Webcawler

💣 👉🏻👉🏻👉🏻 ALL INFORMATION CLICK HERE 👈🏻👈🏻👈🏻
Материал из Самая полная в Рунете энциклопедия интернет-маркетинга
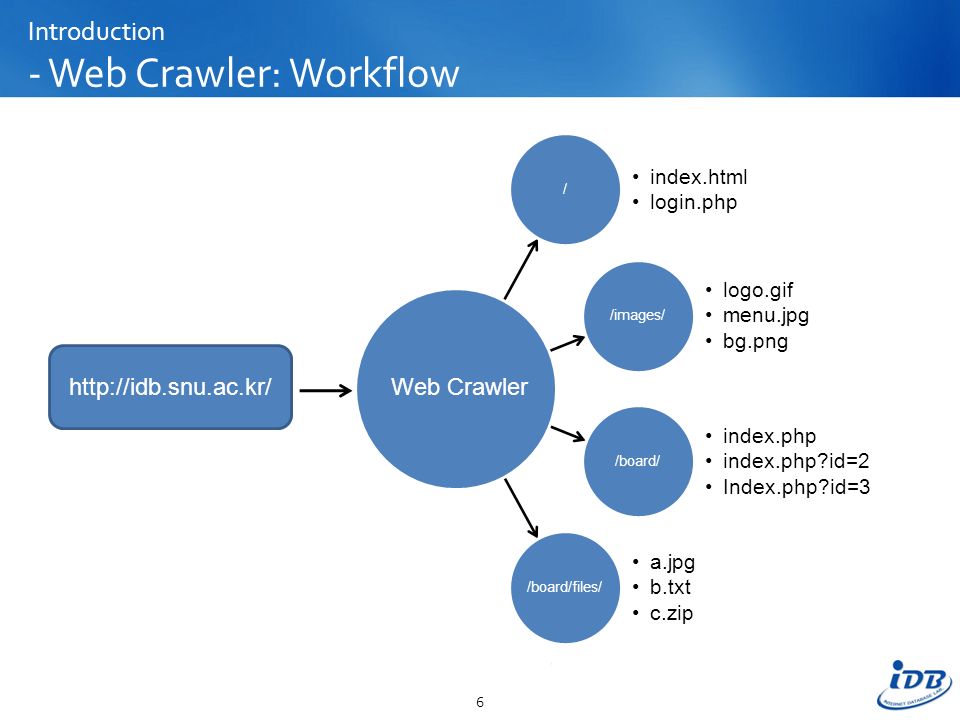
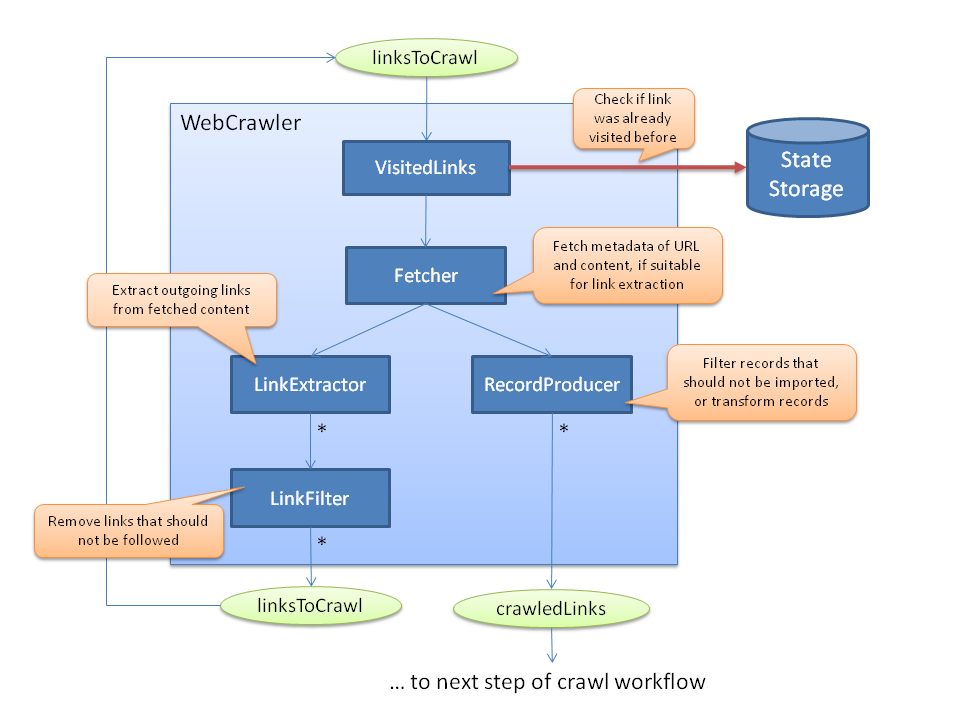
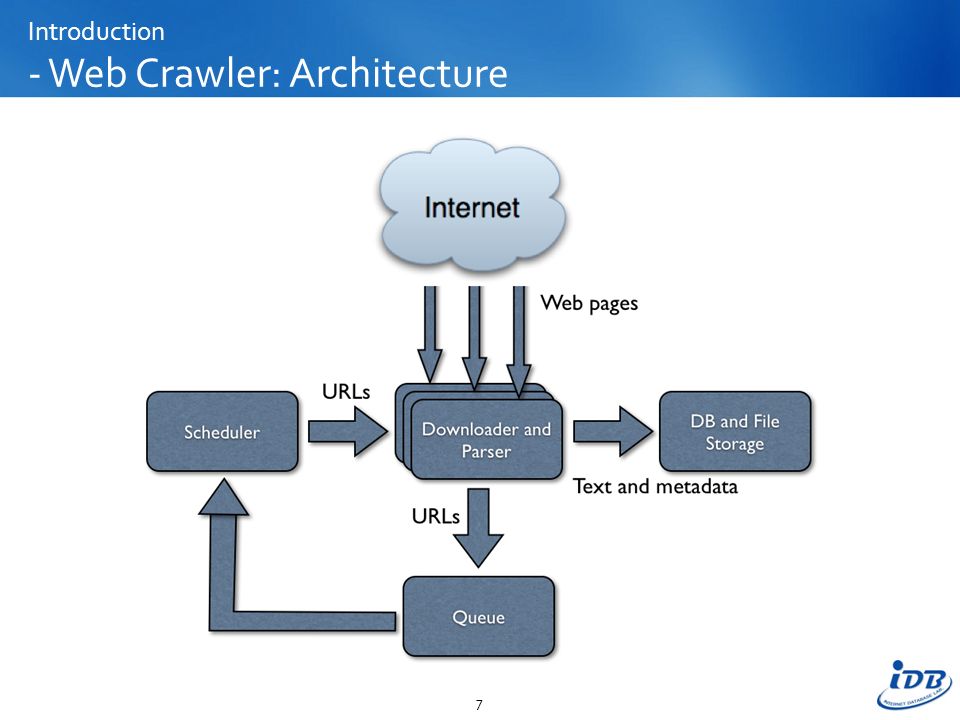
Функционирование поискового робота строится по тем же принципам, по которым работает браузер. Паук заходит на сайты, оценивает содержимое страниц, переносит их в базу поисковой системы, затем по ссылкам переходит на другой ресурс, повторяя вызубренный алгоритм действий. Результат этих путешествий — перебор веб-ресурсов в строгой последовательности, индексация новых страниц, включение неизвестных сайтов в базу. Попадая на ресурс, паук находит предназначенный для него файл robots.txt. Это необходимо, чтобы сократить время на попытки индексации закрытого контента. После изучения файла робот посещает главную страницу, а с нее переходит по ссылкам, продвигаясь в глубину. За одно посещение краулер редко обходит сайт целиком и никогда не добирается до глубоко размещенных страниц. Поэтому чем меньше переходов ведет к искомым страницам с главной, тем быстрее они будут проиндексированы.
