Введение в Apache Pig
#HadoopApache Pig — это высокоуровневая платформа или инструмент, который используется для обработки больших наборов данных. Он обеспечивает высокий уровень абстракции для обработки поверх MapReduce. Он предоставляет язык сценариев высокого уровня, известный как Pig Latin, который используется для разработки кодов анализа данных. Во-первых, для обработки данных, которые хранятся в HDFS, программисты напишут сценарии на языке Pig Latin. Внутренне Pig Engine (компонент Apache Pig) преобразовал все эти сценарии в конкретную карту и сократил задачу. Но они не видны программистам для обеспечения высокого уровня абстракции. Pig Latin и Pig Engine — это два основных компонента инструмента Apache Pig. Результат Pig всегда хранится в HDFS.
Примечание: Pig Engine имеет два типа среды выполнения, то есть локальную среду выполнения в одной JVM (используется, когда набор данных имеет малый размер) и распределенную среду выполнения в кластере Hadoop.
Need of Pig: Одним из ограничений MapReduce является то, что цикл разработки очень длинный. Написание редуктора и картографа, компиляция пакета кода, отправка задания и получение выходных данных — трудоемкая задача. Apache Pig сокращает время разработки, используя подход с несколькими запросами. Кроме того, Pig полезен для программистов, которые не имеют опыта работы с Java . 200 строк Java-кода могут быть записаны всего в 10 строк с использованием языка Pig Latin. Программистам, обладающим знаниями SQL, нужно меньше усилий, чтобы выучить Pig Latin.
Эволюция Apache Pig: в начале 2006 года исследователи Yahoo разработали Apache Pig. В то время основной идеей разработки Pig было выполнение заданий MapReduce для очень больших наборов данных. В 2007 году он перешел на Apache Software Foundation (ASF), что делает его проектом с открытым исходным кодом. Первая версия ( 0.1 ) Pig была выпущена в 2008 году. Последняя версия Apache Pig — 0.18, выпущенная в 2017 году.
Особенности Apache Pig:
- Для выполнения нескольких операций Apache Pig предоставляет богатый набор операторов, таких как фильтры, объединение, сортировка и т. Д.
- Легко учиться, читать и писать. Специально для SQL-программиста Apache Pig — это благо.
- Apache Pig является расширяемым, так что вы можете создавать свои собственные пользовательские функции и процессы.
- Операция соединения легко в Apache Pig.
- Меньше строк кода.
- Apache Pig позволяет расколоть в конвейере.
- Структура данных многозначна, вложена и богаче.
- Свинья может обрабатывать анализ как структурированных, так и неструктурированных данных.
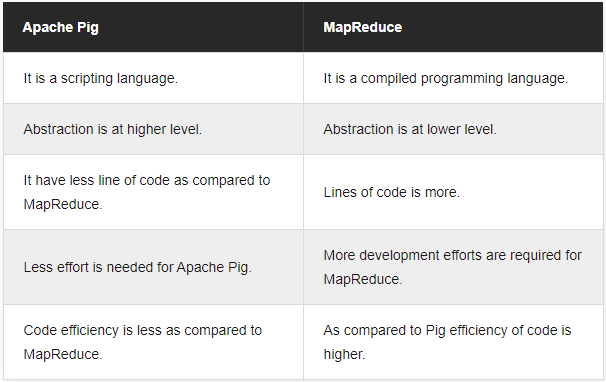
Разница между Apache Pig и MapReduce
Приложения Apache Pig:
- Для изучения больших наборов данных используется Pig Scripting.
- Обеспечивает поддержку больших наборов данных для специальных запросов.
- В прототипировании алгоритмов обработки больших наборов данных.
- Требуется для обработки чувствительных ко времени загрузок данных.
- Для сбора большого количества наборов данных в виде журналов поиска и веб-сканирований.
- Используется там, где необходимы аналитические данные с использованием выборки.
Типы моделей данных в Apache Pig.
Он состоит из 4 типов моделей данных:
- Atom : это атомарное значение данных, которое используется для хранения в виде строки. Основное использование этой модели заключается в том, что она может использоваться как число, а также как строка.
- Кортеж : это упорядоченный набор полей.
- Сумка : это коллекция кортежей.
- Карта : это набор пар ключ / значение.