Все что вам нужно знать о таймаутах
https://t.me/ai_machinelearning_big_data
Никто не любит ждать и мы в Zalando не исключение. Мы не любим когда наши клиенты долго ждут доставку, мы не любим когда наши клиенты долго ждут оформления заказа и мы не любим медленные микросервисы. В этой статье мы говорим о том как установить оптимальное значение таймаутов в микросервисной архитектуре, чтобы достичь максимальной производительности и отказоустойчивости.
Зачем устанавливать таймауты
Давайте для начала ответим на простой вопрос: "Зачем устанавливать таймауты?". Успешный ответ сервиса, даже если он занимает много времени, лучше, чем ошибка закрытия соединения по таймауту. Хм... не всегда, давайте разбираться.
Прежде всего если сервис не отвечает или отвечает слишком медленно, никто не будет ждать. Вместо того чтобы испытывать терпение ваших пользователей, следуйте принципу fail-fast. Позвольте вашим клиентам повторить запрос или обработать ошибку на их стороне. Когда возможно, возвращайте fallback значение.
Другой важный аспект - это утилизация ресурсов. В то время пока клиент ожидает ответ, различные ресурсы используются на стороне сервиса: треды, http коннекшены, коннекшены базы данных и т.д. Даже если клиент закроет соединение, без правильной конфигурации таймаутов запрос будет обрабатываться на сервере, а это значит что ресурсы будут заняты.
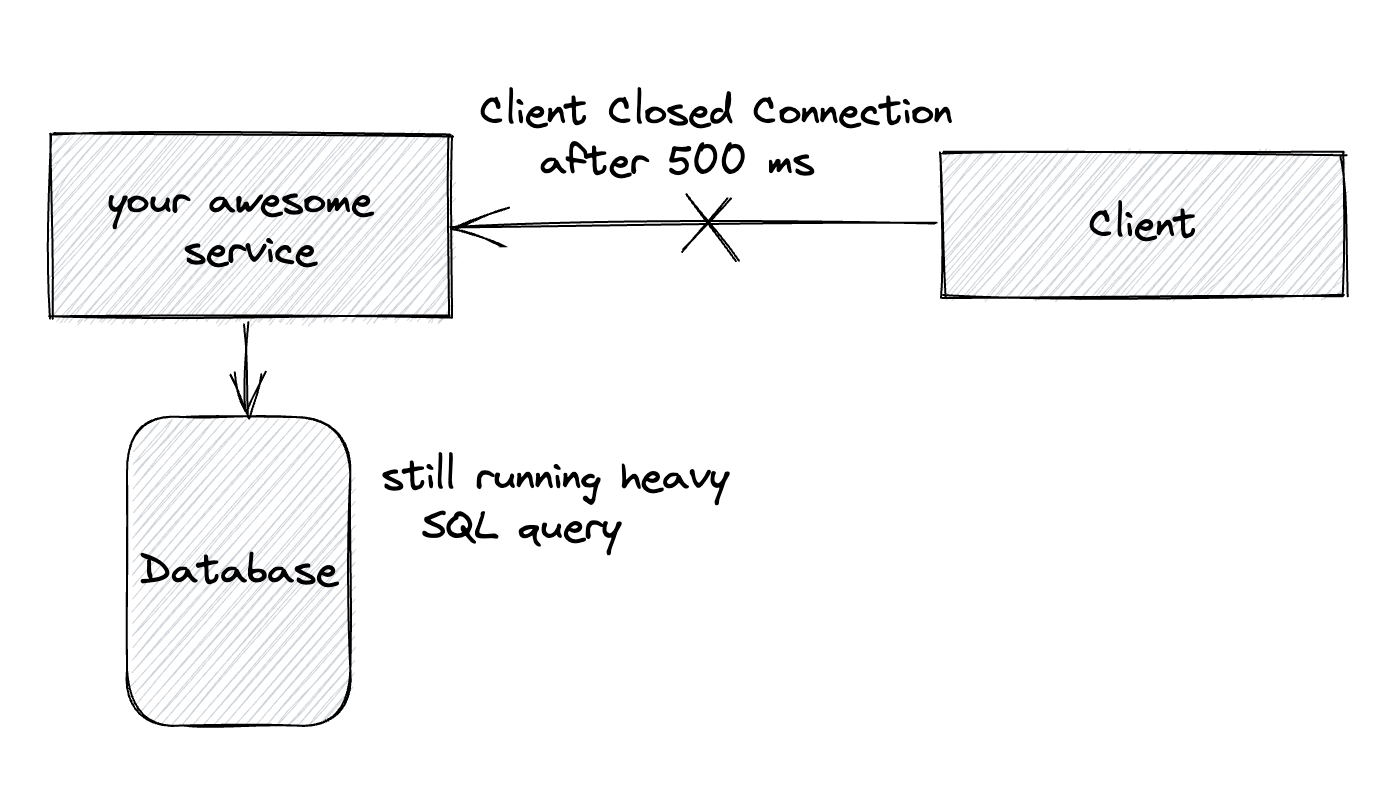
Помните, увеличивая таймауты вы потенциально уменьшаете пропускную способность вашего сервиса!
