Знакомимся с дата-ориентированным проектированием на примере Rust
Автор: Shyhartskoi / Автор оригинала: James McMurrayВ этом посте мы исследуем основные концепции «Data-Oriented Design» (далее «дата-ориентированное проектирование» на языке Rust.
Весь исходный код для этого поста выложен на Github.
Что такое дата-ориентированное проектирование?
Дата-ориентированное проектирование – это подход к оптимизации программ, предполагающий, что расположение структур данных в памяти должно тщательно оптимизироваться. Также требуется учитывать, как такой подход отражается на автоматической векторизации и использовании кэша ЦП. Настоятельно рекомендую посмотреть лекцию Майка Эктона «Data-Oriented Design and C++», если вы ее еще не видели.
В этом посте будет рассмотрено 4 случая, и для бенчмаркинга будет применяться библиотека criterion. Эти случаи таковы:
- Структура массивов и массив структур – в чем разница;
- Цена ветвления внутри горячего цикла;
- Сравнение связного списка и перебора вектора;
- Сравнение цены динамической диспетчеризации и мономорфизации.
Структура массивов и массив структур
В примере со структурой массивов и массивом структур мы говорим о двух контрастных способов организации данных объекта, над которыми будут производиться операции.
Представьте, например, что мы пишем видеоигру и хотели бы иметь структуру Player со следующими полями:
pub struct Player {
name: String,
health: f64,
location: (f64, f64),
velocity: (f64, f64),
acceleration: (f64, f64),
}
Тогда в каждом кадре мы собираемся обновлять положения и скорости каждого из Players. Можно было бы написать нечто подобное:
pub fn run_oop(players: &mut Vec<Player>) {
for player in players.iter_mut() {
player.location = (
player.location.0 + player.velocity.0,
player.location.1 + player.velocity.1,
);
player.velocity = (
player.velocity.0 + player.acceleration.0,
player.velocity.1 + player.acceleration.1,
);
}
}
Это был бы обычный объектно-ориентированный подход к данной задаче. Проблема в том, что в памяти структуры хранятся следующим образом (предполагается, что не происходит никакого переупорядочивания полей, т. е. #[repr©]), в 64-разрядной архитектуре в каждом поле будет по 64 бита (8 байт, так что у каждого Player 64 байт):
-- Vec<Player> name (pointer to heap) -- Player 1 health location0 (tuple split for clarity) location1 velocity0 velocity1 acceleration0 acceleration1 name (pointer to heap) -- Player 2 location0 location1 velocity0 velocity1 acceleration0 acceleration1 ...
Обратите внимание: те части кода, которыми мы собираемся оперировать (позиции, скорости и ускорения) для различных игроков не хранятся одним непрерывным куском. Это не позволяет нам воспользоваться векторными операциями при обращении с несколькими игроками одновременно (поскольку они не могут в одно и то же время быть загружены в одну кэш-линию ЦП, ведь ее обычный размер составляет около 64 байт).
Напротив, дата-ориентированный метод предполагает проектирование в обход данного ограничения и оптимизацию с упором на автовекторизацию. Вместо того, чтобы использовать по структуре на игрока, мы применяем одну структуру на всех игроков, и значения для каждого игрока будут храниться по соответствующему индексу в отдельном атрибуте Vectors:
pub struct DOPlayers {
names: Vec<String>,
health: Vec<f64>,
locations: Vec<(f64, f64)>,
velocities: Vec<(f64, f64)>,
acceleration: Vec<(f64, f64)>,
}
Теперь можно сделать те же вычисления, как и при ООП-подходе, вот так:
pub fn run_dop(world: &mut DOPlayers) {
for (pos, (vel, acc)) in world
.locations
.iter_mut()
.zip(world.velocities.iter_mut().zip(world.acceleration.iter()))
{
*pos = (pos.0 + vel.0, pos.1 + vel.1);
*vel = (vel.0 + acc.0, vel.1 + acc.1);
}
}
В данном случае имеем такую компоновку в памяти:
-- DOPlayers name1 -- names name2 ... health1 -- health health2 ... location1 -- locations location2 ...
Теперь все релевантные поля сохранены сплошным куском. Учитывая, что размер каждого кортежа местоположений составит 16 байт, теперь вполне реально загрузить 4 таких кортежа в одну и ту же кэш-линию, чтобы оперировать ими одновременно при помощи ОКМД-команд.
