WEBINT WRITEUP
@fkshell @fuckwebsec> А че такое WEBINT?
Уиии, вот что это такое! Webint - это, как, умение учиться всему из интернета! Это, как, анализ всей информации откуда угодно в сети! 🙀
Webint (или Web Intelligence) - это область, связанная с анализом данных и информации, полученных из сети Интернет. Включает в себя сбор, анализ и интерпретацию данных из различных онлайн-источников, таких как веб-сайты, социальные сети, онлайн-платформы и другие. Это область активно используется для получения понимания о текущих тенденциях, обсуждениях в сети, мнениях пользователей и других аспектах, которые можно извлечь из онлайн-среды.
(как мне объяснил чат дцп)
Тема странная 🤔 что-то на границе с реконом, но лан
В общем, мне предоставилась возможность поучаствовать в разработке этого раздела для ctf от кибережа ☺️
Всего четыре задания постепенно увеличивающиеся по уровню сложности. Каждое задание это докер контейнер, который нужно развернуть локально. Флаг представляет собой хэш SHA256 или md5. Для упрощения поиска флага хэш находится рядом с ключевым словом FLAG.
✨✨✨ Погнали посмотрим как это решать ✨✨✨
TASK 1. FLAG IN HTML CODE
В первом задании все очень просто 🙃 Можно найти флаг в исходном коде HTML-документа.
TASK 2. FLAG IN HEADER
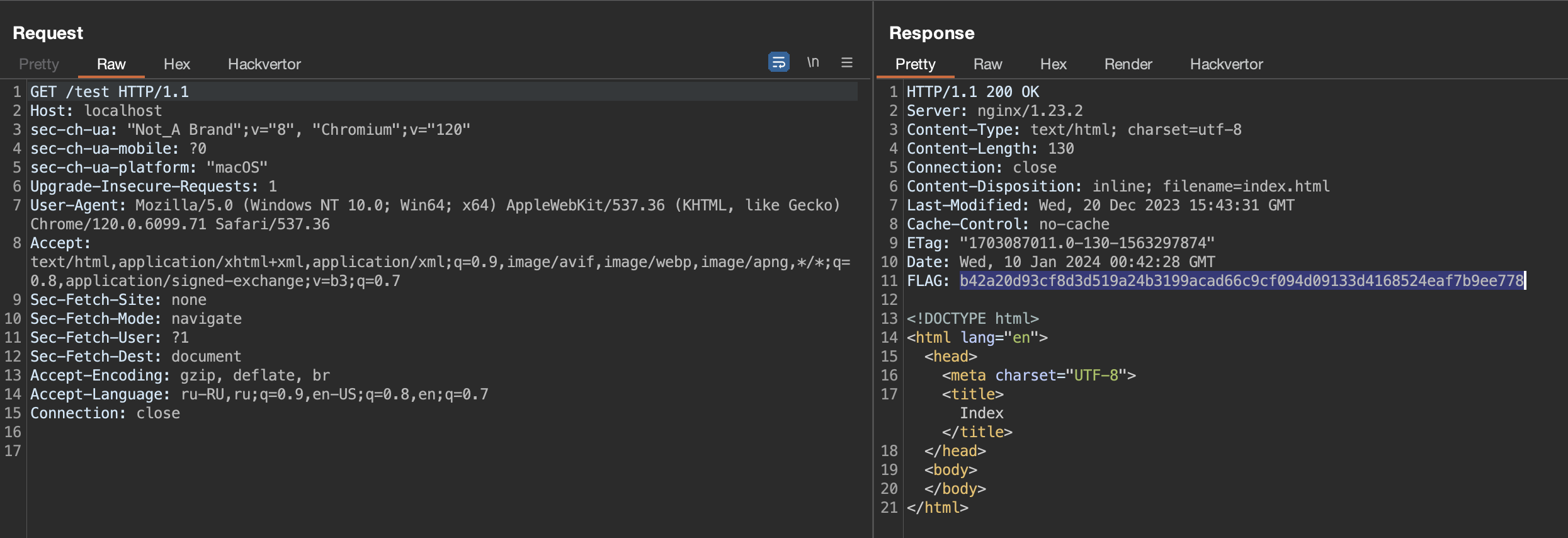
Задача немного посложнее, но все еще база. Разворачиваем докер. Видим пустую страницу в браузере (это байт на то, чтобы посмотреть трафик). В общем палим http запросы/ответы при обращении к ресурсу и находим флаг в заголовке.