Использование бесконечных или слишком больших таймаутов - это плохая стратегия. Некоторое время вы не будете замечать проблему, до тех пор пока у одного из сервисов, который вы используете, не начнутся проблемы и у вас исчерпается конекшен-пул.
К сожалению, многие библиотеки устанавливают слишком большой таймаут по дефолту, или отключают таймауты совсем. Авторы библиотек стремятся привлечь как можно больше пользователей и стараются сделать так, чтобы их библиотека работала в большинстве ситуаций. Но для продакшен сервисов - это недопустимо. Это может быть даже опасным. Например, в нативном java HttClient connection/request таймауты отключены, я не думаю что это в рамках вашего SLA :)
Дефолтный таймаут - это ваш враг, всегда устанавливайте таймауты вручную!
Connection timeout или request timeout
Существует путаница в том, что же такое connection timeout и request timeout. Сначала, давайте просмотрим что же такое connection timeout.
Если вы погуглите или спросите ChatGPT, вы получите что-то вроде этого:
Таймаут соединения - это максимальное время, которое клиент готов ждать при попытке установить соединение с сервером. Он измеряет время, необходимое клиенту для успешного установления сетевого соединения с сервером. Если соединение не установлено в течение указанного таймаута, попытка установления соединения считается неудачной, и клиенту обычно возвращается сообщение об ошибке.
Но что значит "установить соединение с сервером"? TCP использует так-называемое Трёхстороннее рукопожатие (Three-way handshake) для того чтобы установить надежное соединение. TCP соединение является полнодуплексным, обе стороны синхронизируют (SYN) и подтверждают (ACK) друг друга. Обмен этими четырьмя флагами происходит в три этапа - SYN, SYN-ACK и ACK.
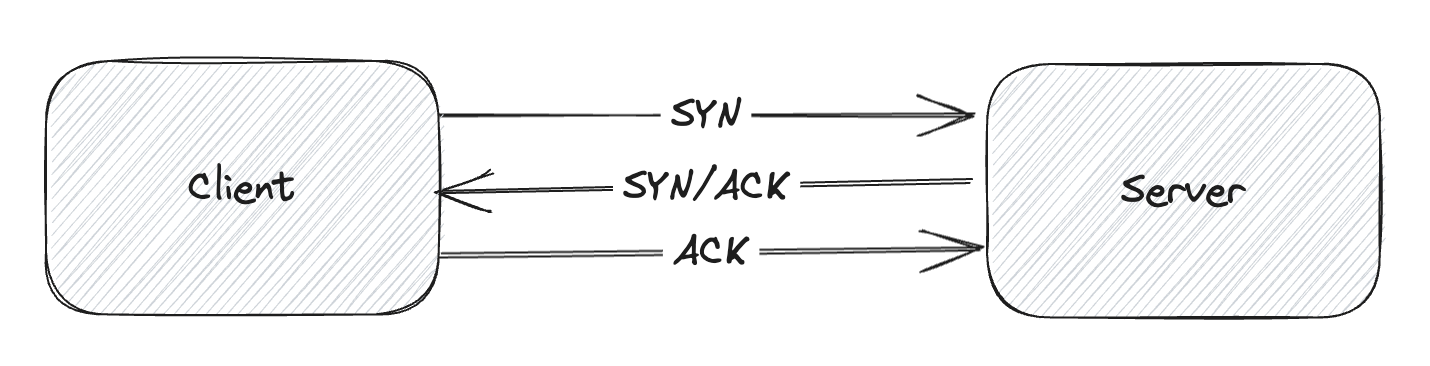
Connection timeout должен быть достаточным для завершения этого процесса, а фактическая передача пакетов зависит от качества соединения.
