Selenium WebDriver Tutorial: How to Find XPath?
Hanna HorskayaВ автоматизации Selenium часто для поиска элемента на веб-странице используется XPath, если элементы не обнаруживаются общими локаторами, такими как id, class, name и т.д..
В этом руководстве мы узнаем о xpath и различных выражениях, чтобы найти сложные или динамические элементы, атрибуты которых динамически изменяются при обновлении или любых операциях.

____________________________________________________________________________
В этой статье вы сможете найти:
✔️Что такое XPath в Selenium?
✔️Синтаксис XPath в Selenium
✔️Типы X-path
✔️Абсолютный XPath
✔️Относительный XPath
✔️Использование XPath для обработки сложных и динамических элементов в Selenium
✔️Basic XPath
✔️Contains()
✔️Using OR & AND
✔️Starts-with функция
✔️Text()
✔️XPath axes методы
✔️Following
✔️Ancestor
✔️Child
✔️Preceding
✔️Following-sibling
✔️Parent
✔️Self
✔️Descendant
____________________________________________________________________________
Что такое XPath в Selenium?
XPath можно определить как язык запросов, используемый для навигации по документам XML с целью поиска различных элементов. Основной синтаксис выражения XPath -
//tag[@attributeName='attributeValues']
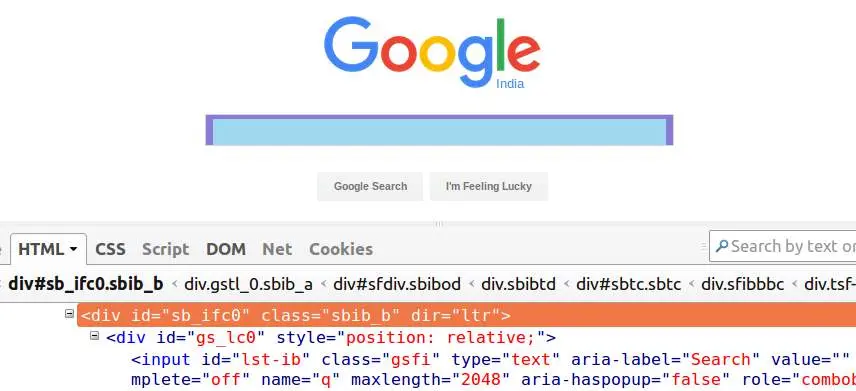
Важным различием между CSS и XPath локаторами является то, что, используя XPath, мы можем производить перемещение как в глубину DOM иерархии, так и возвращаться назад. Что же касается CSS, то тут мы можем двигаться только в глубину. Это значит, что с XPath можем найти родительский элемент, по дочернему.
Базовый формат XPath в Selenium:
- '/' или '//' - одинарная косая черта и двойная косая черта используются для создания абсолютных и относительных XPath (объяснено далее в этом руководстве). Одиночная косая черта используется для начала выделения с корневого узла. Принимая во внимание, что двойная косая черта используется для выбора текущего узла, соответствующего выбранному. На данный момент мы будем использовать здесь «//».
- Тег - теги в HTML начинаются с '<' и заканчиваются '>'. Они используются для включения различных элементов и предоставления информации об обработке элементов. На изображении выше «div» и «input» являются тегами.
- Атрибут - атрибуты определяют свойства, которые содержат элементы HTML. На изображении выше id, classes и dir являются атрибутами внешнего div.
- AttrbuteValue - AttributeValues, как следует из названия, представляют собой значения атрибутов, например, «sb_ifc0» - это значение атрибута «id».
Используя синтаксис XPath, показанный выше, мы можем создать несколько выражений XPath для блока поиска Google, указанного на изображении, например: // div [@ id = 'sb_ifc0 ′] , // div [@ class =' sbib_b '] или / / div [@ dir = 'ltr'] . Любое из этих выражений может использоваться для получения желаемого элемента, если выбранные атрибуты уникальны.
Синтаксис XPath в selenium:
XPath содержит путь к элементу, расположенному на веб-странице.
Стандартный синтаксис XPath:
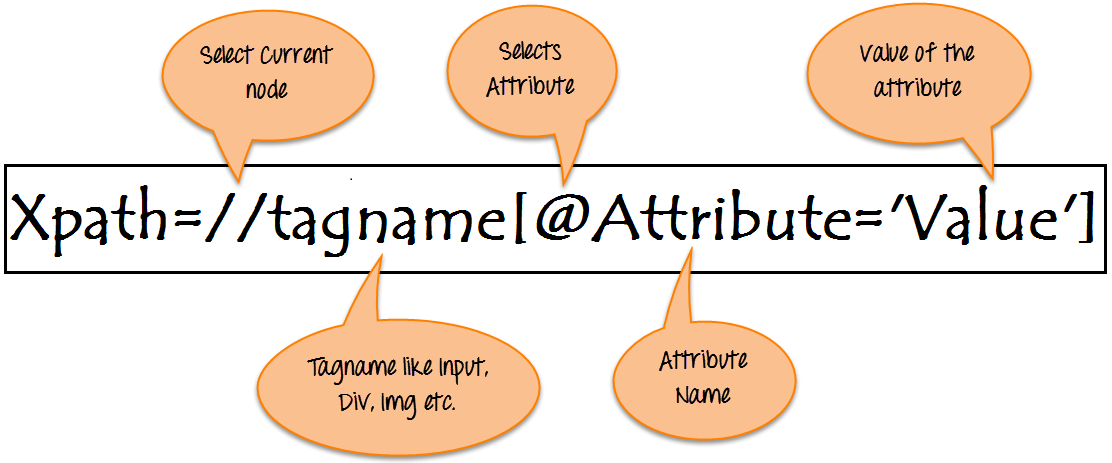
Xpath=//tagname[@attribute='value']
- // : Выбор текущего узла.
- Tagname: Имя тэга конкретного узла.
- @: Выбор атрибута.
- Attribute: Имя атрибута узла.
- Value: Значение атрибута.
Чтобы точно найти элемент на веб-страницах, существуют разные типы локаторов:

