Введение в байесовскую линейную регрессию
Nuances of programmingПеревод статьи William Koehrsen: "Introduction to Bayesian Linear Regression"

В академической среде принято выделеять два главных подхода к теории вероятности и статистического вывода: частотный и байесовский. На практике оба метода органично дополняют друг друга. Байесовские методы при правильном использовании помогают улучшить частотные предсказания.
Байесовские методы применяются в линейном моделировании. В этой статье будет дано базовое представление о линейной регрессии в классическом частотном понимании и дана байесовская интерпретация этого подхода. Кроме этого, данный подход будет применен на датасете, который отражает зависимость физических нагрузок и энергозатрат.
Что такое частотная линейная регрессия?
Частотная линейная регрессия знакома вам со школьной скамьи: модель предполагает существования некоторой зависимой переменной y ("переменная обратной реакции"), которая представляет собой линейную комбинацию предикативных аргументов (переменных) с весовыми коэффициентами. Также формула включает в себя "добавку", которая отвечает за ошибки, погрешности и шумы. Для случая двух независимых переменных имеем уравнение:

где y -- переменная обратной реакции, β-ы -- веса, x-ы -- предикативные переменные, ε -- остаточный член, включающий шумы и эффекты факторов, не учтенных в модели.
Линейную модель можно переписать в матричной форме, добавив константу 1 для свободного члена:

Цель состоит в обучении модели на тренировочном наборе данных для нахождения вектора коэффициентов β, который позволяет делать разумные предсказания. “Качество” можно измерять по методу наименьших квадратов. Для этого следует взять сумму квадратов разностей предсказанных и ожидаемых значений предикативной переменной:

Суммирование производится по N точкам тренировочного набора. ŷ -- оценка, выданная моделью. Продвинутая математика позволяет сделать т.н. оценку наиболее вероятных значений весов в матричной форме:

Этот эффективно реализован в библиотеке Scikit-Learn, сам метод, основанный на минимизации суммы RSS называется “метод обычных наименьших квадратов”.
При частотном подходе модель получает всю информацию исключительно из тренировочных данных. Посчитав “бету со шляпкой”, можно сразу получать предсказания:

Метод наименьших квадратов неплохо прогнозирует зависимость между продолжительностью физических упражнений и количеством потраченных калорий:

Метод наименьших квадратов дает универсальную зависимость, которую можно без труда можно записать как уравнение прямой:
calories = -21.83 + 7.17 * duration
Наклон говорит о том, что каждую минуту сжигается 7.17 калорий. Значение -21.83 нагрузки не несет, иначе при почти нулевой нагрузке можно было бы потерять почти 22 калории, что противоречит здравому смыслу.
Если потребуется получить оценку для 15.5 минут, то следует подставить это значение в уравнение:
calories = -21.83 + 7.17 * 15.5 = 89.2
Обычный метод наименьших квадратов дает предсказание в конкретной точке, без учета погрешности и доверительного интервала. Именно здесь на помощь приходит байесовская линейная регрессия.
Байесовская линейная регрессия
С байесовской точки зрения линейная регрессия формулируется в терминах вероятностных распределений. Переменная обратной реакции оценивается не как отдельная точка, а как значение из нормального распределения.
Запись такова:
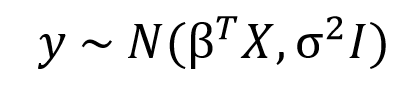
Вывод y генерируется из нормального распределения N, характеризуемого средним значением и дисперсией. Среднее значение -- транспонированной вектор весов, помноженный на матрицу предикативных переменных. Дисперсия -- квадрат стандартного отклонения σ , помноженного на единичную матрицу I для совпадения размерностей.
Цель модели -- не столько найти “лучшее” значение, сколько найти распределение апостериорных (полученных после опыта) значений. Параметры модели тоже подчиняются некоторому распределению . Далее имеем следствие из теоремы Байеса:

Здесь P(β|y, X) -- апостериарное распределение параметров модели при данных вводах и выводах. Это равняется вероятности вывода P(y|β, X), помноженного на априроную (до опыта) вероятность f β, при данном вводе. Все делится на константу нормализации. Это есть следствие теоремы Байеса, лежащей в основе вывода.
Теорема гласит: апостериарная вероятность = (вероятность * априорную вероятность)/(нормализация).
- Априорные данные: если в наличии есть некоторая область знаний, или имеются предположительные значения параметров, включенных в модель, то можно улучшить модель, применив эти знания. Частотный вывод таким свойством не обладает. Если в наличии таких данных нет, то можно использовать неинформативные априорные данные, например, нормальное распределение.
- Апостериорные данные: результат байесовской линейной регрессии -- распределение возможных параметров, основанное на данных и априорном знании. Это позволяет оценить неопределенность модели: чем меньше размер трен. данных, тем больше неопредленность.
Однако в случае перенасыщения данными вклад априорных данных становится очень мал, а на бесконечности модель сходится к значениям, полученным методом наименьших квадратов.
Применение байесовской линейной регрессии
Для применения байесовской линейной регрессии надо: определить априорные параметры модели, создать модель, отобразив тренировочный ввод на тренировочный вывод, получить апостериорное распределение методом Монте Карло по схеме марковских цепей. Конечным результатом будет апостериорное распределение параметров. Продолжив работу с датасетом, проделаем эти шаги. Примеры кода на Python находятся здесь.
Графики ниже показывают аппроксимации после 1000 шагов алгоритма.
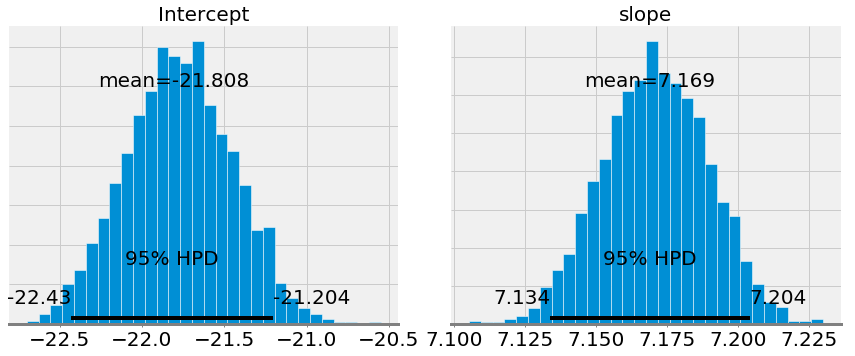
Видно, что полученные значения неплохо согласуются с данными, полученными в начале статьи методом наименьших квадратов (сдвиг был равен -21.83, а наклон 7.17). Чем больше данных получает модель, тем быстрее она сходится к какому-то конкретному наиболее вероятному значению.
Линейным представлением байесовской модели в данном случае является семейство прямых, параметры которых лежат в доверительных интервалах, предсказанных моделью.
Для демонстрационных целей было построено две модели: слева набор данных состоял из 500 точек (ограниченная информированность модели), а справа из 1500 (полная информированность модели). Красной линией обозначено то, что выдал байесовский подход, а пунктиром проведена линия, соответствующая методу наименьших квадратов.

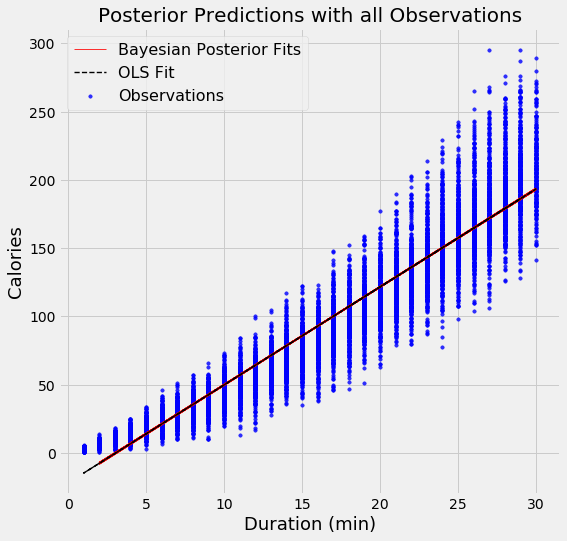
Видно, что при небольшом количестве данных доверительный интервал байесовской регрессии шире, что говорит о более высокой неопределенности. На полном наборе данных оба подхода идентичны.
Интересно, что даже если модель получает всего лишь одну точку, Байесовская модель вернет определенное распределение. В данном случае представлено распределение для набора данных из единственной точки 15.5 минут.

Заключение
Не стоит отдавать предпочтение только одной модели: байесовской или частотной. Надо умело пользоваться преимуществами обеих.
В задачах, которые предполагают наличие дополнительный сведений, байесовский подход может помочь воспользоваться дополнительным знанием и показать степень неопределенности. Таким образом, байесовский подход естественен: делается первоначальная оценка, которую впоследствии можно улучшают, предоставля дополнительные данные.