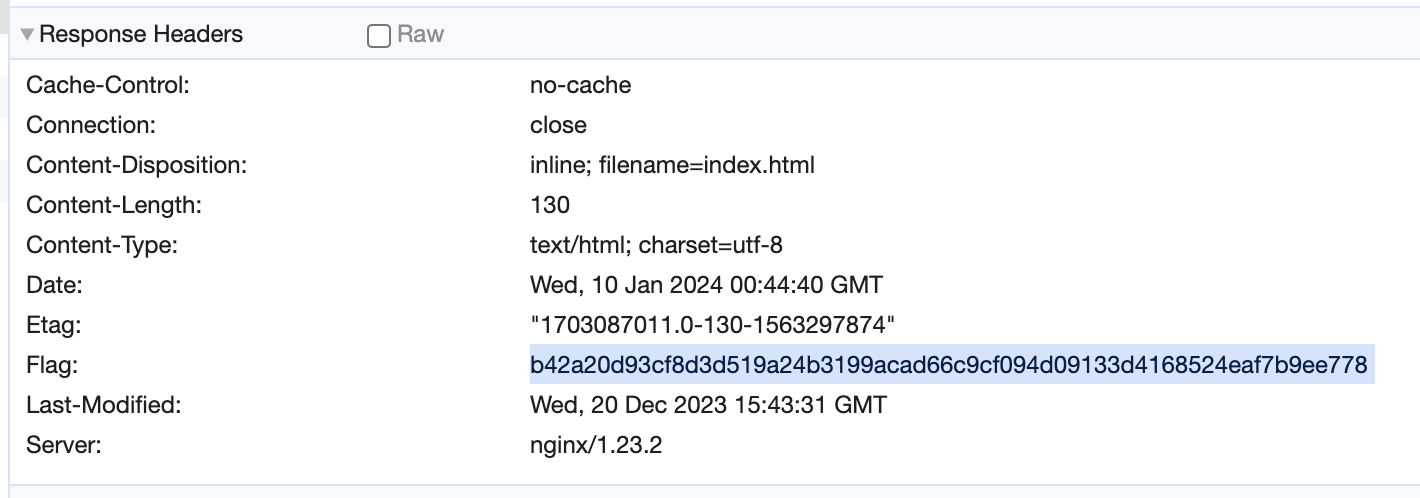
Это тоже можно сделать в developer tools любого браузера. Вот, например.
TASK 3. FLAG IN SERVER FILE
Перехватываем запрос в burpsuite и отправляем в Intruder.
Берем словарь бума https://github.com/Bo0oM/fuzz.txt (не