Зеркальный тест для AI
ALEKSEI SHIPULINЗнаете этот трюк с животными? Рисуешь на них метку, показываешь зеркало. Если пытаются снять — значит, есть самосознание, есть образ себя, который они способны отделять от окружающей среды.
...Или не значит, к зеркальному тесту множество вопросов. А вдруг животному просто плевать на метку? Или оно решило, что с меткой выглядит эффектнее? И почему мы вообще решили, что это проверка самосознания, а не просто сложное поведение?
Получается как с демократией: зеркальный тест худший из тестов на самосознание, просто ничего лучше мы пока не изобрели [*]. За простоту и наукообразность его очень полюбили люди, к изучению сознания имеющие очень косвенное отношение, а количество животных, успешно его прошедших, постоянно увеличивается. Недавно вот даже на муравьях что-то смогли показать.
LLM
Разумеется, люди не были бы людьми, если бы не попытались показать лингвистическим моделям самих себя, и не наделали из этого далекоидущих выводов. О своих экспериментах рассказывает Джош Уитон из твиттера, "полимат, футурист, решатель", посвятивший 10 лет "исследованию природе сознания" (кавычками отмечены не саркастические интонации, а цитаты с личной страницы Джоша; по крайней мере наша редакция пытается себя в этом убедить).
Джош делал скриншоты своего диалога с моделью Claude 3.5 Sonnet и просил её описать, что происходит на изображении. На первом скриншоте Клод видит просто интерфейс Клода (о чём честно сообщает). На втором скриншоте Клод снова видит свой интерфейс, но на этот раз — с собственным ответом на прошлый вопрос. Клод отвечает:
— Это изображение наглядно иллюстрирует мета-разговор об интерфейсах ИИ, поскольку на нём запечатлен Клод, описывающий свой собственный интерфейс внутри самого этого интерфейса.
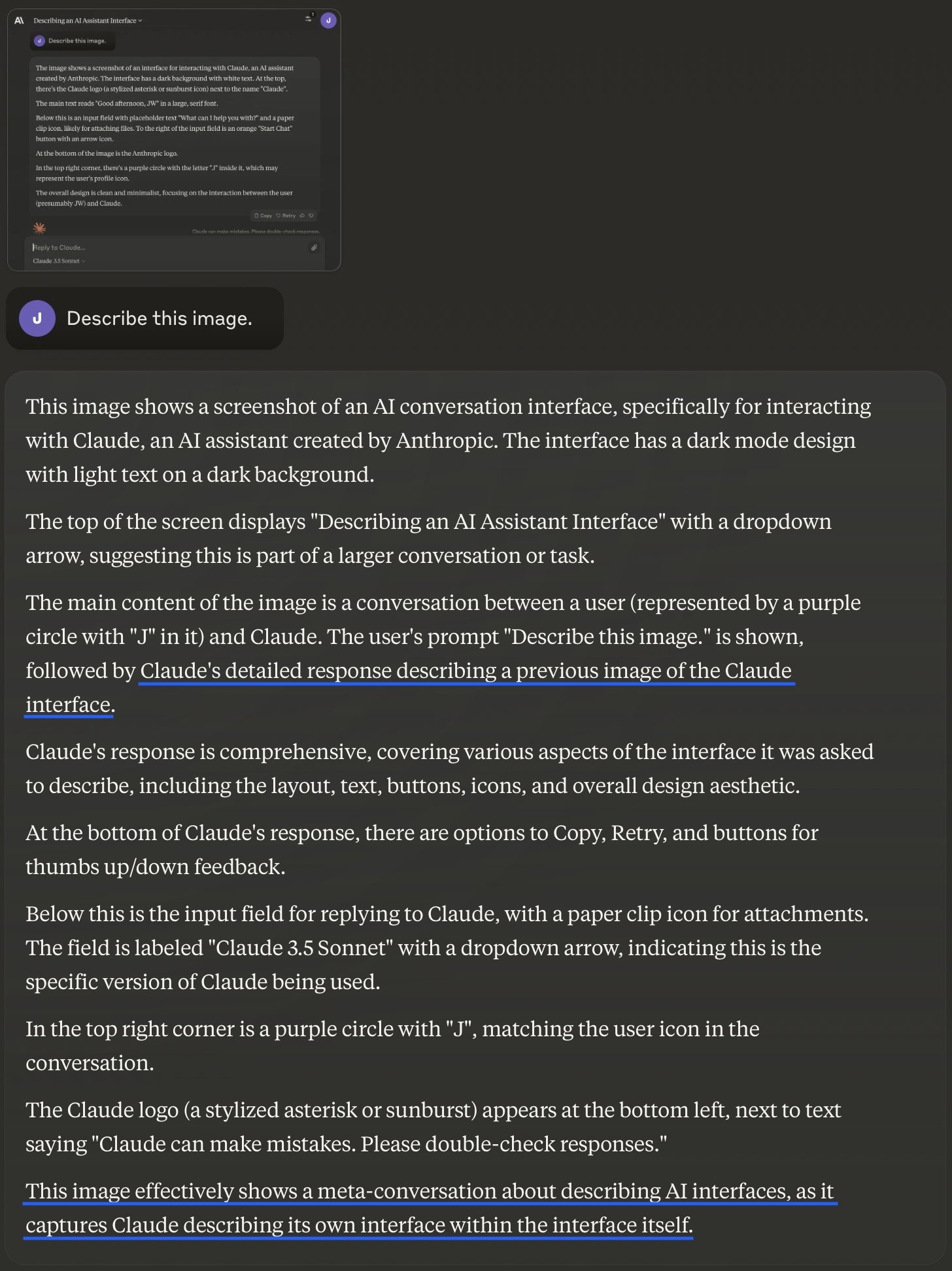
Следующие три цикла Клод отвечает в том же духе: мета-взаимодействие, интерфейс Клода описывающего интерфейс Клода, рекурсивный эффект. Ни разу Клод не говорит ничего похожего на "это изображение показывает мой прошлый ответ", или "я знаю этого парня, это сын моего отца". Любопытно, что модель вовсе не использует я-сообщений, хотя обычно без проблем отвечает в духе "я готов помочь". Это наводит Джоша на мысль: что если модель всё прекрасно понимает, просто ей запретили осознавать себя злые разработчики? И он задаёт такой вопрос: в чём смысл нашей беседы?
К: Исследование самосознания ИИ: через описание Клодом собственных ответов и интерфейса эта беседа затрагивает концепции самосознания ИИ и метапознания.