Бенчмарк
Вот результаты бенчмарка для библиотеки criterion в вышеприведенном коде (полный код и код бенчмарка доступны в репозитории Github):

Вообще, как видим, при помощи дата-ориентированного подхода мы смогли управиться за половину времени. Вероятно, дело в том, что в дата-ориентированном случае мы оперируем над двумя игроками одновременно – если хочется в этом убедиться, можно просто посмотреть скомпилированный ассемблерный код.
Просматривая вывод в Godbolt, видим следующее:
// Релевантный цикл в ООП
.LBB0_2:
movupd xmm0, xmmword ptr [rax + rdx + 32]
movupd xmm1, xmmword ptr [rax + rdx + 48]
movupd xmm2, xmmword ptr [rax + rdx + 64]
addpd xmm0, xmm1
movupd xmmword ptr [rax + rdx + 32], xmm0
addpd xmm2, xmm1
movupd xmmword ptr [rax + rdx + 48], xmm2
add rdx, 80
cmp rcx, rdx
jne .LBB0_2
// ...
// Релевантный цикл в ДОП
.LBB1_7:
movupd xmm0, xmmword ptr [rcx + rdx - 16]
movupd xmm1, xmmword ptr [rax + rdx - 16]
addpd xmm1, xmm0
movupd xmmword ptr [rcx + rdx - 16], xmm1
movupd xmm0, xmmword ptr [r9 + rdx - 16]
movupd xmm1, xmmword ptr [rax + rdx - 16]
addpd xmm1, xmm0
movupd xmm0, xmmword ptr [rax + rdx]
movupd xmmword ptr [rax + rdx - 16], xmm1
add rdi, 2
movupd xmm1, xmmword ptr [rcx + rdx]
addpd xmm1, xmm0
movupd xmmword ptr [rcx + rdx], xmm1
movupd xmm0, xmmword ptr [rax + rdx]
movupd xmm1, xmmword ptr [r9 + rdx]
addpd xmm1, xmm0
movupd xmmword ptr [rax + rdx], xmm1
add rdx, 32
cmp rsi, rdi
jne .LBB1_7
test r8, r8
je .LBB1_5
Как видим, в дата-ориентированном случае цикл разматывается так, чтобы оперировать двумя элементами одновременно – благодаря чему достигается общее 50%-е ускорение кода!
Авторское дополнение: как было отмечено в /u/five9a2 на Reddit, вышеприведенный вывод специфичен для цели, заданной по умолчанию – и это сбивает, поскольку cargo bench по умолчанию использует нативную цель (т. e., все возможные фичи нашего ЦП), так что в бенчмарках не применяется вышеуказанный ассемблерный код.
Установив флаг компилятора в значение -C target-cpu=skylake-avx512, чтобы активировать возможности Skylake, получим следующий вывод:
// ООП-цикл
.LBB0_2:
vmovupd ymm0, ymmword ptr [rax + rdx + 32]
vaddpd ymm0, ymm0, ymmword ptr [rax + rdx + 48]
vmovupd ymmword ptr [rax + rdx + 32], ymm0
add rdx, 80
cmp rcx, rdx
jne .LBB0_2
...
// ДОП-цикл
.LBB1_19:
vmovupd zmm0, zmmword ptr [rsi + 4*rax - 64]
vaddpd zmm0, zmm0, zmmword ptr [rcx + 4*rax - 64]
vmovupd zmmword ptr [rsi + 4*rax - 64], zmm0
vmovupd zmm0, zmmword ptr [rcx + 4*rax - 64]
vaddpd zmm0, zmm0, zmmword ptr [r10 + 4*rax - 64]
vmovupd zmmword ptr [rcx + 4*rax - 64], zmm0
vmovupd zmm0, zmmword ptr [rsi + 4*rax]
vaddpd zmm0, zmm0, zmmword ptr [rcx + 4*rax]
vmovupd zmmword ptr [rsi + 4*rax], zmm0
vmovupd zmm0, zmmword ptr [rcx + 4*rax]
vaddpd zmm0, zmm0, zmmword ptr [r10 + 4*rax]
vmovupd zmmword ptr [rcx + 4*rax], zmm0
add r11, 8
add rax, 32
add rdi, 2
jne .LBB1_19
test r9, r9
je .LBB1_22
Здесь видим, что ООП-цикл использует 256-разрядные регистры ymm, в одном из которых размещает кортеж положений и кортеж скорости, а в другом – кортеж скорости и кортеж ускорения. Это возможно сделать, поскольку они смежны в памяти (благодаря тому, как именно упорядочены поля). В ДОП-цикле используется 512-разрядный регистр zmm.