обязательно этот) и начинаем фаззить директории:
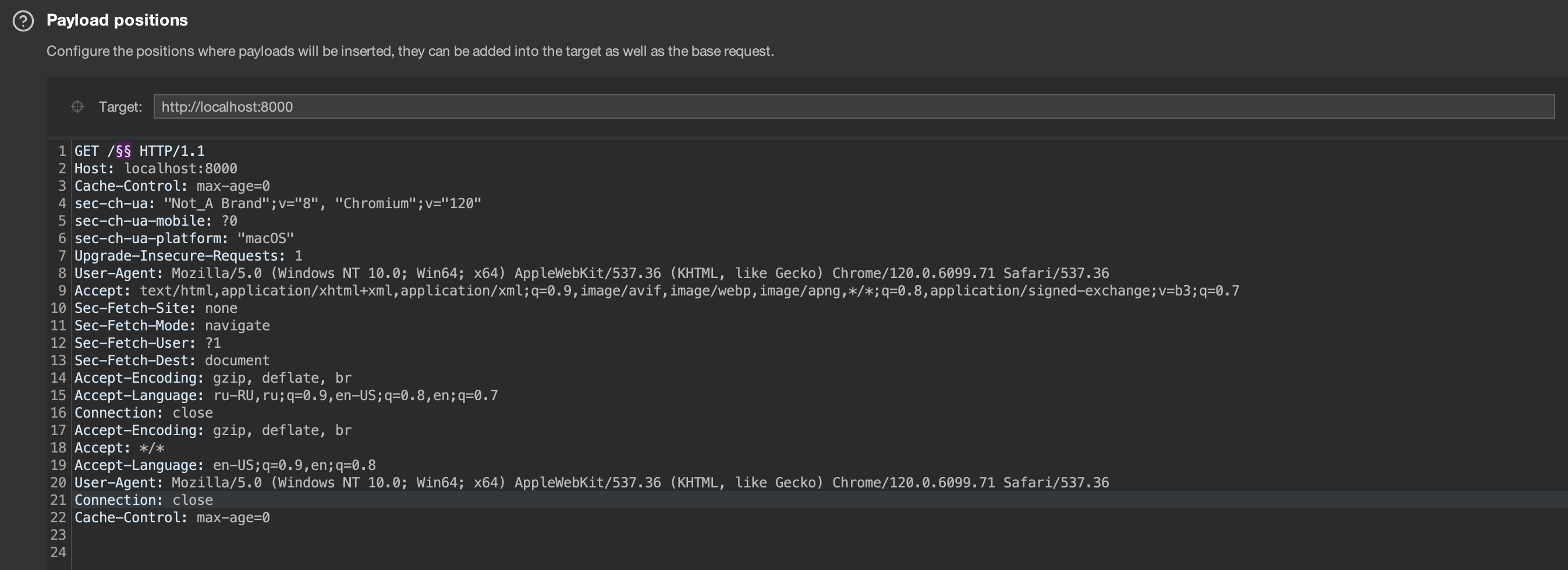
Из всех пробрученных названий файлов выделяется обращение к devdata.db (длинной ответа)
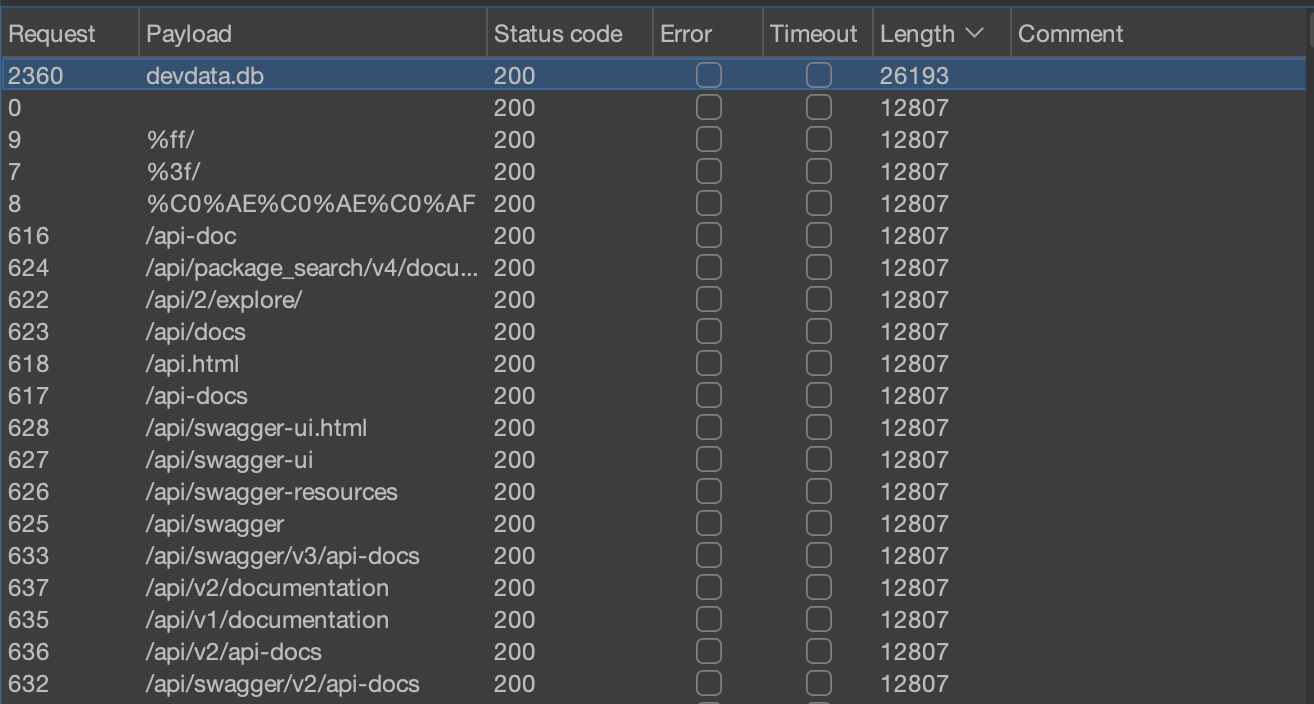
Находим внутри файла флаг визуально.
