Внутреннее устройство Kubernetes-кластера простым языком
Сетевик Джонни
Предисловие
Мы уже говорили о концепции master-slave в Kubernetes. Один узел контролирует все остальные. В Kubernetes все устроено именно таким образом. Но мы ещё не рассматривали, КАК работает связка master-slave. Что именно делает мастер-узел (master node)? Итак, начнём...
Общая картина
Примерно так выглядит типичный мастер-узел:
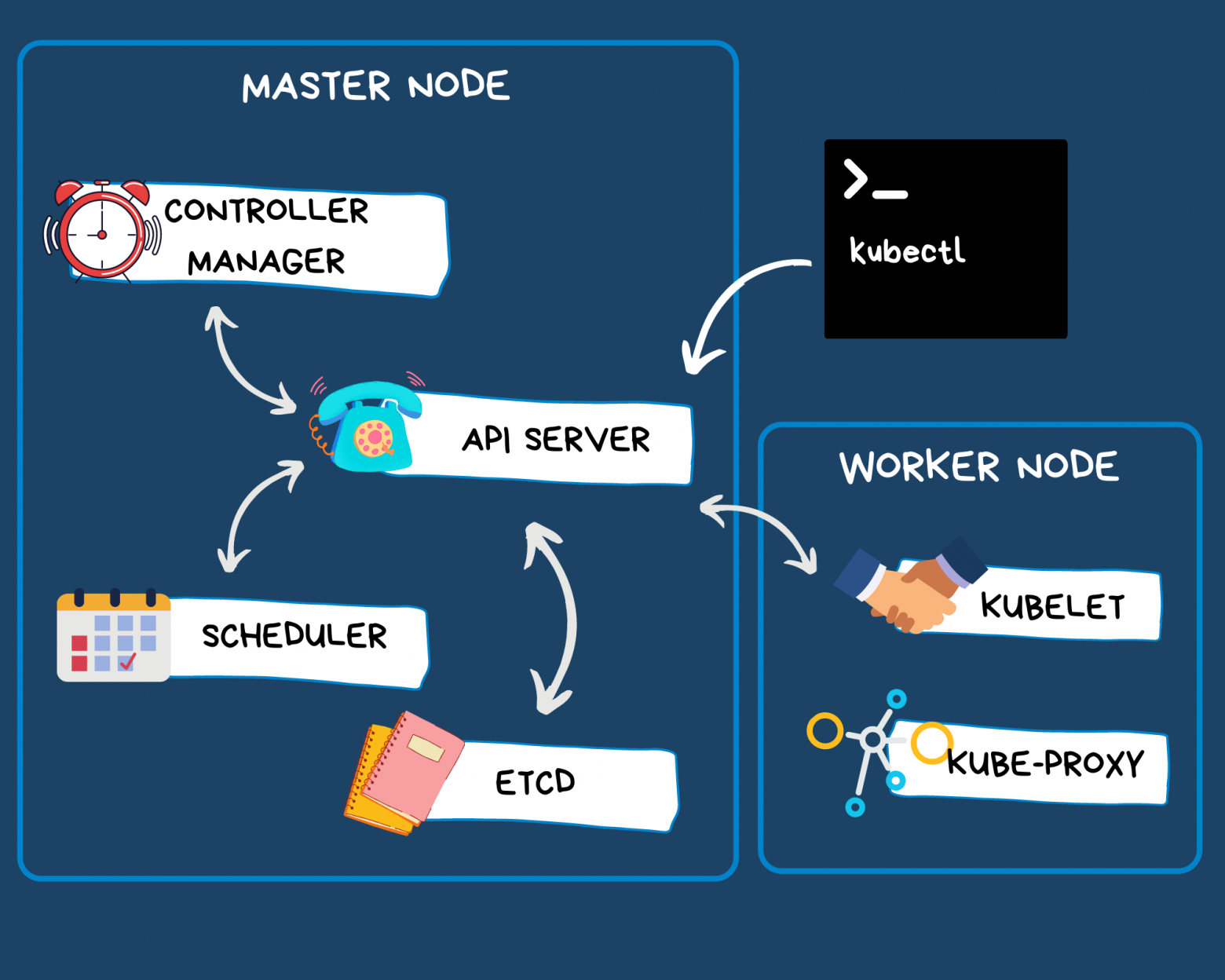
«Команда» Control Plane
На мастер-узле, также известном как Control Plane (иногда его переводят как «управляющий слой» — прим. перев.), выполняется большинство важных задач по управлению и администрированию кластера. Он включает в себя четыре основных компонента:
- API server (API-сервер);
- scheduler (планировщик);
- controller manager (менеджер контроллеров);
- etcd.
Давайте подробнее остановимся на каждом из них.
API server
Самый первый, и, пожалуй, самый важный — API-сервер. Это «лицо» Kubernetes. Чтобы взаимодействовать с кластером Kubernetes, вам наверняка придется познакомиться с API-сервером:
Для любых манипуляций с кластером приходится обращаться к API-серверу с помощью Kubernetes API. Используете kubectl, REST или любую из клиентских библиотек Kubernetes? Все они завязаны на API Kubernetes'а и взаимодействуют с API-сервером.