Может показаться, что разница в производительности обусловлена тем, что полоса передачи данных на разных уровнях кэша отличается, ведь для маленьких примеров производительность идентична. Это можно лишний раз продемонстрировать, удалив из структуры лишние поля – в таком случае будем наблюдать разницу производительности лишь 25% (ссылка на godbolt), и это означает, что структура Player в данном случае занимает 384 разряда (следовательно, 1/4 из 512 разрядов на чтение/запись остаются неиспользованными).
Здесь стоит акцентировать, насколько важно учитывать, для какой целевой платформы развертывается приложение, и, если развертывается критичный по производительности код – попробовать явно задать target-cpu, чтобы воспользоваться всеми его возможностями.
Также здесь демонстрируется, насколько важным с точки зрения производительности может быть порядок полей. По умолчанию Rust переупорядочивает поля автоматически, но, чтобы этого не происходило, можно установить #[repr(C)] (например, это необходимо для интероперабельности с C).
Итог примера
В этом примере продемонстрировано, насколько важно учитывать компоновку данных в памяти, если требуется высокопроизводительный код и автоматическая векторизация.
Обратите внимание: та же логика применима к работе с массивами структур – если вы уменьшите вашу структуру, то сможете загрузить больше элементов в одну и ту же кэш-линию, что может поспособствовать автовекторизации. Вот пример контейнера (которым поделились в одном подреддите по Rust), производительность которого удалось повысить на 40%, ограничившись лишь этой операцией.
Данная конкретная реорганизация прямо перекликается с проектированием баз данных. Серьезное отличие между базами данных, приспособленными для транзакционных (OLTP) и аналитических (OLAP) рабочих нагрузок заключается в том, что при вторых данные, как правило, хранятся в колоночном виде. Как и в случае, рассмотренном выше, это означает: при операциях над столбцами можно выгодно пользоваться областями сплошного хранения данных, а также векторными операциями, и такой паттерн доступа является основным для аналитических рабочих нагрузок (например, если нужно рассчитать средний размер покупки по всем строкам, а не обновлять и не извлекать цельные конкретные строки).
На самом деле, в случае с аналитическими базами данных мы здесь выигрываем вдвойне, поскольку такой подход применим и к сериализации данных при записи их на диск. Ведь в данном случае можно осуществлять сжатие данных по столбцам (в одном столбце все данные гарантированно будут относиться к одному и тому же типу), благодаря чему можно добиться гораздо более выгодных коэффициентов сжатия.
Если вы занимаетесь решением задачи, в которой может быть полезен подход со «структурой массивов» – и хотите прогнать быстрый бенчмарк – то вас может заинтересовать контейнер soa-derive, позволяющий произвести структуру массивов из имеющейся у вас структуры.
Ветвление в горячем цикле
Другая тактика оптимизации – избегать ветвления в любых «горячих» частях кода (то есть, в участках кода, каждый из которых будет выполняться много-много раз).
Ветвление может возникать довольно неожиданным образом – например, при попытке использовать одну и ту же структуру во множестве разных случаев. Например, можно следующим образом определить некоторый общий тип Node:
enum NodeType {
Player,
PhysicsObject,
Script,
}
struct Node {
node_type: NodeType,
position: (f64, f64),
// ...
}
А затем выполнить сопоставление по шаблону с node_type, когда требуется произвести операцию над Node. Проблемы начинаются, когда у нас возникает Vec с десятками тысяч элементов, и оперировать этими элементами нам требуется в каждом кадре. Задействуя тип node.node_type, чтобы решать, какой логикой воспользоваться, необходимо выполнять такую проверку для каждого элемента (поскольку порядок экземпляров node_type внутри Vec<Node> неизвестен).