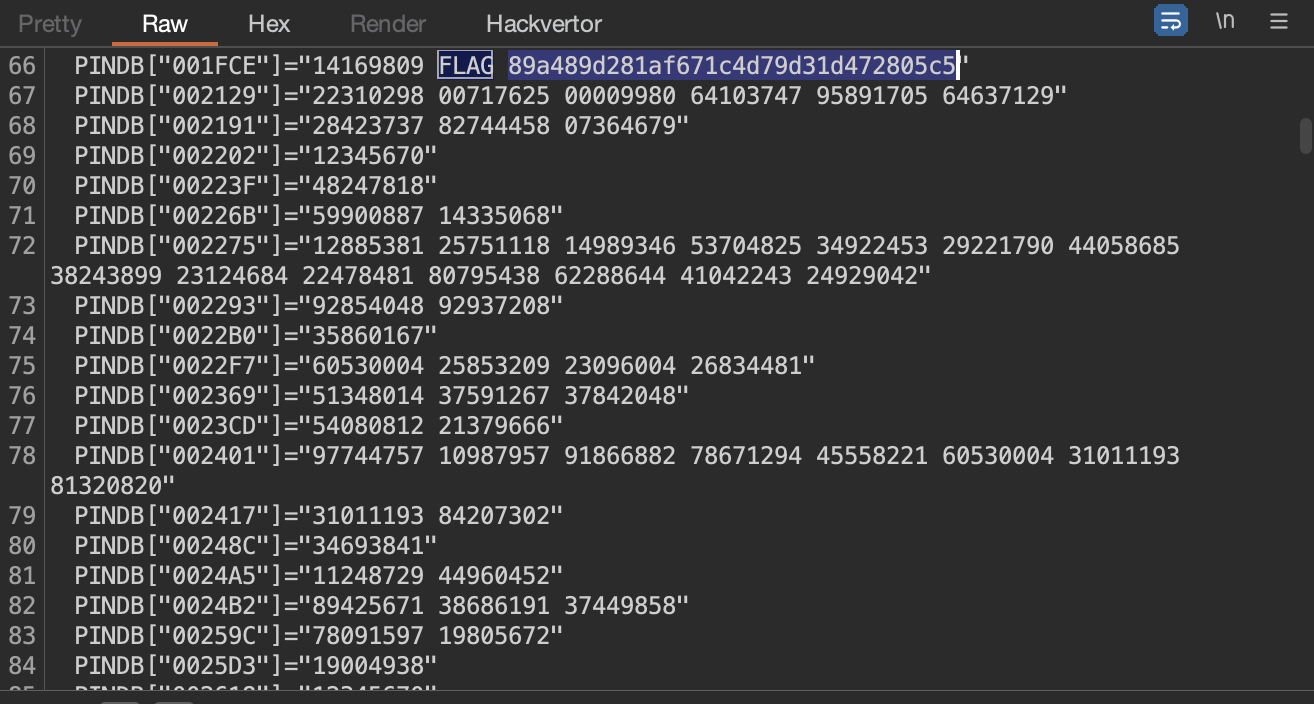
Для упрощения поиска можно грепнуть файл:

TASK 4. FLAG IN GIT
Последнее и самое заебищное. После развертки докера видим следующую картину:
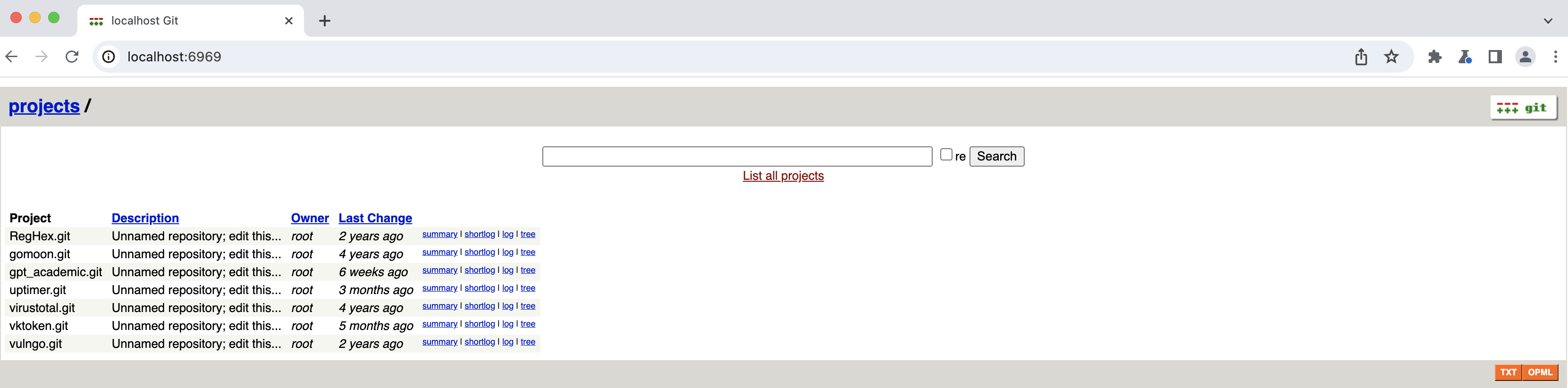
На самом деле это gitweb, который ссылается на репозитории настоящего GitHub.com. Но это неважно.