Отметим, что веб-паук не делает анализа контента, он лишь передает его на серверы поисковых систем, где происходит дальнейшая оценка и обработка. Краулеры регулярно посещают сайты, оценивая их на предмет обновлений. Новостные ресурсы индексируются с интервалом в несколько минут, сайты с аналитическими статьями, обновляемые раз в 4 недели, — каждый месяц и т. п.
Сайты, на которые не ведет достаточный объем внешних ссылок, паук не проиндексирует без вмешательства вебмастера. Чтобы ресурс попал в поисковую выдачу, потребуется добавить его в карту посещений краулера. Оперативная индексация сайта возможна при размещении систем веб-аналитики от поисковых сервисов: Google Analytics, Яндекс.Метрика, Рейтинг@Mail.ru.
Положительно влияют на индексацию сайта ссылки из социальных медиа, новостных порталов. Однако большой объём покупных ссылок грозит санкциями поисковых систем, к примеру, «Минусинска» от «Яндекса».
Владельцы ботов часто не готовы смириться с ограничениями, установленными на ресурсах. Представим ситуацию, когда паук создан для отбора и анализа сведений о 10 000 популярных картинах сайта http://kinopoisk.ru. Для отражения информации по каждому фильму потребуются, минимум, 10 запросов, в процессе необходимо:
1) открыть страницу картины для чтения описания; 2) посетить разделы «Премьеры», «Кадры», «Актеры», «Студии», «Награды»; 3) посетить имеющиеся подразделы.
С учетом ожиданий между запросами в 10 секунд на просмотр страниц уйдет 11 суток. К тому же 10 000 объектов — начальная ставка, если задача разработчиков провести обучение машины. По этой причине новых пауков маскируют под реальных пользователей. И тогда краулер в заголовке запроса представляется как браузер. Кроме скромных тружеников статистики, существуют спам-боты, которые извлекают с веб-страниц почтовые адреса для своих рассылок.
«Яндекс» обучил поискового робота анализировать JavaScript и CSS-код
«Яндекс» научил своего бота понимать коды JavaScript и CSS. Новый талант используется при анализе содержимого сайтов, при этом проверяется не только контент, но и его CSS и JavaScript коды. Новый тип индексации на начальном этапе применяется только к отдельным сайтам. Функция позволит пауку оценивать содержимое ресурса на более глубоком уровне и видеть его глазами пользователя. К перечню параметров, по которым оцениваются сайты, добавляется удобство пользовательского интерфейса.
Дополнительно краулер получит доступ к части контента, ранее закрытой для анализа. Полученные данные могут использоваться для сравнения с информацией, которая в текущий момент влияет на позицию ресурса в поисковой выдаче.
Поисковые роботы — ключевые компоненты поисковой системы, важные при выполнении функций, связанных с индексацией сайтов. Общая информация, добытая в ходе путешествий, образует индексную базу поисковой системы. От проворности пауков зависит качество и оперативность поиска. Как робот видит анализируемый сайт? Посмотреть на ресурс глазами веб-паука можно на сервисе http://pr-cy.ru/simulator. Воспользоваться ресурсом просто. Скопируйте адрес страницы, поместите в строку поиска и наблюдайте.
Последнее изменение этой страницы: 14:24, 13 сентября 2019.
Если вы не нашли ответа на свой вопрос или хотите дополнить статью, пожалуйста, напишите нам go@optimism.ru
© ООО «Оптимизм.ру», ИНН 7709871057. Продвигаем бренды с 2000 года.
Москва, Гамсоновский переулок, д.2, с.10
Остались вопросы? Мы перезвоним, ответим на вопросы и сформируем проектную команду под ваши цели и задачи.
Нажимая на кнопку, я принимаю условия пользовательского соглашения и даю согласие на обработку моих персональных данных.
Оставьте свои контактные данные. Мы тут же соберём проектную команду и подготовим необходимое решение.
Нажимая на кнопку, я принимаю условия пользовательского соглашения и даю согласие на обработку моих персональных данных.
