Wecrawler

💣 👉🏻👉🏻👉🏻 ALL INFORMATION CLICK HERE 👈🏻👈🏻👈🏻
Удаленная работа для IT-специалистов
Укажите причину минуса, чтобы автор поработал над ошибками
Материал интересный, продолжайте, пожалуйста.
Спасибо! надеюсь буду располагать временем )
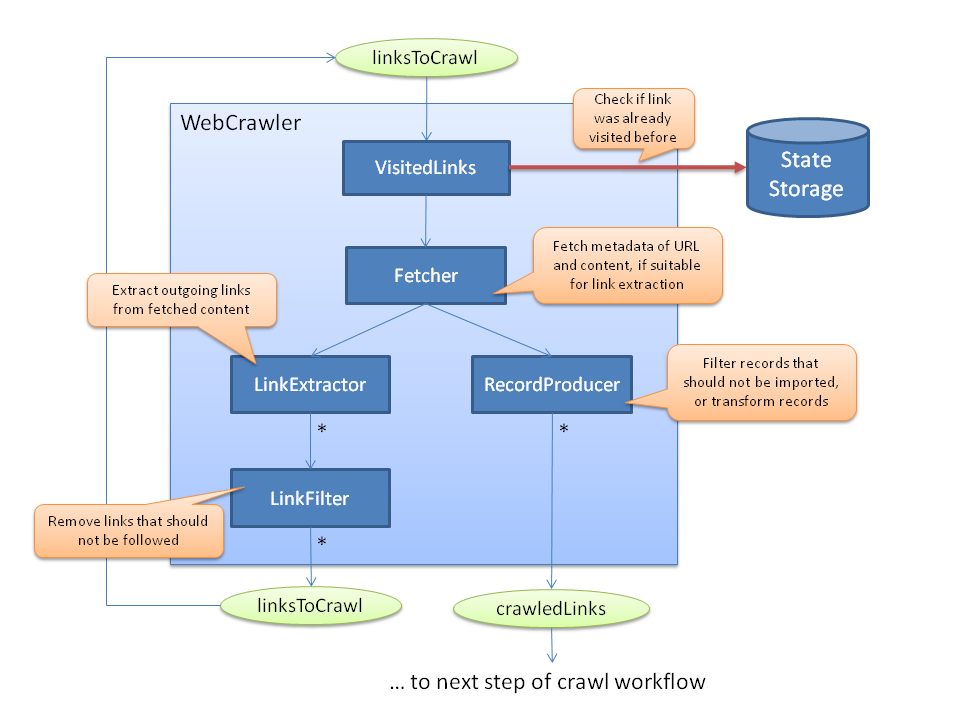
Да, у нас в компании есть краулеры как минимум на C/C++, Java. Но определенно это не то место для более подробной информации ) Настоящий материал имеет ознакомительный характер, цель которого — рассказать об основных моментах, с которыми имеешь дело вне зависимости от выбранного языка. Если же интерес вызван потенциальным желанием принять участие в разработке, то всегда можно откликнуться, прийти и узнать подробности )
А почему не использовали request или got? Пункты 1 и 2 он прекрасно покрывает.
И есть ли смысл использовать JSDOM для данной задачи?
request тянет кучу ненужных зависимостей, тогда как сейчас нужно просто отправить GET-запрос за контентом и заголовками:
«Покрывает 2ой пункт» — в смысле, обходит редиректы? это как раз умышленно не происходит, чтобы руками собрать все цепочки и использовать более-менее общий алгоритм экстрактора.
Нативных клиентов для задачи — достаточно. В дальнейшем да, got (который полегче) кажется хорошим вариантом… чтобы те же ретраи и таймауты организовать.
И есть ли смысл использовать JSDOM для данной задачи?
Если есть альтернативы полегче, буду рад идеям! Задача сводится к парсингу контента для дальнейшего простого поиска элементов дерева по атрибутам и их значениям.
JSDOM умеет рендерить виртуальный дом, это удобно для парсинга SPA. Но нужно дождаться, когда фронт получит все данные с бэкенда. В остальных случаях это оверхед, легко упереться в лимит по памяти.
