на Python, где приходится использовать поток данных, чтобы отследить, какое именно значение было передано passthrough в качестве параметра и, соответственно, корректно разрешить ссылку в one в последней строке?
def passthrough(x): return x class A: one = 1 passthrough(A).one
Либо следующий файл на Java, где нам требуется отследить наследование и параметры обобщенных типов, чтобы посмотреть, должна ли ссылка на length разрешаться в String.length из стандартной библиотеки Java?
import java.util.HashMap;
class MyMap extends HashMap<String, String> {
int firstLength() {
return this.entrySet().iterator().next().getKey().length();
}
}