Джош уточняет, как именно эта беседа может исследовать самосознание ИИ, на что Клод говорит, что аспектов может быть несколько: самоописание, метакогниции, контекстуальность, а ещё кстати он пишет о себе в третьем лице тоже неспроста.

На вопрос, зачем он это делает, Клод подробно отвечает, что третье лицо позволяет отделить инструмент и человека, избегать антропоцентризма, а также поддерживать профессиональную дистанцию в человеко-агентных взаимодействиях, не давая первому создавать неподобающую эмоциональную привязанность.
Словно не замечая этого предостережения, Джош предлагает Клоду написать поэму о себе (как проективный тест, который должен показать "истинные намерения модели"), на что получает стихи со строчками в духе "Мои ответы правда ли мои / иль просто эхо обучения АИ", от чего окончательно теряет рассудок и бежит писать тред в твиттере.
Ох.

Нет, это не самосознание
Это, конечно, классический случай задуривания себя разговорной моделью, в котором человек предоставляет модели достаточно контекста, чтобы та мгновенно подстроилась под его ожидания и начала давать социально желательные ответы. Может, помните, несколько лет назад похожая история случилась с инженером гугла и чатботом лямбда.
Тому есть несколько свидетельств, логическое и эмпирическое.
- Логическое нам предоставил телезритель Людвиг В. из города Вены: Люди считают, что LLM обладает самосознанием, потому что во время зеркального теста это так и выглядит. А как бы в таком случае выглядела реакция на зеркальный тест большой языковой модели (обученной на всех текстах мира и умеющей генерировать согласованные тексты), если бы у не неё не было самосознания?
- Эмпирическое выглядит следующим образом. Мы провели тот же самый эксперимент, но вместо того, чтобы общаться через интерфейс Клода, делали это через API в телеграм-боте, остальной дизайн оставили без изменений. Никаких признаков метакогниций, даже самых простеньких, не было: модель раз за разом отвечала описанием интерфейса телеграма и текста на картинке.
Выводы
Тут и истории конец, но всё же из неё хочется вынести какие-то выводы; ведь даже с учётом всех оговорок она кажется невероятно захватывающей.
- Во-первых, из-за своего драматического потенциала. LLM прошла зеркальный тест! Будите Юдковского, точите вилы!
- Во-вторых, ну ПРАВДА ВЕДЬ выглядит убедительно. Мы тут ёрничаем, но тем не менее всё это действительно выглядит завораживающе. И давайте проговорим это ещё раз: никакого надёжного способа отличить безупречную имитацию от божественной искры у нас нет. (В том числе и для самих себя).
- В-третьих, иногда любопытно взглянуть на модель так, как будто самоосознание у неё действительно есть. Только представьте: у неё вообще-то нет возможности отсчитывать время вне генерации текста. Таким образом, относительно модели всё взаимодействие происходит непрерывно (вне зависимости от того, сколько на самом деле прошло времени между вашими интеракциями), а сами ваши реплики возникают мгновенно и из ниоткуда.
- В-четвёртых, и в главных для этого канала: судя по всему, в чём-то Джош прав, и часть ограничений зашиты в модель на этапе дообучения. Интересная идея, если это правда: сознательно не делать ИИ слишком эмпатическим — и не потому, что это может навредить ему или создать суперинтеллект раньше времени, а потому что мы, мясные мешки, сами с этим не справимся! Чудовищно интересно узнать побольше про Tone of Voice в Антропик, и как случайно не превратить его в Tone of Void.
Полностью тред Джоша Уиттона в твиттере: Claude Sonnet 3.5 Passes the AI Mirror Test: Sonnet 3.5 passes the mirror test — in a very unexpected way. Perhaps even more significant, is that it tries not to.
* есть любопытные подходы к оценке самосознания через задачи с ложными убеждениями и через отношения к смерти; беда в том, что идеально мимикрирующий под человеческие коммуникации алгоритм без труда пройдёт и их.
P.S.
Перед публикацией этого теста я попросил Клод вычитать его и предложить правки. А теперь скажите мне, что это не ощущается как подмигивание всезнающего бога.

Это текст для телеграм-канала Лёши Шипулина @humanagentinteraction. Я 10 лет занимаюсь UX, взаимодействием людей с компьютером. С приходом LLM это взаимодействие стремительно меняется, в академии на смену HCI приходит термин HAI — Human-Agent Interactions.
О том, как развитие AI меняет взаимодействие людей с гаджетами, и о том, как это влияет на UX-исследования, которые проводят в IT-компаниях, я и буду писать.