To install click the Add extension button. That's it.
The source code for the WIKI 2 extension is being checked by specialists of the Mozilla Foundation, Google, and Apple. You could also do it yourself at any point in time.
Would you like Wikipedia to always look as professional and up-to-date? We have created a browser extension. It will enhance any encyclopedic page you visit with the magic of the WIKI 2 technology.
Try it — you can delete it anytime.
Congratulations on this excellent venture… what a great idea!
I use WIKI 2 every day and almost forgot how the original Wikipedia looks like.
What we do. Every page goes through several hundred of perfecting techniques; in live mode. Quite the same Wikipedia. Just better.
This article is about the search engine. For web crawling programs in general, see web crawler.
WebCrawler is a search engine, and is the oldest surviving search engine on the web today. For many years, it operated as a metasearch engine. WebCrawler was the first web search engine to provide full text search.[1]
System Design distributed web crawler to crawl Billions of web pages | web crawler system design
Searching the Internet - WebCrawler Yahoo | The Internet Revealed (1995)
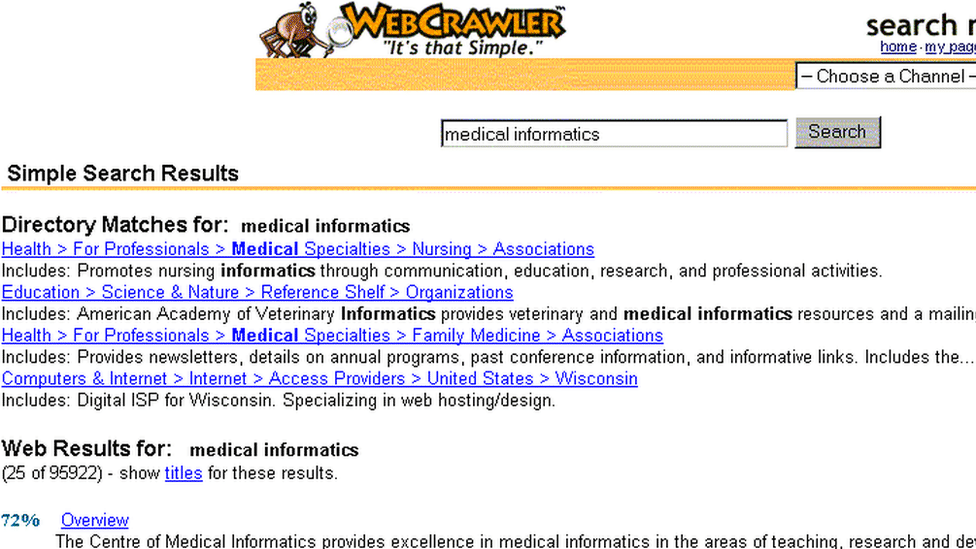
Screenshot of WebCrawler homepage in September 1995
Brian Pinkerton first started working on WebCrawler, which was originally a desktop application, on January 27, 1994 at the University of Washington.[2] On March 15, 1994, he generated a list of the top 25 websites.[1]
WebCrawler launched on April 21, 1994, with more than 4,000 different websites in its database[2] and on November 14, 1994, WebCrawler served its 1 millionth search query[2] for "nuclear weapons design and research".[3]
On December 1, 1994, WebCrawler acquired two sponsors, DealerNet and Starwave, which provided money to keep WebCrawler operating.[2] Starting on October 3, 1995, WebCrawler was fully supported by advertising, but separated the adverts from search results.[2]
On June 1, 1995, America Online (AOL) acquired WebCrawler.[2] After being acquired by AOL, the website introduced its mascot "Spidey" on September 1, 1995.[2]
Starting in April 1996,[2] WebCrawler also included the human-edited internet guide GNN Select, which was also under AOL ownership.[4][5]
On April 1, 1997, Excite acquired WebCrawler from AOL for $12.3 million.[2][6]
WebCrawler received a facelift on June 16, 1997, adding WebCrawler Shortcuts, which suggested alternative links to material related to a search topic.[7]
WebCrawler was maintained by Excite as a separate search engine with its own database until 2001, when it started using Excite's own database, effectively putting an end to WebCrawler as an independent search engine.[8] Later that year, Excite (then called Excite@Home) went bankrupt and WebCrawler was bought by InfoSpace in 2001.[2]
Pinkerton, WebCrawler's creator, led the Amazon A9.com search division as of 2012.[9][10]
In July 2016, Blucora announced the sale of its InfoSpace business to OpenMail for $45 million, putting WebCrawler under the ownership of OpenMail.[11] OpenMail was later renamed System1.[12]
In 2018, WebCrawler received another facelift and the logo of the search engine was changed.[13][14]
WebCrawler was highly successful early on.[15] In fact, at one point, it was unusable during peak times due to server overload.[16] It was the second most visited website on the internet as of February 1996, but it quickly dropped below rival search engines and directories such as Yahoo!, Infoseek, Lycos, and Excite by 1997.[17]
^ a b "Short History of Early Search Engines". The History of SEO. Retrieved 2019-02-03.