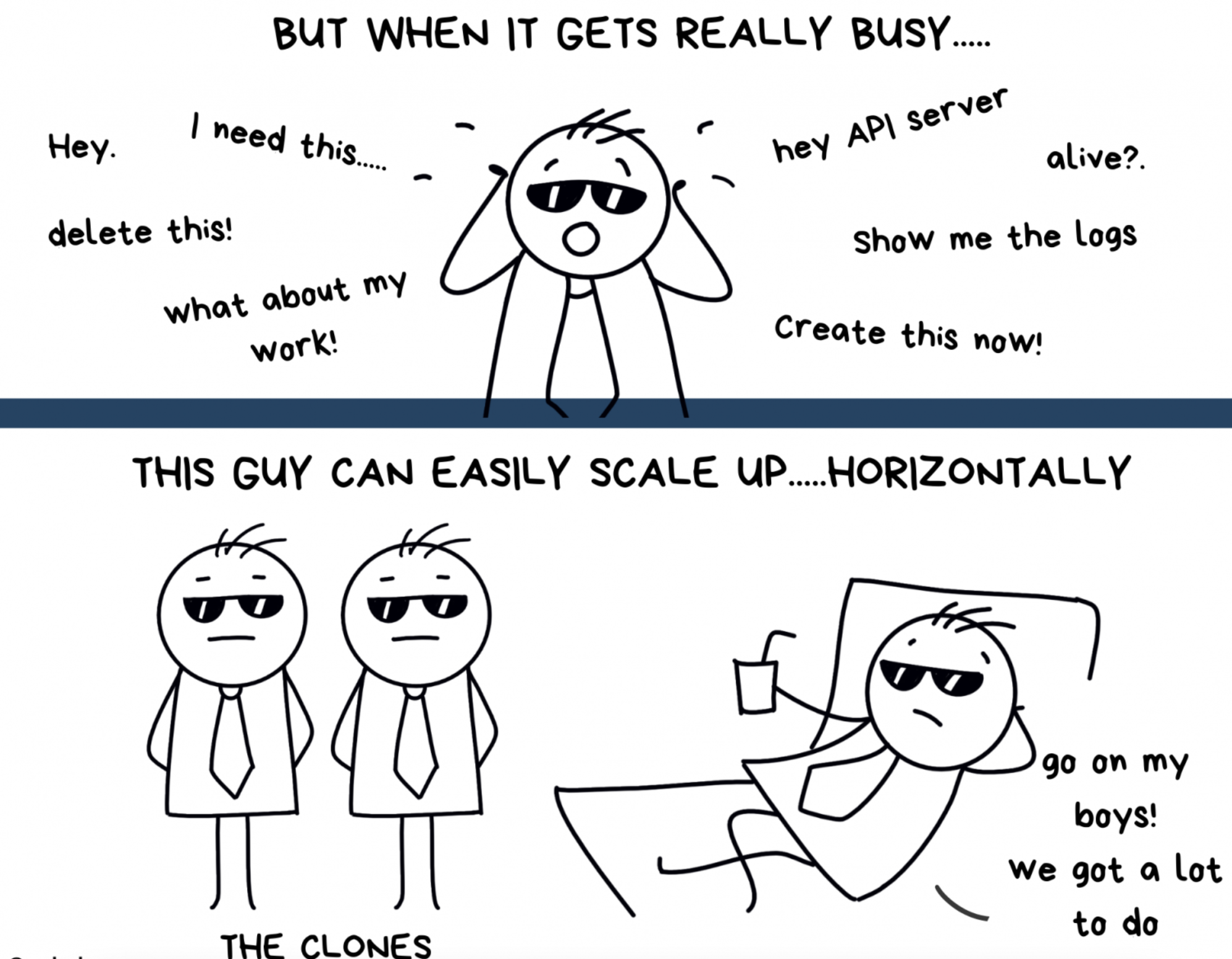
— Эй, мне нужно то. — Эй, удали это! — Эй, API-сервер, ты там жив? — Покажи логи! — А как же моя работа? — Создай-ка вон то!
Этот парень с лёгкостью масштабируется… горизонтально. — Вперёд, ребятки! Ещё полно работы.
Примечательная особенность API-сервера состоит в том, что он умеет масштабироваться по горизонтали. Другими словами, при резком увеличении количества поступающих запросов API-сервер может создавать «клоны» или реплики самого себя, чтобы справиться с нагрузкой.
Scheduler
Следующий компонент — планировщик. Как вы думаете, что он делает? Правильно, планирует.
Давайте разбираться:

— То есть ты утверждаешь, что тебе нужны все эти ресурсы? — Ага!