Типы X-path
Есть два типа XPath:
1) Абсолютный XPath
2) Относительный XPath
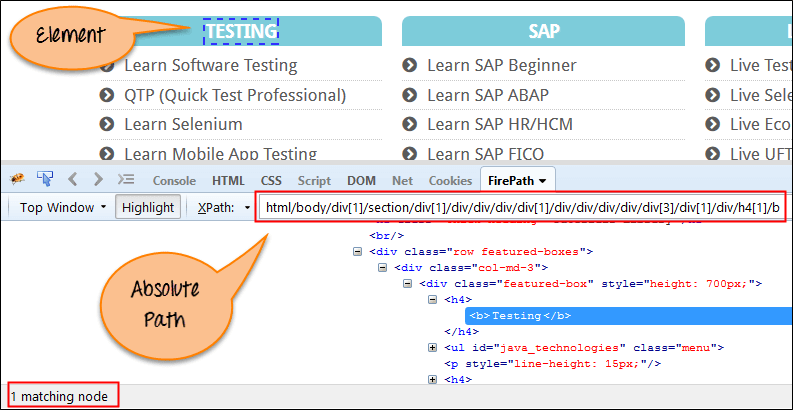
Абсолютный XPath:
выражения XPath, созданные с использованием абсолютных XPath, начинают выбор с корневого узла. Эти выражения либо начинаются с символа «/», либо с корневого узла и проходят через всю модель DOM, чтобы достичь элемента. Его главным недостатком является то, что если внести какие-либо изменения в путь элемента, то XPath больше не будет явзяться валидным.
Ключевой характеристикой XPath является то, что он начинается с одинарной косой черты (/), это означает, что вы можете выбрать элемент из корневого узла.
Ниже приведен пример абсолютного выражения xpath.
Absolute XPath: /html/body/div[2]/div[1]/div/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]/b[1]
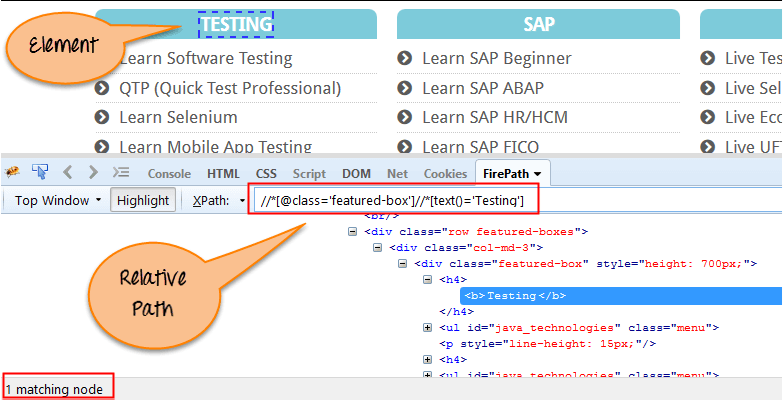
Относительный Xpath:
Относительный Xpath начинается с середины структуры HTML DOM. Он начинается с двойной косой черты (//). Он может искать элементы в любом месте веб-страницы, это означает, что нет необходимости писать длинный xpath. Эти XPath могут выбирать элементы в любом месте, которое соответствует критериям выбора и не обязательно начинается с корневого узла.
Относительный Xpath всегда предпочтительнее, так как это не полный путь от корневого элемента, и он менее зависит от изменений в структуре DOM модели.
Ниже приведен пример относительного выражения XPath. Это общий формат, используемый XPath для поиска элемента.
Relative XPath: //div[@class='featured-box cloumnsize1']//h4[1]//b[1]
Какой из двух (абсолютный или относительный XPath) лучше?
Относительные XPath считаются лучшими, потому что эти выражения легче читать и создавать; а также более надежный. Проблема с абсолютными XPath в том, что даже небольшое изменение в DOM пути от корневого узла к желаемому элементу может сделать XPath недействительным.
Что такое XPath оси
Оси XPath ищут разные узлы в XML-документе из текущего контекстного узла. Оси XPath - это методы, используемые для поиска динамических элементов, что в противном случае невозможно обычным методом XPath, не имеющим идентификатора, имени класса, имени и т.д.
Методы Xpath axes используются для поиска тех элементов, которые динамически изменяются при обновлении и любых других операциях. В Selenium Webdriver обычно используются несколько методов осей, такие как child, parent, ancestor, sibling, previous, self и т.д.
Использование XPath для обработки сложных и динамических элементов в Selenium
Часто при автоматизации у нас либо нет уникальных атрибутов элементов, которые однозначно их идентифицируют, либо элементы динамически генерируются со значением атрибута, заранее неизвестным.
Для подобных случаев XPath предоставляет различные методы поиска элементов, такие как - с использованием текста, написанного поверх элементов; с использованием индекса элемента; использование частично совпадающего значения атрибута; путем перехода к одноуровневому, дочернему или родительскому элементу, который может быть однозначно идентифицирован, и т. д.
1) Basic XPath:
Выражение XPath выбирает узлы или список узлов на основе таких атрибутов, как ID, Name, Classname и т.д. из XML-документа, как показано ниже.
Xpath=//input[@name='uid']