Проще говоря, значение connection timeout должно зависеть от качества сети между сервисами. Если удаленный сервис работает в том же датацентре или в том же облачном регионе, то время соединения должно быть низким. И наоборот, если вы работаете над мобильным приложением, то время соединения с удаленным сервисом может быть достаточно высоким.
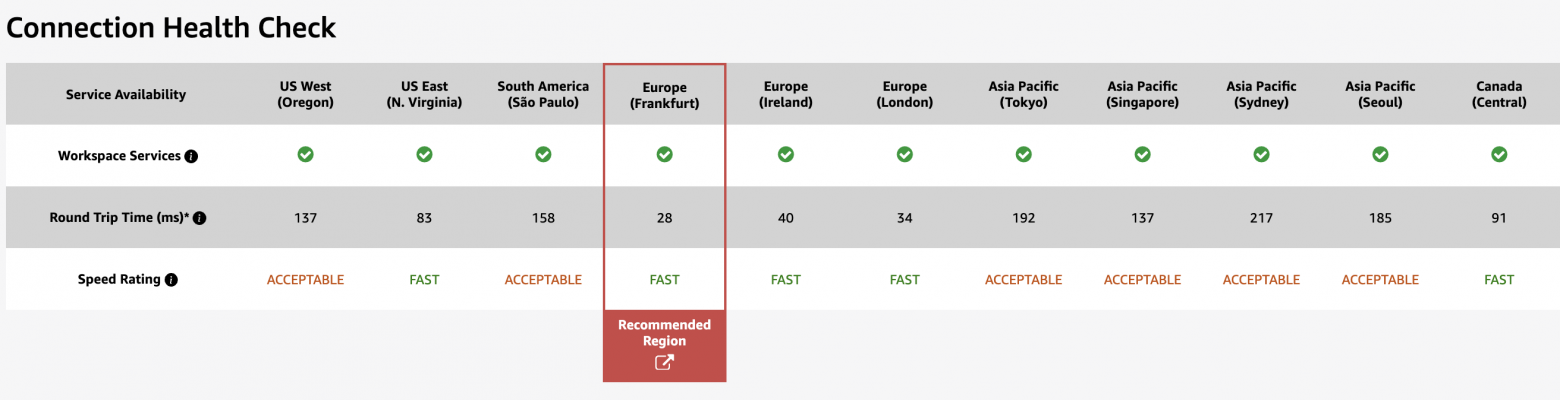
Для наглядности. Round-trip time (RTT) в оптоволокне, от Нью-Йорка до Сан-Франциско ~42 мс, от Нью-Йорка до Сиднея ~160 мс. Вы также можете посмотреть на Connection Health Check от Amazon. Вот что я получаю с моей локальной машины: RTT 28 мс до рекомендованного региона AWS.
В каких случаях возникает connection timeout
Connection timeout возникает только при попытке установить TCP соединение. Обычно это происходит, если удаленная машина не отвечает. Это означает, что сервер был выключен, вы использовали неправильное IP/DNS имя, неправильный порт или отсутствует соединение с сервером. Другая частая ситуация - когда удаленная точка просто отбрасывает пакеты без ответа. Брандмауэр или параметры безопасности сервера могут быть настроены на отбрасывание определенных типов пакетов или трафика от определенных источников.