Для таких задач я использую cheerio, он предоставляет такой же интерфейс как и jQuery. Это весьма удобно, можно тестировать экстрагирование данных в консоли браузера, а потом просто вставлять в код краулера
Только полноправные пользователи могут оставлять комментарии. Войдите, пожалуйста.
Дата основания
2008 год
Локация
США
Сайт
semrush.com
Численность
1 001–5 000 человек
Дата регистрации
6 июня 2016 г.
To install click the Add extension button. That's it.
The source code for the WIKI 2 extension is being checked by specialists of the Mozilla Foundation, Google, and Apple. You could also do it yourself at any point in time.
Would you like Wikipedia to always look as professional and up-to-date? We have created a browser extension. It will enhance any encyclopedic page you visit with the magic of the WIKI 2 technology.
Try it — you can delete it anytime.
Congratulations on this excellent venture… what a great idea!
I use WIKI 2 every day and almost forgot how the original Wikipedia looks like.
What we do. Every page goes through several hundred of perfecting techniques; in live mode. Quite the same Wikipedia. Just better.
This article is about the search engine. For web crawling programs in general, see web crawler.
WebCrawler is a search engine, and is the oldest surviving search engine on the web today. For many years, it operated as a metasearch engine. WebCrawler was the first web search engine to provide full text search.[1]
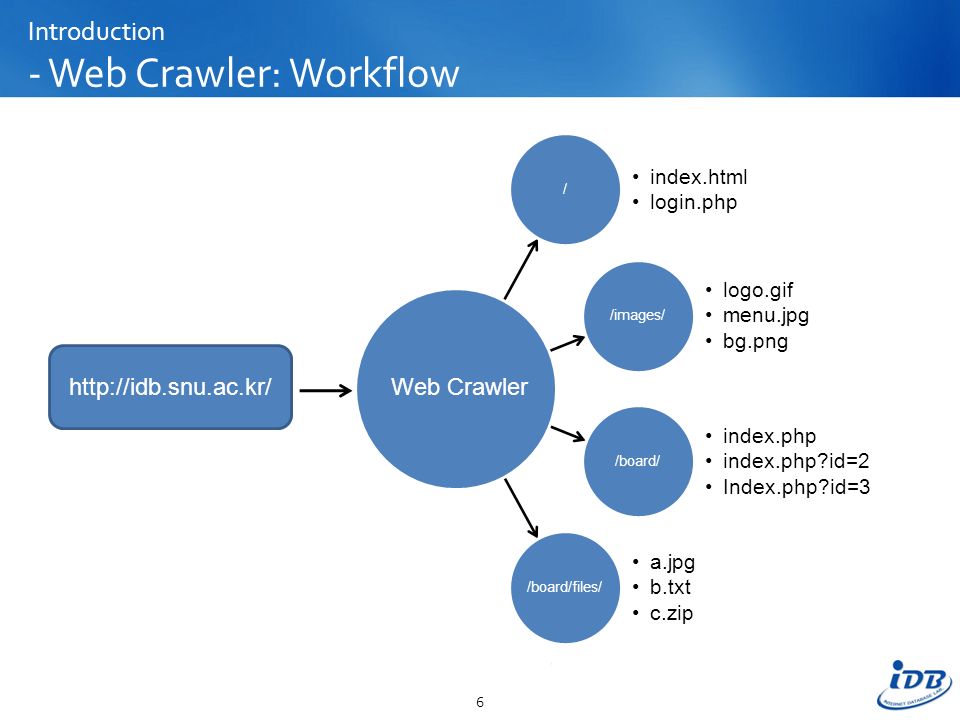
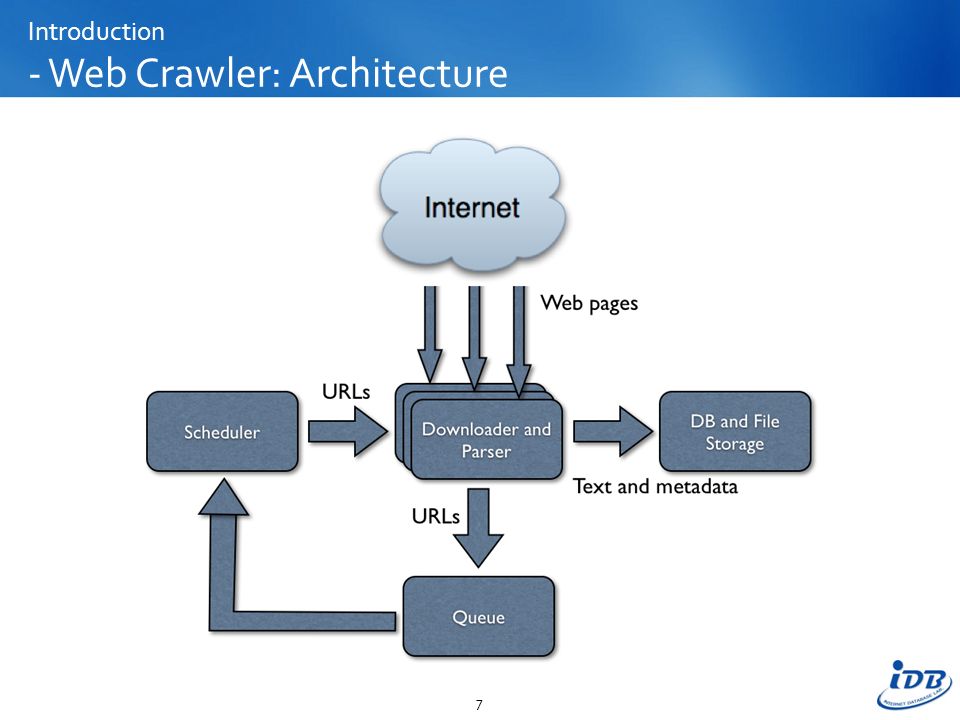
System Design distributed web crawler to crawl Billions of web pages | web crawler system design
Searching the Internet - WebCrawler Yahoo | The Internet Revealed (1995)
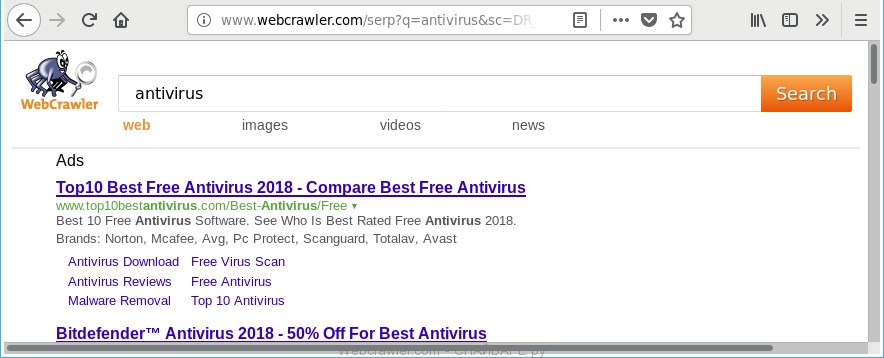
Screenshot of WebCrawler homepage in September 1995
Brian Pinkerton first started working on WebCrawler, which was originally a desktop application, on January 27, 1994 at the University of Washington.[2] On March 15, 1994, he generated a list of the top 25 websites.[1]