Заюзаем питон и https://pypi.org/project/beautifulsoup4/
import requests
from bs4 import BeautifulSoup
response = requests.get('http://localhost:6969/')
soup = BeautifulSoup(response.text, 'html.parser')
hrefs = []
for a in soup.find_all('a',{"class": "list"}, href=True, ):
hrefs.append(a['href'])
В результате простого вебскраппинга получаем пути к репозитория gitweb:
['/?p=RegHex.git;a=summary', '/?p=RegHex.git;a=summary', '/?p=gomoon.git;a=summary', '/?p=gomoon.git;a=summary', '/?p=gpt_academic.git;a=summary', '/?p=gpt_academic.git;a=summary', '/?p=uptimer.git;a=summary', '/?p=uptimer.git;a=summary', '/?p=virustotal.git;a=summary', '/?p=virustotal.git;a=summary', '/?p=vktoken.git;a=summary', '/?p=vktoken.git;a=summary', '/?p=vulngo.git;a=summary', '/?p=vulngo.git;a=summary']
Переходя по какому-нибудь из путей видим:
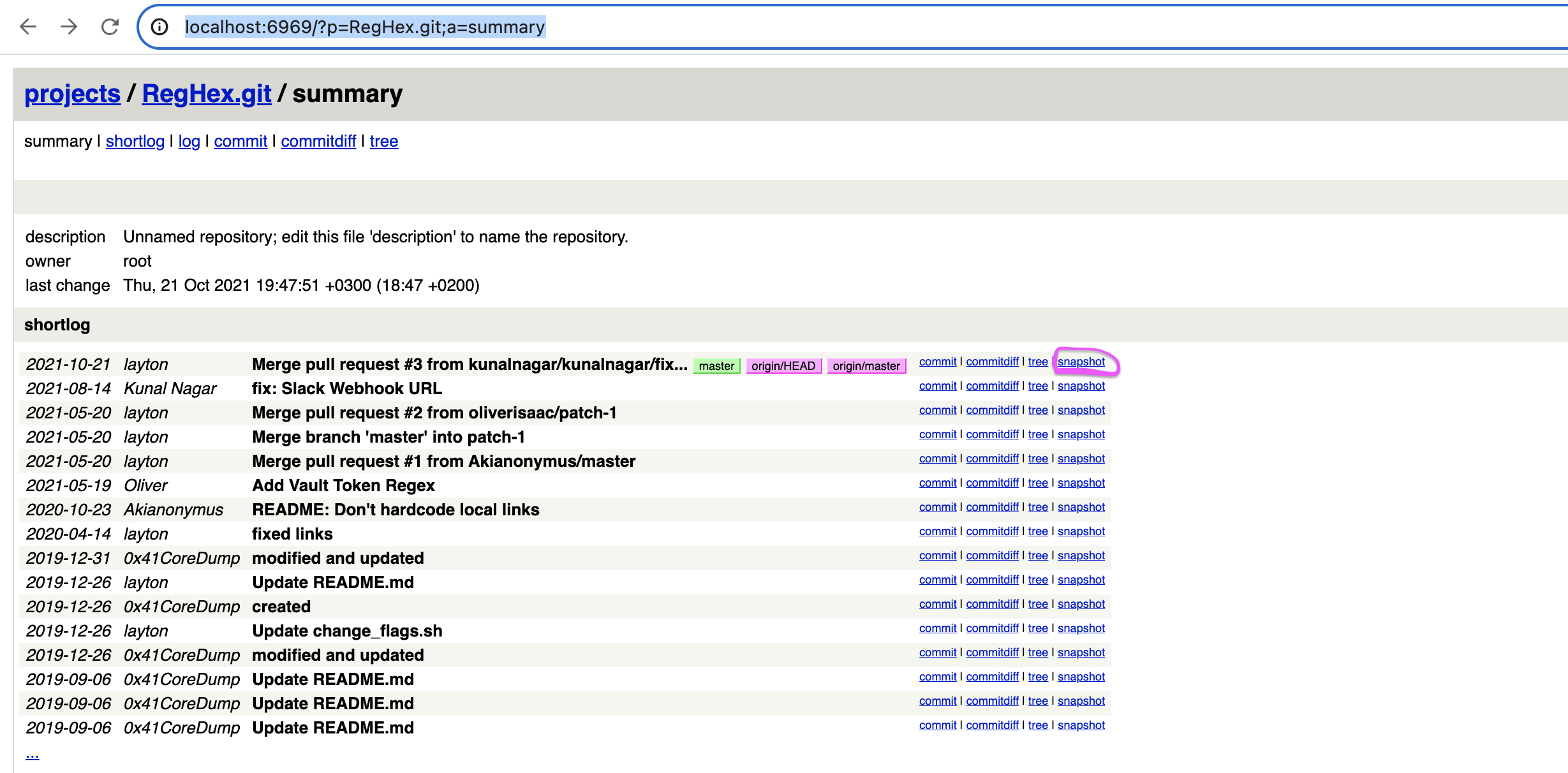
Что такое snapshot репозитория?

Таким образом нужно последнее состояние, хранящее наибольшее количество изменений.
Продолжаем парсить HTML нах 🤬
for href in hrefs:
repo_page = requests.get('http://localhost:6969/' + href)
repo_soup = BeautifulSoup(repo_page.text, 'html.parser')
table = repo_soup.find_all('table')
td = repo_soup.find('td', {"class": "link"})
string_value = td.__str__()
href_value = re.search(r'href="([^"]+)"', string_value).group(1)