Это сравнение не только означает, должны проводить дополнительную операцию сравнения для каждого элемента, но и препятствует автовекторизации, поскольку релевантные узлы (относящиеся все к тому же типу node_type) могут храниться в памяти не сплошным куском.
При дата-ориентированном подходе требуется разделить эти узлы по node_type. В идеале нужно создать отдельную структуру на каждый тип узла, или, как минимум, развести их по отдельным векторам до входа в горячий цикл. Таким образом, нам не потребуется проверять node_type в горячем цикле, а также нам на руку может сыграть расположение узлов, которыми мы оперируем: они будут в одном непрерывном блоке памяти.
Бенчмарк
В рамках данного бенчмарка используется следующий код:
#[derive(Copy, Clone)]
pub struct Foo {
x: i32,
calc_type: CalcType,
}
#[derive(Copy, Clone)]
pub enum CalcType {
Identity,
Square,
Cube,
}
// ...
pub fn run_mixed(x: &[Foo]) -> Vec<i32> {
x.into_iter()
.map(|x| match x.calc_type {
CalcType::Identity => x.x,
CalcType::Square => x.x * x.x,
CalcType::Cube => x.x * x.x * x.x,
})
.collect()
}
pub fn run_separate(x: &[Foo], y: &[Foo], z: &[Foo]) -> (Vec<i32>, Vec<i32>, Vec<i32>) {
let x = x.into_iter().map(|x| x.x).collect();
let y = y.into_iter().map(|x| x.x * x.x).collect();
let z = z.into_iter().map(|x| x.x * x.x * x.x).collect();
(x, y, z)
}
Сравниваем два случая: смешанный вектор Foos и отдельный вектор Foos, разделенный split by calc_type.
Результаты бенчмарка таковы:
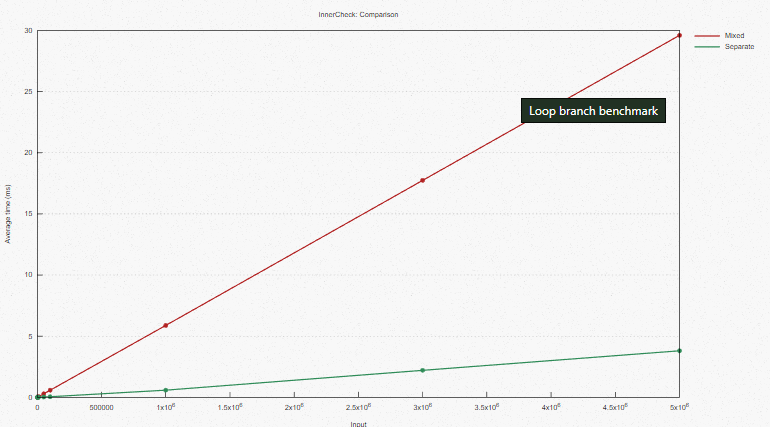
Overall, we see that the data-oriented approach finishes in about a quarter of the time.
На этот раз вывод в Godbolt получился не таким ясным, но здесь явно заметна некоторая размотка цикла в случае с отдельными Foo, а в случае со смешанными Foo она невозможна, поскольку в смешанном случае требовалось бы проверять calc_type.
Итог примера
Вам должна быть знакома концепция, при которой из горячих циклов выводятся все инструкции, какие возможно. Но этот пример также демонстрирует, как такой подход может повлиять на векторизацию.
Косвенность: перебор в связном списке
В данном примере сравнивается перебор (двойного) связного списка и работа с вектором. Этот случай хорошо известен и упоминается, например, в документации Rust по связным спискам, документации Rust по std::collections и в объявлении Learn Rust With Entirely Too Many Linked Lists’ Public Service Announcement. В последнем документе освещено множество случаев, в которых принято использовать связные списки, поэтому рекомендую прочитать его, если вы еще не успели. Тем не менее, поверьте моему опыту, лучше посмотреть сам бенчмарк.
В связном списке элементы хранятся косвенно. То есть, элемент хранится вместе с указателем на следующий элемент. Таким образом, элементы, последовательно расположенные в связном списке, не хранятся в последовательных участках памяти.
Это приводит нас к двум факторам, осложняющим векторизацию:
- Элементы связного списка могут быть сохранены в произвольном порядке, далеко друг от друга. Поэтому мы не сможем просто загрузить в кэш ЦП блок памяти, чтобы оперировать всеми этими элементами одновременно.