Connection timeout best practices
Общепринятой практикой для микросервисов является установка connection timeout, равного или немного меньшего, чем request timeout. Такой подход является ошибочным, поскольку это два, совершенно разных процесса. Если установление соединения - относительно быстрый процесс, то обработка запроса может занять сотни или тысячи миллисекунд!
Вместо этого вы можете установить connection timeout равный ожидаемому RTT умноженному на некоторый коэффициент. В качестве консервативного подхода обычно используется значение connection timeout = RTT * 3, но конечно, коэффициент можно изменять в зависимости от конкретных потребностей.
В общем случае connection timeout для микросервиса должен быть достаточно низким, чтобы можно было быстро обнаружить недоступный сервис, но достаточно высоким, чтобы сервис мог запуститься или восстановиться после кратковременной проблемы.
Request Timeout
Request timeout, с другой стороны, означает максимальное время, в течение которого клиент готов ждать ответа от сервера после успешного установления соединения. Он измеряет время, необходимое серверу для обработки запроса клиента и предоставления ответа.
Устанавливаем оптимальное значение request timeout
Представьте что вы собираетесь интегрировать ваш сервис с новым REST API.
На первом этапе вы можете посмотреть на SLA которые предоставляет сервис с котором вы интегрируетесь. К сожаление не все сервисы предоставляют SLA, но даже если вам повезло и сервис предоставляет некие гарантии, то не стоить доверять им вслепую. SLA можно использовать как базовое значение для тестирования реального latency.
Если возможно, сперва интегрируйте новый сервис в так называемом shadow-mode и соберите метрики. Интеграция с новым сервисом должна работать на проде, но не должна оказывать влияния на реальные бизнес-процессы (вызывайте сервис в отдельном тред-пуле, зеркалируйте трафик и т.д)
После того как вы соберете метрики latency, такие как p50, p99, p99.9 вы можете определить так называемый порог допустимых таймаутов. Допустим, вы выбрали порог допустимых таймаутов = 0,1 %, это значит, что максимальный таймаут, который вы можете установить равен p99,9 latency сервиса с которым вы интегрируетесь.
На этом этапе вы знаете максимальное значение таймаута которое вы можете установить, но есть одна дилемма:
- установить таймаут на максимально допустимое значение
- уменьшить таймаут и включить retry
В зависимости от результатов тестирования вам нужно будет выбрать стратегию таймаутов. В каких случаях использовать retry читайте ниже.
Следующее испытание с которым вам предстоит столкнуться это цепочка вызовов сервисов. Представьте SLA вашего сервиса 1000 мс, ваш сервис последовательно вызывает сначала Order Service у которого latency p99.9 = 700 мс, затем ваш сервис вызывает Payment Service, latency которого также 700 мс. Как настроить таймауты чтобы остаться в рамках SLA?