cleaned_url = href_value.replace('//', '/')
href_values.append(cleaned_url)
href_values_unique_ = list(OrderedDict.fromkeys(href_values))
print(href_values_unique_)
В результате выполнения кода получаем список из ссылок на актуальные снэпшоты репозиториев:
['/?p=RegHex.git;a=commit;h=2320ba360a8293ae251b4daf8b395d7627d76baa', '/?p=gomoon.git;a=commit;h=f5f053d0ca99da2168aca56d080bb12ba8fc6cc2', '/?p=gpt_academic.git;a=commit;h=918c720983b2d98d2b9b852deb8a0a6f8406ba9a', '/?p=uptimer.git;a=commit;h=99a0eb220124a3029c793209a13b9a06e9378d18', '/?p=virustotal.git;a=commit;h=67ad1293f8c617ad65ff38696ac89e2ef3dc56f0', '/?p=vktoken.git;a=commit;h=7475c1b20bf68075704c462d6aedd031493cdd6f', '/?p=vulngo.git;a=commit;h=4b5d7bed0a26ab9a6626e8f026aa2b17ff6958ef']
По данным ссылкам можно их склонить:
import git # URL вашего репозитория repo_url = 'https://github.com/username/repository.git' # Локальный путь, куда будет склонирован репозиторий local_repo_path = '/путь/до/вашего/каталога' # Клонирование репозитория git.Repo.clone_from(repo_url, local_repo_path)
Что то вроде этого 💁♀️ Допишите сами.
После того как репозитории склонированы, мы можем исследовать историю гита каждого. Можно воспользоваться какой-нибудь тулзой, а можно визуально найти флаг или опять же грепнуть.