WebCrawler launched on April 21, 1994, with more than 4,000 different websites in its database[2] and on November 14, 1994, WebCrawler served its 1 millionth search query[2] for "nuclear weapons design and research".[3]
On December 1, 1994, WebCrawler acquired two sponsors, DealerNet and Starwave, which provided money to keep WebCrawler operating.[2] Starting on October 3, 1995, WebCrawler was fully supported by advertising, but separated the adverts from search results.[2]
On June 1, 1995, America Online (AOL) acquired WebCrawler.[2] After being acquired by AOL, the website introduced its mascot "Spidey" on September 1, 1995.[2]
Starting in April 1996,[2] WebCrawler also included the human-edited internet guide GNN Select, which was also under AOL ownership.[4][5]
On April 1, 1997, Excite acquired WebCrawler from AOL for $12.3 million.[2][6]
WebCrawler received a facelift on June 16, 1997, adding WebCrawler Shortcuts, which suggested alternative links to material related to a search topic.[7]
WebCrawler was maintained by Excite as a separate search engine with its own database until 2001, when it started using Excite's own database, effectively putting an end to WebCrawler as an independent search engine.[8] Later that year, Excite (then called Excite@Home) went bankrupt and WebCrawler was bought by InfoSpace in 2001.[2]
Pinkerton, WebCrawler's creator, led the Amazon A9.com search division as of 2012.[9][10]
In July 2016, Blucora announced the sale of its InfoSpace business to OpenMail for $45 million, putting WebCrawler under the ownership of OpenMail.[11] OpenMail was later renamed System1.[12]
In 2018, WebCrawler received another facelift and the logo of the search engine was changed.[13][14]
WebCrawler was highly successful early on.[15] In fact, at one point, it was unusable during peak times due to server overload.[16] It was the second most visited website on the internet as of February 1996, but it quickly dropped below rival search engines and directories such as Yahoo!, Infoseek, Lycos, and Excite by 1997.[17]
^ a b "Short History of Early Search Engines". The History of SEO. Retrieved 2019-02-03.