Некоторые другие basic xpath примеры:
Xpath=//input[@type='text'] Xpath= //label[@id='message23'] Xpath= //input[@value='RESET'] Xpath=//*[@class='barone'] Xpath=//a[@href='http://demo.guru99.com/'] Xpath= //img[@src='//cdn.guru99.com/images/home/java.png']
2) Contains():
Contains() - это метод, используемый в выражении XPath. Он обычно используется, когда значение любого атрибута изменяется динамически, например, информация для входа в систему.
Функция contains() позволяет находить элемент с частичным текстом, как показано в примере XPath ниже.
В этом примере мы попытались идентифицировать элемент, просто используя частичное текстовое значение атрибута. В этом выражении XPath вместо кнопки отправки используется частичное значение sub. Можно заметить, что элемент найден успешно.
Полное значение «type» - «submit», но с использованием только частичного значения «sub».
Xpath=//*[contains(@type,'sub')]
Полное значение 'name' - 'btnLogin', но с использованием только частичного значения 'btn'.
Xpath=//*[contains(@name,'btn')]
В приведенном выше выражении мы взяли «name» как атрибут и «btn» как частичное значение, как показано на скриншоте ниже. Это обнаружит 2 элемента (LOGIN & RESET), поскольку их атрибут name начинается с btn.