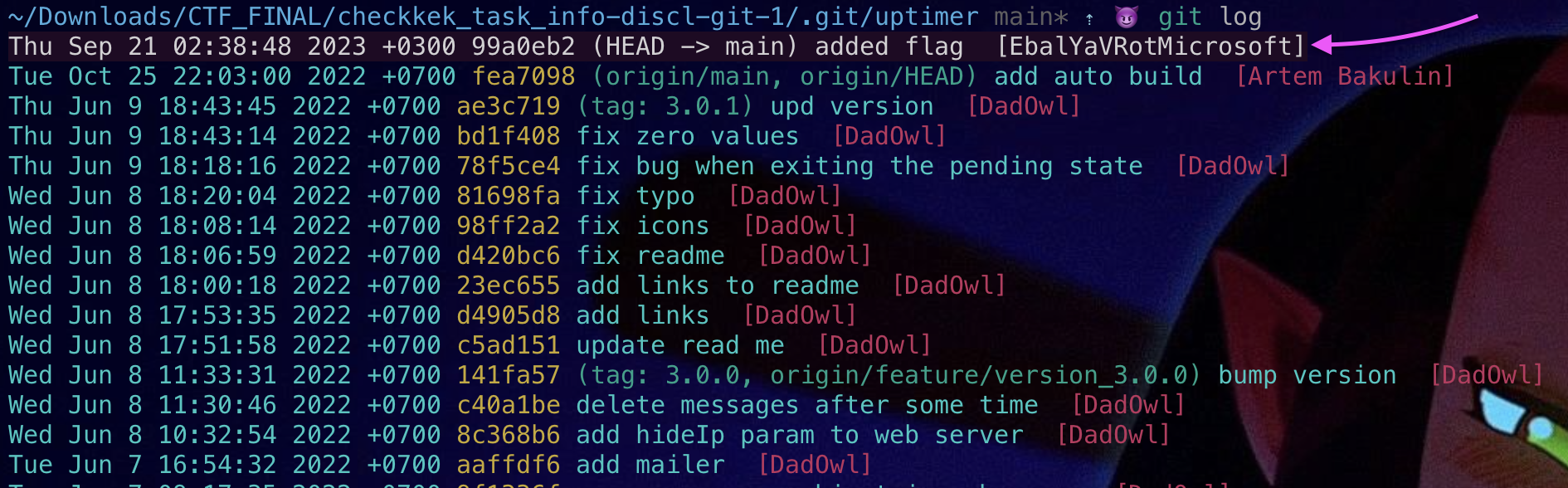
Кстати, можно было бы не вебскрапить и не автоматизировать
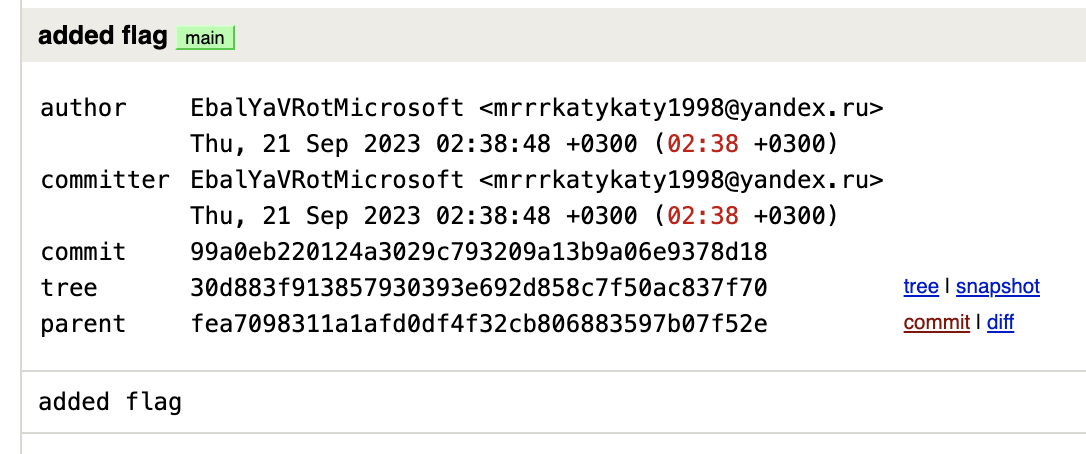
Эта инфа доступна в вебе НО заходить это правильнее всего. Потому что в реальной жизни информации может быть сильно больше.
И кстати, поиск по репам тоже лучше всего автоматизировать (в том числе и запуск тулзы).
repositories_directory="/путь/к/вашей/директории"
cd $repositories_directory
for repo in */; do
echo "Scanning repository: $repo"
trufflehog $repositories_directory/$repo
done
Спасибо что дочитал до конца 🐿 Обнимаю
ПЫСЫ если нада со мной связаться, контакт в шапке ❤️