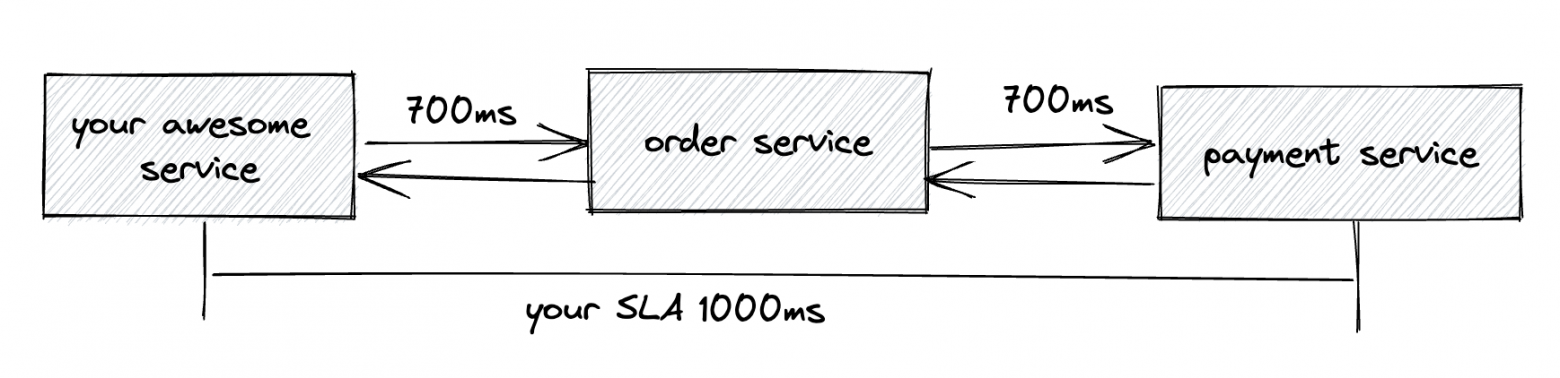
Вариант 1: Один из вариантов — разделить свой "бюджет" времени (ваше SLA) между сервисами и установить таймауты соответственно 500 мс для Order Service и 500 мс для Payment Service. В этом случае у вас есть гарантия, что вы не нарушите SLA, но у вас могут возникнуть ложные таймауты.
Вариант 2: Добавить TimeLimiter для вашего API. Маловероятно что два различных сервиса будут одновременно отвечать с максимальной задержкой. Вы можете обернуть цепочку вызовов в time limiter и установить максимально допустимый таймаут для обоих сервисов. В этом случае вы могли бы установить time limiter 1 сек. для вашего API и установить таймаут 700 мс. для зависимых сервисов.
На Java, вы могли бы использовать CompletableFuture который предоставляет встроенные методы для работы с таймаутами, такие как orTimeout и completeOnTimeout
CompletableFuture
.supplyAsync(orderService.placeOrder(...))
.thenApply(paymentService.updateBalance(...))
.orTimeout(1, TimeUnit.SECONDS);
Есть также неплохой TimeLimiter модуль в библиотеке Resilience4j
Retry or not retry
Идея проста - при ошибке делайте повторную попытку, когда есть шанс на успех.
Временные сбои: повторный запрос при ошибке (retry) подходит для временных сбоев, которые, как ожидается, будут устранены через некоторое время, такие как сетевые сбои, таймауты сервера или проблемы с подключением к базе данных. Повторный запрос также может помочь избежать проблемы "медленного/перегруженного" сервера. При достаточно большом развертывании (например, 100 серверов/контейнеров) один сервер может существенно снизить производительность, но если нагрузка на запросы распределена достаточно случайным образом, то повторный запрос будет быстрее, чем ожидание ответа от перегруженного сервера.
- retry при таймаутах и ошибках 5xx
- не стоит повторят запрос при ошибках 4xx
Идемпотентные операции: Если выполняемая операция является идемпотентной, т.е. ее многократное выполнение приводит к тому же результату, что и однократное, то повторные попытки, как правило, безопасны.
Неидемпотентные операции при многократном повторении могут вызвать нежелательные побочные эффекты. В качестве примера можно привести операции, изменяющие данные, выполняющие финансовые операции или имеющие необратимые последствия. Повторное выполнение таких операций может привести к несогласованности данных или дублированию действий.
Даже если вы считаете, что операция является идемпотентной, по возможности спросите владельца сервиса, стоит ли разрешать повторные запросы.
Для безопасного повторения запросов без случайного выполнения одной и той же операции дважды, рассмотрите возможность поддержки дополнительного заголовка Idempotency-Key в вашем API. При создании или обновлении объекта используйте idempotency-key. Тогда при возникновении ошибки соединения можно безопасно повторить запрос, не рискуя создать второй объект или дважды выполнить обновление. Подробнее об этом паттерне можно прочитать здесь Idempotent Requests by Stripe и Making retries safe with idempotent APIs by Amazon
Circuit breaker: при использовании retry, всегда рассматривайте возможность реализации circuit breaker. Когда сбои происходят редко, это не проблема. Повторные попытки, увеличивающие нагрузку, могут значительно ухудшить ситуацию.
