Знаете ли вы, как выбрать правильный алгоритм машинного обучения среди 7 различных типов?
Coding
Это общий практический подход, который можно применять к большинству проблем машинного обучения:

Классификация проблем
Категоризировать по входу: Если это помеченные данные, это контролируемая проблема обучения. Если это немеченые данные с целью нахождения структуры, это неконтролируемая проблема обучения. Если решение подразумевает оптимизацию целевой функции путем взаимодействия с окружающей средой, это проблема обучения с подкреплением.
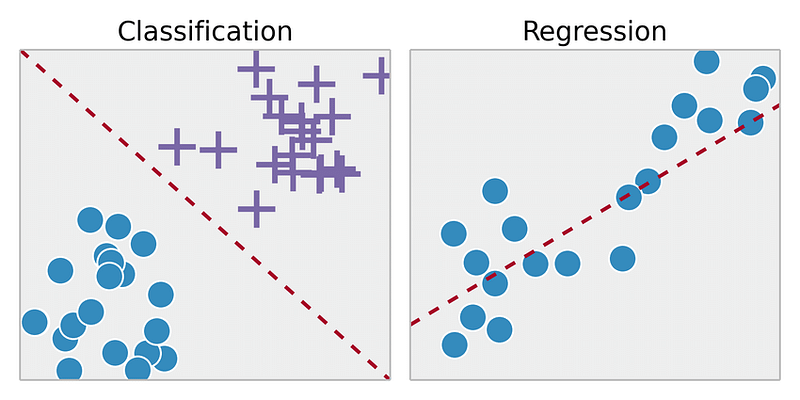
Категоризировать по выводам: Если выходные данные модели являются числом, это проблема регрессии. Если выходные данные модели являются классом, это проблема классификации. Если выходные данные модели представляют собой набор входных групп, это проблема кластеризации.
Нужно понять данные
Данные сами по себе являются не конечной игрой, а скорее сырьем во всем процессе анализа. Успешные компании не только собирают и имеют доступ к данным, но и могут получать информацию, которая способствует принятию более эффективных решений, что приводит к лучшему обслуживанию клиентов, конкурентной дифференциации и более высокому росту доходов.
Процесс понимания данных играет ключевую роль в процессе выбора правильного алгоритма для правильной задачи.
Некоторые алгоритмы могут работать с меньшими наборами выборок, в то время как другие требуют тонны и тонны выборок. Некоторые алгоритмы работают с категориальными данными, в то время как другие любят работать с числовым вводом.
Анализируйте данные
На этом этапе выполняются две важные задачи: понять данные с помощью описательной статистики и понять данные с помощью визуализации и графиков.
Обработать данные
Компоненты обработки данных включают в себя предварительную обработку, профилирование, очистку, часто это также включает в себя сбор данных из разных внутренних систем и внешних источников.
Преобразовать данные
Традиционная идея преобразования данных из необработанного состояния в состояние, подходящее для моделирования, - это то место, где подходит разработка признаков.
Фактически преобразование данных и разработка признаков могут быть синонимами. И вот определение последней концепции.
Разработка функций - это процесс преобразования необработанных данных в функции, которые лучше представляют основную проблему для прогнозных моделей, что приводит к повышению точности модели на невидимых данных.
Найти доступные алгоритмы
После категоризации проблемы и понимания данных следующим этапом является определение алгоритмов, которые применимы и практичны для реализации в разумные сроки. Некоторые элементы, влияющие на выбор модели:
- Точность модели.
- Интерпретируемость модели.
- Сложность модели.
- Масштабируемость модели.
- Сколько времени нужно, чтобы построить, обучить и протестировать модель?
- Сколько времени нужно, чтобы делать прогнозы, используя модель?
- Модель соответствует бизнес-цели?
Реализуйте алгоритмы машинного обучения.
Настройте конвейер машинного обучения, который сравнивает производительность каждого алгоритма в наборе данных, используя набор тщательно выбранных критериев оценки.
Другой подход заключается в использовании одного и того же алгоритма в разных подгруппах наборов данных.
Лучшее решение для этого - сделать это один раз или запустить службу, которая делает это через определенные промежутки времени, когда добавляются новые данные.
Оптимизировать гиперпараметры
Существует три варианта оптимизации гиперпараметров, поиска по сетке, случайного поиска и байесовской оптимизации.