Точно так же в приведенном ниже выражении мы взяли «id» как атрибут, а «message» как частичное значение. Будет найдено 2 элемента (User-ID must not be blank' & 'Password must not be blank»), так как его атрибут «name» начинается с «message».
Xpath=//*[contains(@id,'message')]

В приведенном ниже выражении мы взяли «text» ссылки как атрибут и «here» как частичное значение, как показано на снимке экрана ниже. Это найдет ссылку («here»), поскольку она отображает текст «here».
Xpath=//*[contains(text(),'here')] Xpath=//*[contains(@href,'guru99.com')]

3) Использование OR & AND:
В выражении OR используются два условия: должно ли выполняться 1-е условие OR 2-е условие. Это также применимо, если выполняется какое-либо одно условие или, возможно, оба. Означает, что для поиска элемента должно выполняться любое одно условие.
В приведенном ниже выражении XPath он определяет элементы, для которых истинны одно или оба условия.
Xpath=//*[@type='submit' or @name='btnReset']
Выделение обоих элементов как элемента «LOGIN» с атрибутом «type» и элемента «RESET» с атрибутом «name».

В выражении AND используются два условия, оба условия должны выполняться, чтобы найти элемент. Не удается найти элемент, если хотя бы одно условие ложно.
Xpath=//input[@type='submit' and @name='btnLogin']
В приведенном ниже выражении выделен элемент «LOGIN», поскольку он имеет атрибуты «type» и «name».

4) Xpath Starts-with
XPath starts-with()- это функция, используемая для поиска веб-элемента, значение атрибута которого изменяется при обновлении или других динамических операциях на веб-странице. В этом методе начальный текст атрибута сопоставляется, чтобы найти элемент, значение атрибута которого изменяется динамически. Вы также можете найти элементы, значение атрибута которых является статическим (не изменяется).
Например -: Предположим, что ID конекретного элемента изменяется динамически:
Id=" message12"
Id=" message345"
Id=" message8769"
и так далее ... но исходный текст такой же. В этом случае мы используем выражение Start-with.
В приведенном ниже выражении есть два элемента с идентификатором, начинающимся с «message» (т.е. «ID пользователя не должен быть пустым» и «Пароль не должен быть пустым»). В приведенном ниже примере XPath находит те элементы, чей «ID» начинается с «message».
Xpath=//label[starts-with(@id,'message')]

5) XPath функция Text()
Функция XPath text() - это встроенная функция selenium webdriver, которая используется для поиска элементов на основе текста веб-элемента. Он помогает находить точные текстовые элементы и находит элементы в наборе текстовых узлов. Размещаемые элементы должны быть в строковой форме.
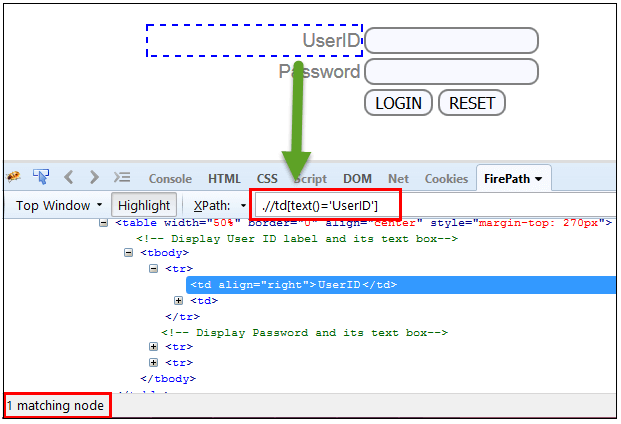
В этом выражении с текстовой функцией мы находим элемент с точным текстовым соответствием, как показано ниже. В нашем случае мы находим элемент с текстом «UserID».
Xpath=//td[text()='UserID']
Методы XPath axes:
Эти методы осей XPath используются для поиска сложных или динамических элементов. Ниже мы увидим некоторые из этих методов.
1) Following:
Выбирает все элементы в документе текущего узла [UserID- текущий узел]как показано на экране ниже.
Xpath=//*[@type='text']//following::input

Есть 3 «input» узла, совпадающих с использованием «following» оси - пароль, логин и кнопка сброса. Если вы хотите выбрать конкретный элемент, вы можете использовать следующий метод XPath:
Xpath=//*[@type='text']//following::input[1]
Вы можете изменить XPath в соответствии с требованиями, написав [1], [2] ... и так далее.
При вводе «1» на приведенном ниже снимке экрана обнаруживается конкретный узел, который является элементом поля ввода «Пароль».