Exponential backoff: реализация exponential backoff может быть эффективной retry стратегией. Она предполагает экспоненциальное увеличение задержки между каждой повторной попыткой, что позволяет снизить нагрузку на проблемный сервис и предотвратить его перегрузку повторными запросами. Здесь вы найдете замечательный блог о том как Амазон поддерживает exponential backoff в их SDK AWS SDKs support exponential backoff and jitter.
Time-sensitive operations: Повторные попытки могут быть бесполезны для операций, критичных ко времени. Компромисс здесь заключается в том, чтобы уменьшить таймаут и выполнить повторный запрос при ошибке или оставить максимально допустимое значение таймаута. Повторные запросы могут не сработать, если p99.9 близко к p50.
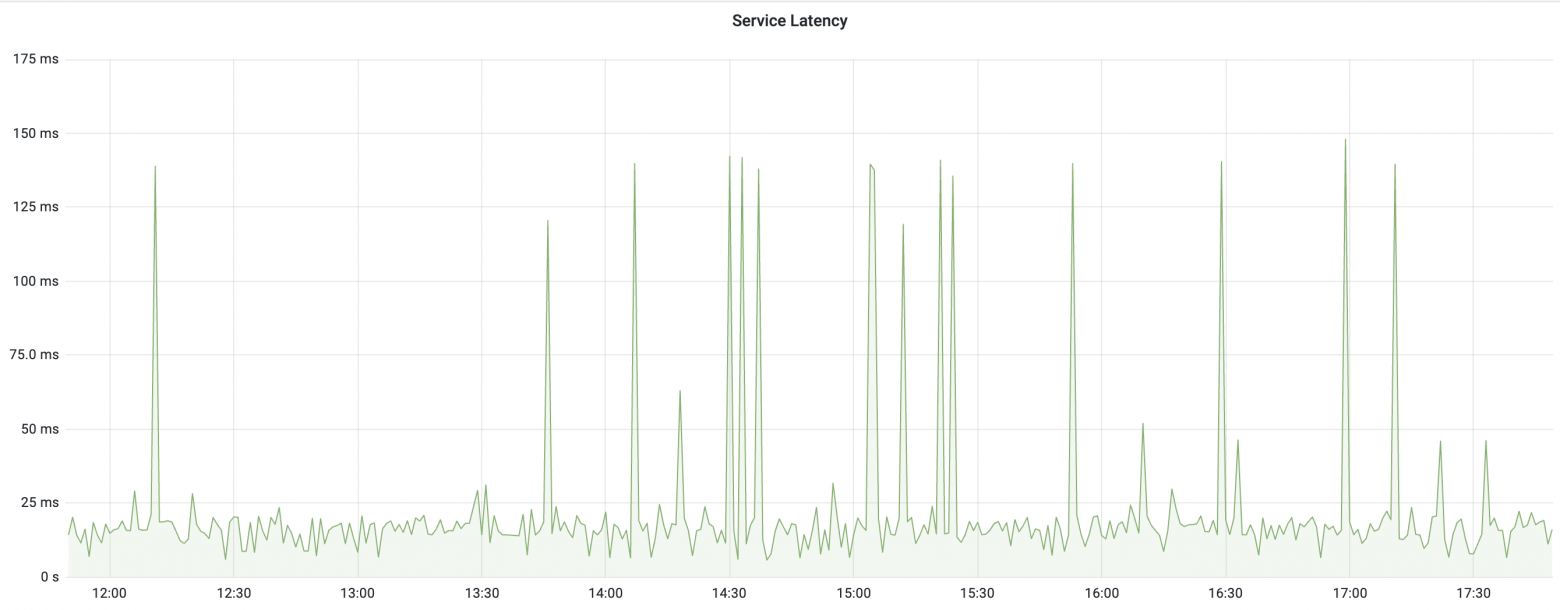
Посмотрите на первый график. Таймауты случаются редко, большая разница между latency p99.9 и p50, хороший кандидат для включения retry механизма.