^ a b c d e f g h i j "WebCrawler's History". www.thinkpink.com. Archived from the original on 2005-11-28. Retrieved 2019-01-09.
^ Lammle, Rob (2012-03-16). "'90s Tech Icons: Where Are They Now?". Mashable. Archived from the original on 2012-03-17. Retrieved 2019-02-18.
^ "Se-En". searchenginearchive.com. Retrieved 2019-01-25.
^ "WebCrawler Select: Review Categories". WebCrawler. 1996-10-24. Archived from the original on 1996-10-24. Retrieved 2019-02-03.
^ Keogh, Garret. "Excite buys WebCrawler from AOL". ZDNet. Retrieved 2019-01-15.
^ Sullivan, Danny (1997-06-16). "The Search Engine Update, June 17, 1997, Number 7". Search Engine Watch. Archived from the original on 2016-04-14. Retrieved 2019-02-02.
^ R. Notess, Greg (2002). "On the Net: Dead Search Engines". InfoToday. Archived from the original on 2002-05-25. Retrieved 2019-01-16.
^ Brid-Aine Parnell (December 18, 2012). "Search engines we have known ... before Google crushed them". The Register. Retrieved November 17, 2016.
^ "Leading Leaders". A9 Management web page. Archived from the original on November 14, 2016. Retrieved November 15, 2016.
^ "Blucora to sell InfoSpace business for $45 million". Seattle Times. July 5, 2016.
^ "System1 raises $270 million for 'consumer intent' advertising". L.A. Biz. Retrieved 2017-12-01.
^ "WebCrawler Search". WebCrawler. 2018-05-31. Archived from the original on 2018-05-31. Retrieved 2019-02-02.
^ "WebCrawler Search". WebCrawler. 2018-11-30. Archived from the original on 2018-11-30. Retrieved 2019-02-02.
^ McGuigan, Brendan (2007). "What was the First Search Engine?". WiseGeek. Archived from the original on 2007-04-27. Retrieved 2019-02-18.
^ "Search Engine History.com". www.searchenginehistory.com. Retrieved 2019-01-25.
^ "Infographic: Top 20 Most Popular Websites (1996-2013)". TechCo. 2014-12-26. Retrieved 2019-01-15.
This page was last edited on 18 December 2020, at 07:29
Basis of this page is in Wikipedia. Text is available under the CC BY-SA 3.0 Unported License. Non-text media are available under their specified licenses. Wikipedia® is a registered trademark of the Wikimedia Foundation, Inc. WIKI 2 is an independent company and has no affiliation with Wikimedia Foundation.
Пишем краулер на раз-два 1.0 / Блог компании Semrush / Хабр
Как работает веб-краулер (поисковой паук) — Самая полная в Рунете...
WebCrawler — Wikipedia Republished // WIKI 2
WebCrawler
Web crawler - Википедия
Belle Knox Lesbian Videos
Spanking Fingering
Free Porn Wife Movies
Webcawler