Типы задач машинного обучения:
- Контролируемое обучение
- Неконтролируемое обучение
- Обучение подкреплению
Контролируемое обучение
Контролируемое обучение названо так, потому что человек действует как руководство, чтобы научить алгоритм, к каким выводам он должен прийти.
Обучение под наблюдением требует, чтобы возможные выходные данные алгоритма уже были известны и чтобы данные, используемые для обучения алгоритма, уже были помечены с правильными ответами.
Если вывод является действительным числом, мы называем регрессию задачи. Если выходные данные получены из ограниченного числа значений, где эти значения неупорядочены, то это классификация.
cation.
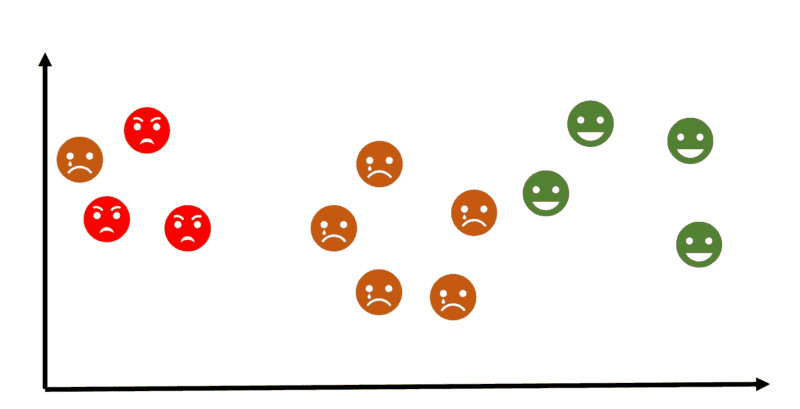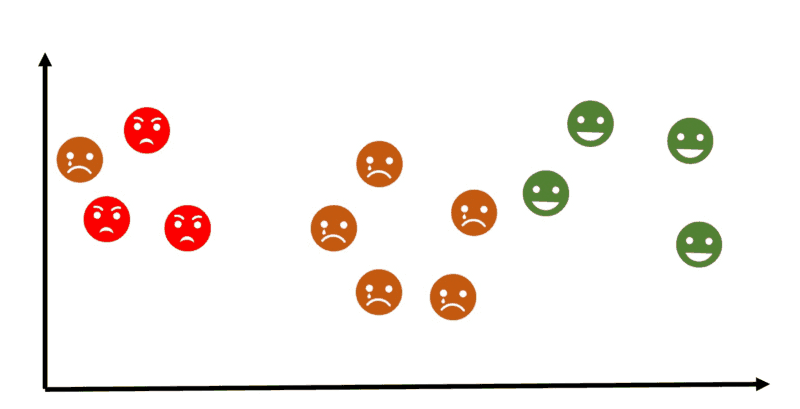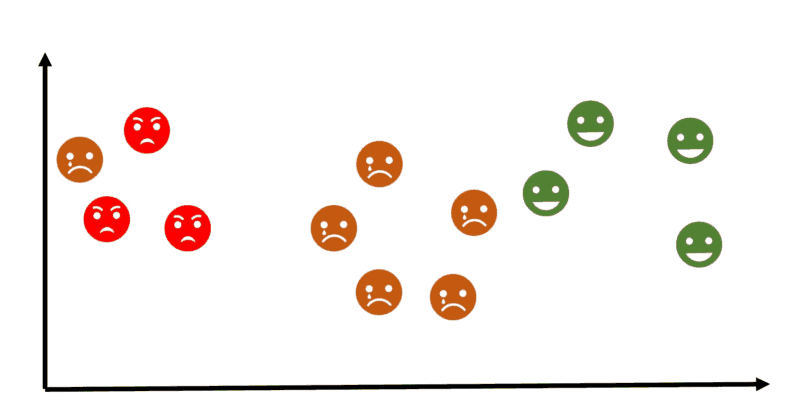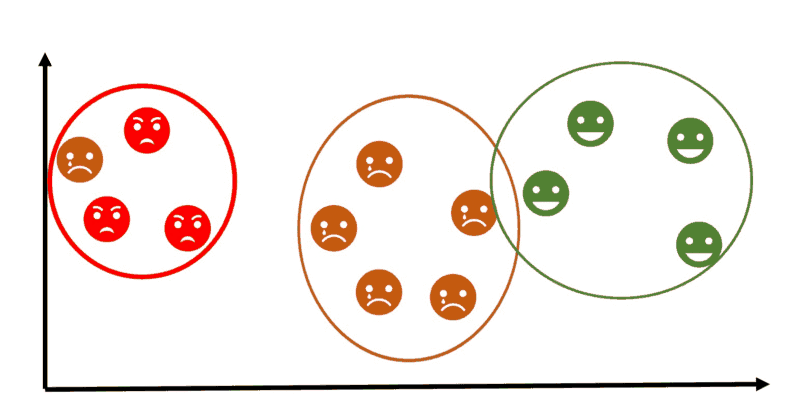
Неконтролируемое обучение
Неуправляемое машинное обучение более тесно связано с тем, что некоторые называют истинным искусственным интеллектом - идеей о том, что компьютер может научиться распознавать сложные процессы и модели без помощи человека, который бы давал указания на этом пути.