- Чтобы получить следующий элемент списка, требуется разыменовать указатель на него.
Например, можно следующим образом сохранить в куче вектор из i32 (удерживая в стеке указатель на начало вектора, емкость вектора и длину вектора):
0x00 1 0x01 2 0x02 3 ...
Значения хранятся сплошным куском, тогда как для (одно)связного списка у нас мог бы сложиться следующий случай.
0x00 1 0x01 0x14 0x0C 3 0x0D 0 ... 0x14 2 0x15 0x0C
Здесь значения не хранятся в непрерывном участке в памяти (более того, их порядок может не совпадать с тем, в котором расположены в списке указатели на них).
Бенчмарк
В данном случае бенчмарк очень прост: мы просто возводим в квадрат все элементы связного списка и вектора:
pub fn run_list(list: &mut LinkedList<i32>) {
list.iter_mut().for_each(|x| {
*x = *x * *x;
});
}
pub fn run_vec(list: &mut Vec<i32>) {
list.iter_mut().for_each(|x| {
*x = *x * *x;
});
}
Результаты таковы:

В целом видим, что при дата-ориентированном подходе нам требуется вдесятеро меньше времени, чем при объектно-ориентированном.
Вывод в Godbolt показывает в случае с Vec такую размотку, которая невозможна в случае с LinkedList.
Итог примера
Этот случай хорошо известен, и в нем наблюдается наибольшая разница между двумя бенчмарками. Обратите внимание: здесь мы оцениваем только перебор, а не другие операции, которые смотрелись бы несколько лучше именно в случае связного списка. Такова, например, вставка, при которой в связном списке избегаются (амортизированные) издержки на изменение размера вектора. Правда, как утверждается в Learn Rust With Entirely Too Many Linked Lists, этого можно избежать и при работе с векторами.
Надеюсь, этот момент станет общеизвестным, и на собеседованиях станет поменьше вопросов и практических задач на связные списки и косвенность, ведь они учитывают только сложность задачи по «Big O», а не реальную производительность.
Косвенность: сравнение динамической диспетчеризации и мономорфизации
Когда мы пишем обобщенные функции (например, для любых типов, реализующих определенные типажи), у нас есть выбор между динамической диспетчеризацией и мономорфизацией.
Динамическая диспетчеризация позволяет работать со смешанной коллекцией объектов-типажей. То есть, у нас может быть Vec<Box<dyn MyTrait>>, в котором могут содержаться ссылки на различные типы, и все эти типы реализуют MyTrait. Объект-типаж содержит указатель на экземпляр структуры как таковой (реализующей MyTrait) и указатель на таблицу виртуальных методов структуры (она же vtable, таблица поиска, указывающая на реализацию каждого метода в MyTrait). Затем, когда мы вызываем метод в одном из этих объектов-типажей, во время выполнения выясняется, какую именно реализацию метода мы будем использовать, и эта реализация подыскивается в vtable.
Обратите внимание: это приводит нас к косвенности. Наш вектор должен состоять из указателей на сами экземпляры структуры (поскольку разные структуры, реализующие MyTrait, могут отличаться как по размеру, так и по полям). Также нам приходится разыменовывать указатель в vtable, чтобы выяснить, какую реализацию вызывать.
В свою очередь, мономорфизация – это создание отдельной реализации обобщенной функции на каждый возможный тип. Например, в следующем коде фактически создается две отдельные функции для run_vecs_square(): для типов Foo и Bar соответственно:
pub struct Foo {
id: usize,
}
pub struct Bar {
id: usize,
}
pub trait MyTrait {
fn square_id(&mut self);
}
impl MyTrait for Foo {
fn square_id(&mut self) {
self.id = self.id * self.id;
}
}
impl MyTrait for Bar {
fn square_id(&mut self) {
self.id = self.id * self.id * self.id;
}
}
pub fn run_vecs_square<T: MyTrait>(x: &mut Vec<T>) {
x.iter_mut().for_each(|x| x.square_id())
}
В результате увеличивается размер двоичного файла, зато нам становится просто генерировать множественные реализации функции для разных типов, а также избегать косвенности (например, обратите внимание: можно использовать Vec<Tgt; и при этом обходиться без Vec<Box<T>>).