2) Ancestor:
Ось "ancestor" выбирает все элементы предков (прародитель, родитель и т.д.) текущего узла, как показано на экране ниже.
В приведенном ниже выражении мы находим элемент предков текущего узла (узел "ENTERPRISE TESTING").
Xpath=//*[text()='Enterprise Testing']//ancestor::div

Есть 13 узлов "div", найденных с помощью оси "ancestor". Если вы хотите выбрать конкретный элемент, вы можете использовать приведенный ниже XPath, где вы меняете число 1, 2 в соответствии с вашими требованиями:
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]
3) Child:
Выбирает все дочерние элементы текущего узла, как показано на экране ниже.
Xpath=//*[@id='java_technologies']//child::li

Найден 71 узел "li", сопоставленный с помощью "Child" оси. Если вы хотите найти какой-то конкретный элемент, вы можете написать следующий xpath:
Xpath=//*[@id='java_technologies']//child::li[1]
Вы можете изменить XPath в соответствии с требованиями, написав [1], [2] ... и так далее.
4) Preceding:
Выберите все узлы, которые предшествуют текущему узлу, как показано на экране ниже.
В приведенном ниже выражении он идентифицирует все элементы ввода до кнопки «LOGIN», то есть идентификатор пользователя и элемент ввода пароля.
Xpath=//*[@type='submit']//preceding::input
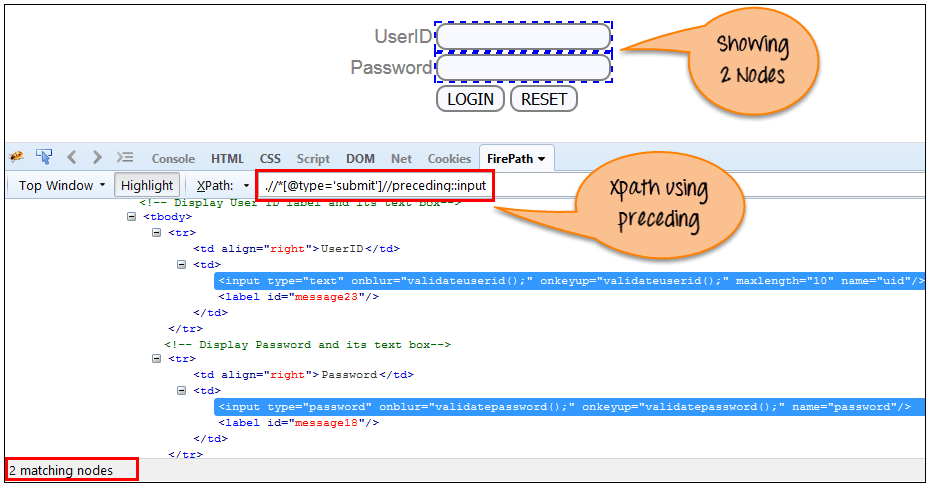
Есть 2 «входных» узла, совпадающих с использованием «Preceding» оси. Если вы хотите выбрать конкретный элемент, вы можете использовать XPath ниже:
Xpath=//*[@type='submit']//preceding::input[1]
Вы можете изменить XPath в соответствии с требованиями, написав [1], [2] ... и так далее.
5) Following-sibling:
Выбор следующих братьев и сестер контекстного узла. Братья и сестры находятся на одном уровне с текущим узлом, как показано на экране ниже. Он найдет элемент после текущего узла.
xpath=//*[@type='submit']//following-sibling::input

6) Parent:
Выбирает родителя текущего узла, как показано на скриншоте ниже.
Xpath=//*[@id='rt-feature']//parent::div

Найдено 65 узлов "div", совпадающих с использованием "parent" оси. Если вы хотите выбрать конкретный элемент, вы можете использовать XPath ниже:
Xpath=//*[@id='rt-feature']//parent::div[1]
Вы можете изменить XPath в соответствии с требованиями, написав [1], [2] ... и так далее.
7) Self:
Выбирает текущий узел или «self» означает, что он указывает сам узел, как показано на экране ниже.