Меньше информации об объектах, в частности, поезд без маркировки. Можно наблюдать некоторые сходства между группами объектов и включать их в соответствующие кластеры. Некоторые объекты могут сильно отличаться от всех кластеров, поэтому эти объекты могут быть аномалиями.
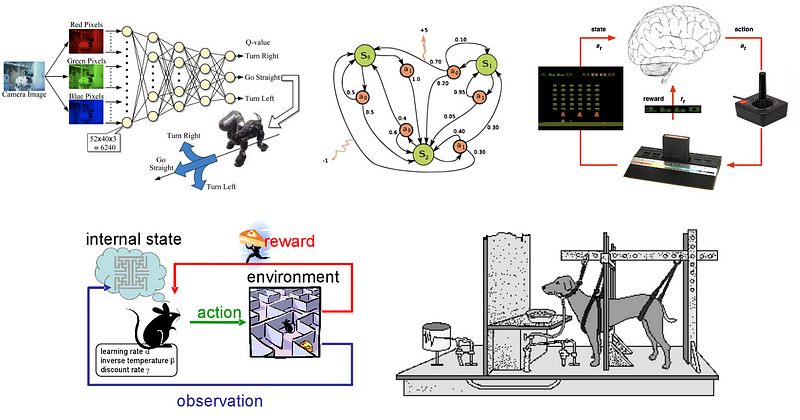
Обучение подкреплению
Усиленное обучение относится к целевым алгоритмам, которые учатся, как достигать сложной цели или максимизировать в определенном измерении за много шагов.Например, максимизируйте очки, выигранные в игре за много ходов.
Он отличается от контролируемого обучения тем, что в контролируемом обучении обучающие данные имеют ключевой ключ, поэтому модель обучается с правильным ответом, тогда как в обучении с подкреплением нет ответа, но агент подкрепления решает, что делать с выполненные задания. В отсутствие обучающего набора данных он должен учиться на своем опыте.
Обычно используемые алгоритмы машинного обучения
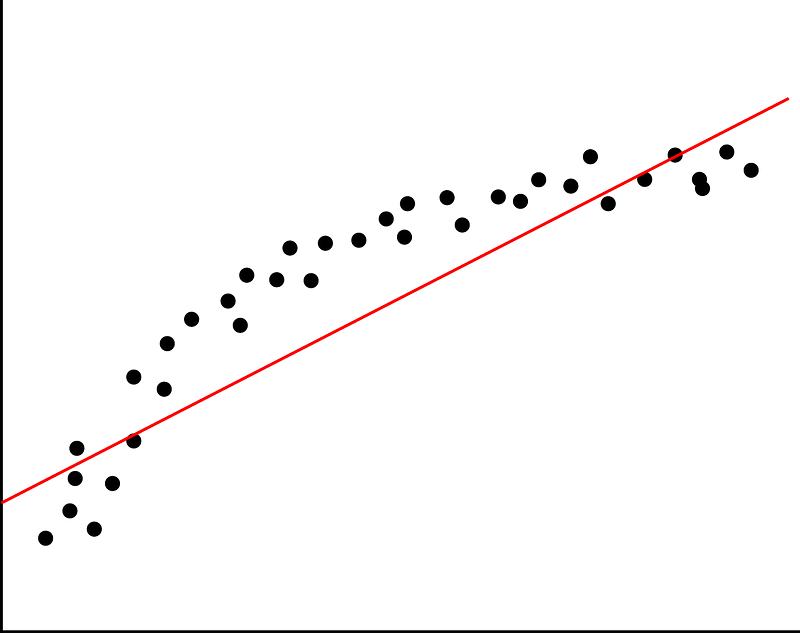
Линейная регрессия
Линейная регрессия - это статистический метод, который позволяет суммировать и изучать отношения между двумя непрерывными (количественными) переменными: одна переменная, обозначенная X, рассматривается как независимая переменная. Другая переменная, обозначенная Y, рассматривается как зависимая переменная.