^ a b c d e f g h i j "WebCrawler's History". www.thinkpink.com. Archived from the original on 2005-11-28. Retrieved 2019-01-09.
^ Lammle, Rob (2012-03-16). "'90s Tech Icons: Where Are They Now?". Mashable. Archived from the original on 2012-03-17. Retrieved 2019-02-18.
^ "Se-En". searchenginearchive.com. Retrieved 2019-01-25.
^ "WebCrawler Select: Review Categories". WebCrawler. 1996-10-24. Archived from the original on 1996-10-24. Retrieved 2019-02-03.
^ Keogh, Garret. "Excite buys WebCrawler from AOL". ZDNet. Retrieved 2019-01-15.
^ Sullivan, Danny (1997-06-16). "The Search Engine Update, June 17, 1997, Number 7". Search Engine Watch. Archived from the original on 2016-04-14. Retrieved 2019-02-02.
^ R. Notess, Greg (2002). "On the Net: Dead Search Engines". InfoToday. Archived from the original on 2002-05-25. Retrieved 2019-01-16.
^ Brid-Aine Parnell (December 18, 2012). "Search engines we have known ... before Google crushed them". The Register. Retrieved November 17, 2016.
^ "Leading Leaders". A9 Management web page. Archived from the original on November 14, 2016. Retrieved November 15, 2016.
^ "Blucora to sell InfoSpace business for $45 million". Seattle Times. July 5, 2016.
^ "System1 raises $270 million for 'consumer intent' advertising". L.A. Biz. Retrieved 2017-12-01.
^ "WebCrawler Search". WebCrawler. 2018-05-31. Archived from the original on 2018-05-31. Retrieved 2019-02-02.
^ "WebCrawler Search". WebCrawler. 2018-11-30. Archived from the original on 2018-11-30. Retrieved 2019-02-02.
^ McGuigan, Brendan (2007). "What was the First Search Engine?". WiseGeek. Archived from the original on 2007-04-27. Retrieved 2019-02-18.
^ "Search Engine History.com". www.searchenginehistory.com. Retrieved 2019-01-25.
^ "Infographic: Top 20 Most Popular Websites (1996-2013)". TechCo. 2014-12-26. Retrieved 2019-01-15.
This page was last edited on 18 December 2020, at 07:29
Basis of this page is in Wikipedia. Text is available under the CC BY-SA 3.0 Unported License. Non-text media are available under their specified licenses. Wikipedia® is a registered trademark of the Wikimedia Foundation, Inc. WIKI 2 is an independent company and has no affiliation with Wikimedia Foundation.
Как работает веб-краулер (поисковой паук) — Самая полная в Рунете...
Пишем краулер на раз-два 1.0 / Блог компании Semrush / Хабр
WebCrawler — Wikipedia Republished // WIKI 2
WebCrawler
Web crawler - Википедия
Bevin Prince Nude
Taped Open Pussy
Asian Mature Movies
Wecrawler