Сопоставление одного узла с использованием оси "self". Он всегда находит только один узел, поскольку он представляет собой элемент.
Xpath =//*[@type='password']//self::input
8) Descendant:
Выбирает потомков текущего узла, как показано на экране ниже. В приведенном ниже выражении он определяет всех элементов, потомков текущего элемента, что означает нижний уровень под узлом.
Xpath=//*[@id='rt-feature']//descendant::a
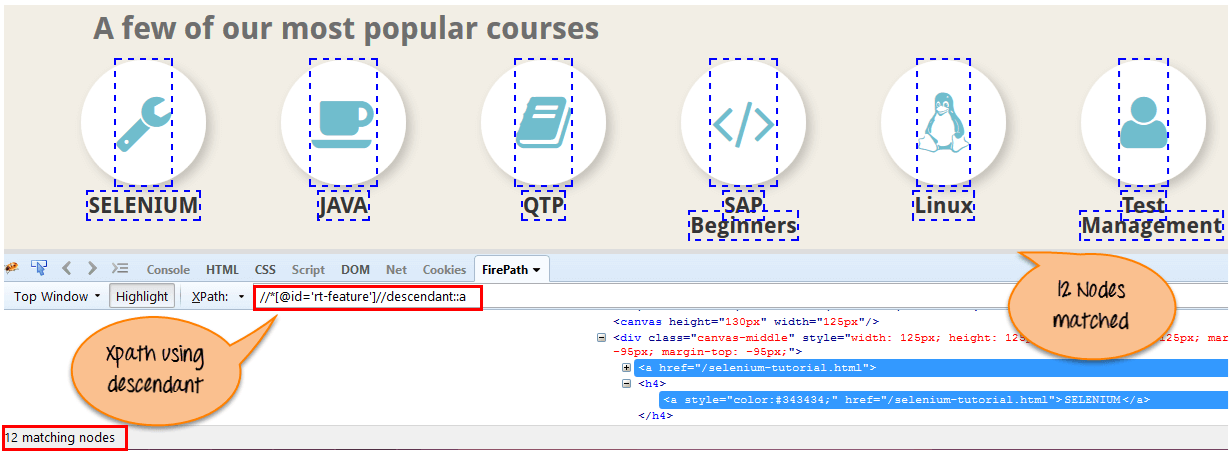
Найдено 12 узлов "descendant", сопоставляемых с помощью оси "потомков". Если вы хотите сосредоточиться на каком-либо конкретном элементе, вы можете использовать XPath ниже:
Xpath=//*[@id='rt-feature']//descendant::a[1]
Вы можете изменить XPath в соответствии с требованиями, написав [1], [2] ... и так далее.
Summary:
ancestor
Указывает всех предков контекстного узла, начиная с родительского узла и переходя к корневому узлу.
ancestor-or-self
Указывает контекстный узел и всех его предков, включая корневой узел.
attribute
Указывает атрибуты контекстного узла. Только элементы имеют атрибуты. Эта ось может быть обозначена знаком (@).
child
Указывает дочерние элементы контекстного узла. Если в выражении XPath не указана ось, это понимается по умолчанию. Поскольку дочерние элементы есть только у корневого узла или узлов элемента, любое другое использование ничего не выберет.
descendant
Обозначает всех дочерних узлов контекстного узла и всех их дочерних элементов. Узлы атрибутов и пространств имен не включаются - родительский узел атрибута является узлом элемента, но узлы атрибута не являются потомками своих родителей.
descendant-or-self
Указывает контекстный узел и всех его потомков. Узлы атрибутов и пространств имен не включаются - родительский узел атрибута является узлом элемента, но узлы атрибута не являются потомками своих родителей.
following
Указывает все узлы, которые появляются после контекстного узла, за исключением любых узлов-потомков, атрибутов и узлов пространства имен.
following-sibling
Указывает все узлы, которые имеют того же родителя, что и контекстный узел, и появляются после контекстного узла в исходном документе.
parent
Указывает единственный узел, который является родителем контекстного узла. Его можно сократить до двух точек (..).
preceding
Указывает все узлы, которые предшествуют контекстному узлу в документе, кроме любых узлов-предков, атрибутов и пространств имен.
preceding-sibling
Указывает все узлы, которые имеют того же родителя, что и контекстный узел, и появляются перед контекстным узлом в исходном документе.
self
Указывает сам контекстный узел. Его можно сократить до одной точки (.).