Линейная регрессия использует одну независимую переменную X, чтобы объяснить или предсказать результат зависимой переменной Y, в то время как множественная регрессия использует две или более независимых переменных, чтобы предсказать результат в соответствии с функцией потерь, такой как среднеквадратическая ошибка (MSE) или средняя абсолютная ошибка (MAE).
Таким образом, всякий раз, когда вам говорят прогнозировать какое-то будущее значение процесса, который в данный момент выполняется, вы можете использовать алгоритм регрессии.
Несмотря на простоту этого алгоритма, он работает довольно хорошо, когда есть тысячи функций, например, пакет слов или n-грамм в обработке естественного языка.
Более сложные алгоритмы страдают от перегрузки многих функций, а не огромных наборов данных, в то время как линейная регрессия обеспечивает достойное качество. Тем не менее, нестабильно, если функции избыточны.
Логистическая регрессия
Не путайте эти алгоритмы классификации с методами регрессии для использования регрессии в ее названии.
Логистическая регрессия выполняет двоичную классификацию, поэтому выходные данные меток являются двоичными.
Мы также можем рассматривать логистическую регрессию как особый случай линейной регрессии, когда выходная переменная является категориальной, где мы используем журнал шансов в качестве зависимой переменной.
Что удивительного в логистической регрессии? Он принимает линейное сочетание функций и применяет к нему нелинейную функцию, так что это крошечный экземпляр нейронной сети!

K-means clustering
Скажем, у вас есть много точек данных (измерения для фруктов), и вы хотите разделить их на две группы яблок и груш.
K-means clustering - это алгоритм кластеризации, используемый для автоматического разделения большой группы на более мелкие.
Название происходит потому, что вы выбираете K групп в нашем примере K = 2. Вы берете среднее значение этих групп для повышения точности группы (среднее значение равно среднему, и вы делаете это несколько раз). Кластер - это просто другое название группы.
Допустим, у вас есть 13 точек данных, которые на самом деле представляют собой семь яблок и шесть груш (но вы этого не знаете), и вы хотите разделить их на две группы.
Для этого примера давайте предположим, что вся груша больше, чем все яблоки. Вы выбираете две случайные точки данных в качестве начальной позиции.
Затем вы сравниваете эти точки со всеми остальными точками и выясняете, какая начальная позиция является ближайшей. Это ваш первый проход в кластеризации, и это самая медленная часть.
У вас есть начальные группы, но поскольку вы выбрали случайным образом, вы, вероятно, неточны.
Скажем, у вас есть шесть яблок и одна груша в одной группе, и два яблока и четыре груши в другой.
Таким образом, вы берете среднее значение всех точек в одной группе для использования в качестве новой отправной точки для этой группы и делаете то же самое для другой группы.
Затем вы делаете кластеризацию снова, чтобы получить новые группы.
Успех! Поскольку среднее значение ближе к большинству каждого кластера, на втором круге вы получите все яблоки в одной группе и все груши в другой.
Как вы знаете, что вы сделали?
Вы делаете среднее и снова выполняете группу и смотрите, изменили ли какие-либо точки группы. Ни один не сделал, так что вы закончили.
В противном случае, вы бы повторили снова.

KNN
K-nearest neighbors это алгоритм классификации, который является подмножеством контролируемого обучения
K-means - это алгоритм кластеризации, который является подмножеством обучения без учителя.
Если у нас есть набор данных о футболистах, их позициях и их измерениях, и мы хотим назначить позиции футболистам в новом наборе данных, где у нас есть измерения, но нет позиций, мы можем использовать K-nearest neighbors
С другой стороны, если у нас есть набор данных о футболистах, которых нужно сгруппировать в K отдельных групп на основе сходства, мы могли бы использовать K-средства. Соответственно, К в каждом случае также означают разные вещи!