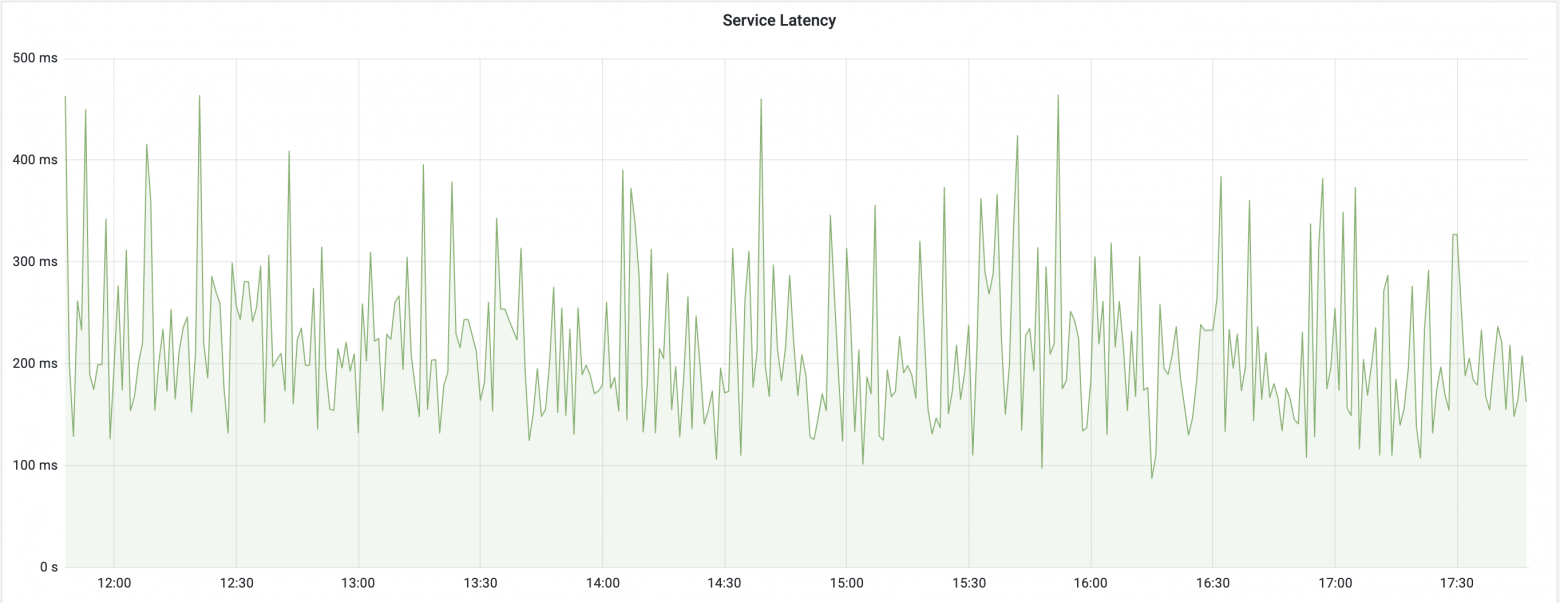
На втором графике, таймауты случаются периодически, latency p99 близко к значению p50, в этом случае не стоит включать retry и повторять запросы.
Подведем итоги
- всегда явно устанавливайте таймаут для любых запросов
- устанавливайте connection timeout = ожидаемый RTT * 3
- устанавливайте request timeout основываясь на собранных метриках и SLA
- fail-fast или возвращайте fallback ответ
- рассмотрите возможность обернуть цепочку вызовов в time limiter
- повторяйте запрос при 5xx ошибках и не повторяйте при 4xx
- подумайте о реализации circuit breaker когда используете retry
- будьте вежливы и попросите у владельца API разрешения на использование retry
- добавьте поддержку
Idempotency-Keyheader в ваш API