А вот в следующем коде используется динамическая диспетчеризация. Там всего одна реализация run_dyn_square, но, какую именно реализацию square_id() следует вызывать – определяется во время исполнения, по итогам сверки с таблицей vtable объекта-типажа.
pub fn run_dyn_square(x: &mut Vec<Box<dyn MyTrait>>) {
x.iter_mut().for_each(|x| x.square_id())
}
Так может быть удобнее, поскольку мы создаем вектор, содержащий ссылки на различные типы – и можем не беспокоиться, каковы именно конкретные типы (нам важно лишь то, что они реализуют MyTrait), поэтому и двоичный файл у нас не разбухает. Правда, мы вынуждены прибегать к косвенности, поскольку у базовых типов могут быть разные размеры – а, как мы видели в примере с LinkedList, это может существенным образом сказываться на автовекторизации.
Бенчмарк
При прогоне вышеприведенного примера бенчмарк выглядит так:
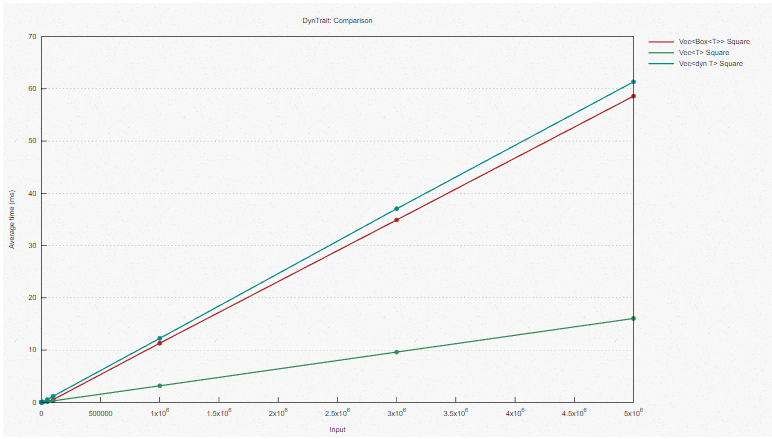
В целом видим, что на выполнение мономорфизированного примера нужно примерно вчетверо меньше времени, чем на вариант с динамической диспетчеризацией. Мономорфизированный случай с применением косвенности (Vec<Box<T>>) только чуть-чуть быстрее случая с динамической диспетчеризацией, и именно дополнительной косвенностью обусловлен в основном провал производительности – ведь косвенность мешает векторизации. В свою очередь, при поиске в vtable добавляются лишь небольшие издержки, и они постоянны.
К сожалению, в данном случае Godbolt не включает в сгенерированный вывод целевые функции.
Итог примера
Этот бенчмарк показывает, что основные издержки динамической диспетчеризации связаны с осложнением векторизации, так как такой подход обязательно требует косвенности. А издержки на поиск в таблице vtable относительно невелики.
Таким образом, определенно попробуйте проектировать с прицелом на мономорфизацию, если операции ваших методов именно таковы, что им сильно пошла бы на пользу векторизация (как, например, математические операции, показанные выше). С другой стороны, если нужно выполнять операции, которые не векторизуются (например, составлять строки), то издержки на динамическую диспетчеризацию могут в целом оказаться пренебрежимыми.
Как всегда, расставляйте бенчмарки для конкретных практических случаев и паттернов доступа, когда сравниваете различные возможные реализации.
Заключение
В этой статье было рассмотрено четыре случая, в которых при учете расположения данных в памяти, а также реального состояния и слабых сторон кэша ЦП удалось существенно повысить производительность.
Здесь мы только слегка копнули дата-ориентированное проектирование и оптимизацию. В частности, не были затронуты вопросы упаковки структур, расстановки отступов и выравнивания. Книга Ричарда Фабиана о дата-ориентированном проектировании также освещает некоторые дополнительные темы.
Важно отметить, что во всех рассмотренных здесь примерах мы не дорабатывали алгоритмов, которыми пользовались. У всех реализаций на все случаи была одинаковая алгоритмическая сложность по Big O, но на практике их производительность может быть ускорена в 2-10 раз – благодаря несложной оптимизации, рассчитанной только на векторизацию и другие возможности современных ЦП.