K представляет количество соседей, которые имеют право голоса при определении позиции нового игрока. Проверьте пример, где K = 5.
Если у нас есть новый футболист, которому нужна позиция, мы берем пять футболистов в нашем наборе данных с измерениями, ближайшими к нашему новому футболисту, и мы заставляем их голосовать за позицию, которую мы должны назначить новому игроку.
В K-means K означает количество кластеров, которые мы хотим иметь в конце. Если K = 7, после запуска алгоритма в моем наборе данных у меня будет семь кластеров или отдельных групп футболистов.
В конце концов, два разных алгоритма с двумя совершенно разными целями, но тот факт, что они оба используют K, может быть очень запутанным.

Опорные векторные машины
VM использует гиперплоскости (прямые вещи) для разделения двух точек с разными метками (X и O).
Иногда точки не могут быть разделены прямыми предметами, поэтому необходимо сопоставить их с пространством более высокого измерения (используя ядра!).
Где они могут быть разделены прямыми предметами (гиперплоскостями!). Это выглядит как извилистая линия в оригинальном пространстве, хотя это действительно прямая вещь в пространстве гораздо более высокого измерения!

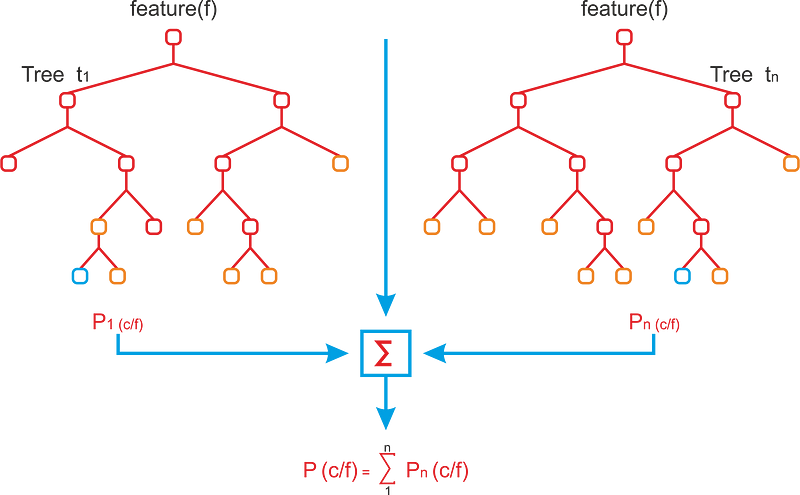
Случайный Лес
Допустим, мы хотим знать, когда инвестировать в Procter & Gamble, поэтому у нас есть три варианта покупки, продажи и удержания на основе нескольких данных за прошлый месяц, таких как цена открытия, цена закрытия, изменение цены и объема.
Представьте, что у вас много записей, 900 точек данных.
Мы хотим построить дерево решений, чтобы выбрать лучшую стратегию, например, если есть изменение цены акции более чем на десять процентов выше, чем днем ранее, при большом объеме мы покупаем эту акцию. Но мы не знаем, какие функции использовать, у нас их много.
Поэтому мы берем случайный набор мер и случайную выборку нашего учебного набора и строим дерево решений.
Затем мы делаем то же самое много раз, используя разные случайные наборы измерений и случайную выборку данных каждый раз. В итоге у нас есть много деревьев решений, мы используем каждое из них для прогнозирования цены, а затем принимаем окончательное решение на основе простого большинства.
a simple majority.
Нейронные сети
Нейронная сеть - это форма искусственного интеллекта. Основная идея нейронной сети состоит в том, чтобы моделировать множество тесно взаимосвязанных мозговых клеток внутри компьютера, чтобы он мог изучать вещи, распознавать закономерности и принимать решения в человеческом стиле.
Удивительная вещь в нейронной сети заключается в том, что ей не нужно программировать ее для явного обучения: она учится сама, как мозг!
С одной стороны нейронной сети, есть входы. Это может быть картинка, данные с дрона.
С другой стороны, есть результаты того, что нейронная сеть хочет сделать. Между ними есть узлы и связи между ними. Сила соединений определяет, какой выход вызывается на основе входов.
Заметили ошибку или есть вопросы?Рассказывай нам о них,связаться с нами ты сможешь с помощью нашего чата или же с помощью бота обратной связь
Не забывайте ставить 👍 если вам понравилась и подписаться на канал,а так же посетить наш чат.