Новый Pod остается в статусе Pending до тех пор, пока ему не будет выделен узел для работы (рекомендую обратиться к соответствующей статье о Pod'ах). Именно за это отвечает планировщик:
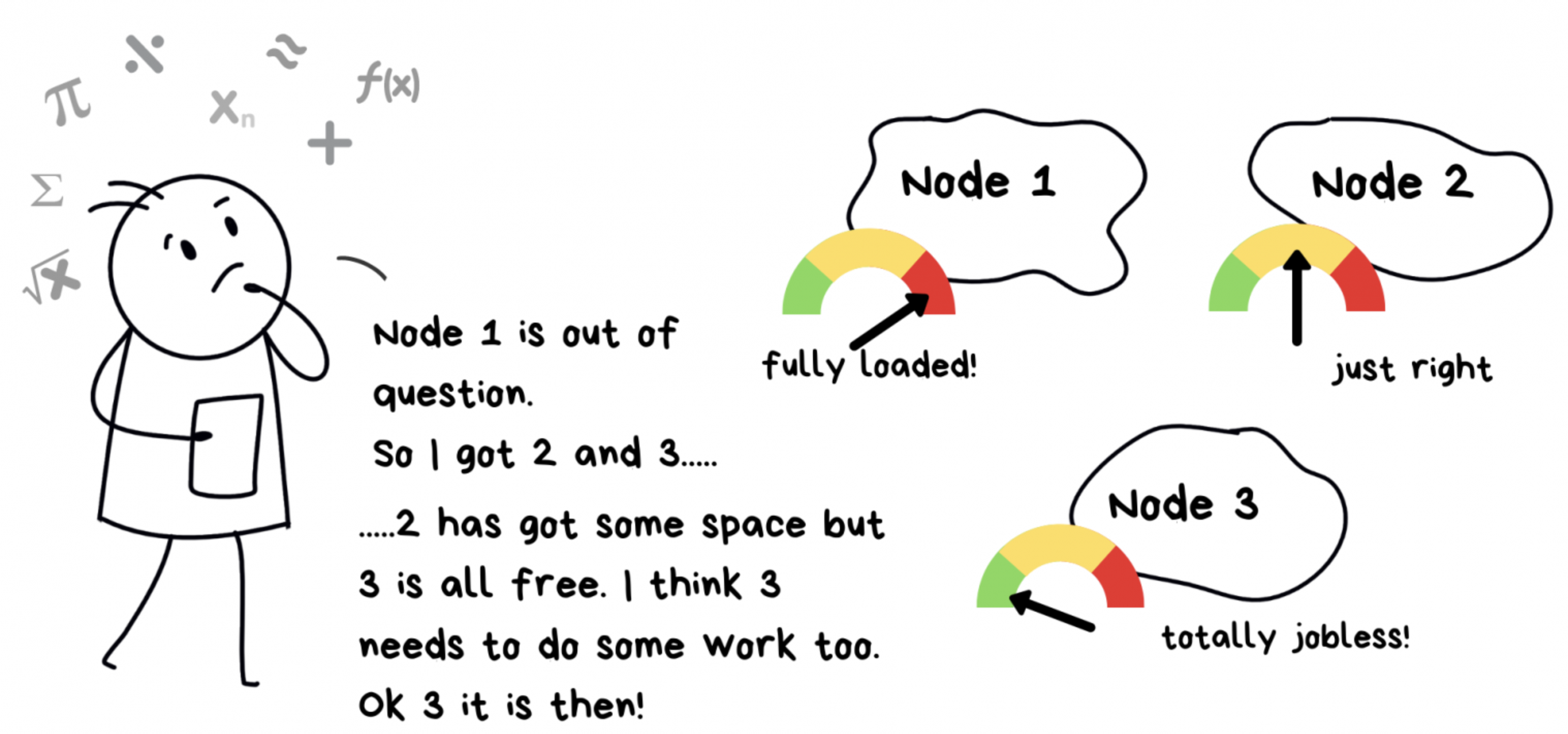
— С первым узлом всё понятно. Итак, остались 2 и 3… У 2-го ещё есть чуток ресурсов, а 3-й вообще свободен. Думаю, ему надо чем-то заняться. Ок, тогда 3-й!
Каждому Pod’у требуются определенные ресурсы: память, CPU, железо… в общем, стандартный набор. Планировщик должен решить, какой узел соответствует требованиям Pod’а. Поэтому планировщик выполняет два действия:
- Подбирает узлы-кандидаты для Pod’а;
- Останавливает свой выбор на одном из них.
Controller manager
Прежде всего стоит узнать, что такое Контроллер.
Я люблю называть его компонентом, который «всё исправляет». Почему? Потому что работа у него такая — приводить в норму. Поясню. Он наблюдает за кластером — словно хищная птица за добычей, без устали и покоя. Если что-то идёт не так, контроллер предпринимает соответствующие действия для исправления ситуации.
Иными словами, у кластера есть состояние, называемое желаемым (англ. desired state). Именно в таком состоянии должен находиться кластер. Контроллер считает его единственно верным. С другой стороны, в каждый момент времени кластер находится в состоянии, называемом текущим (current state). Контроллеры будут делать всё, чтобы привести текущее состояние к желаемому.
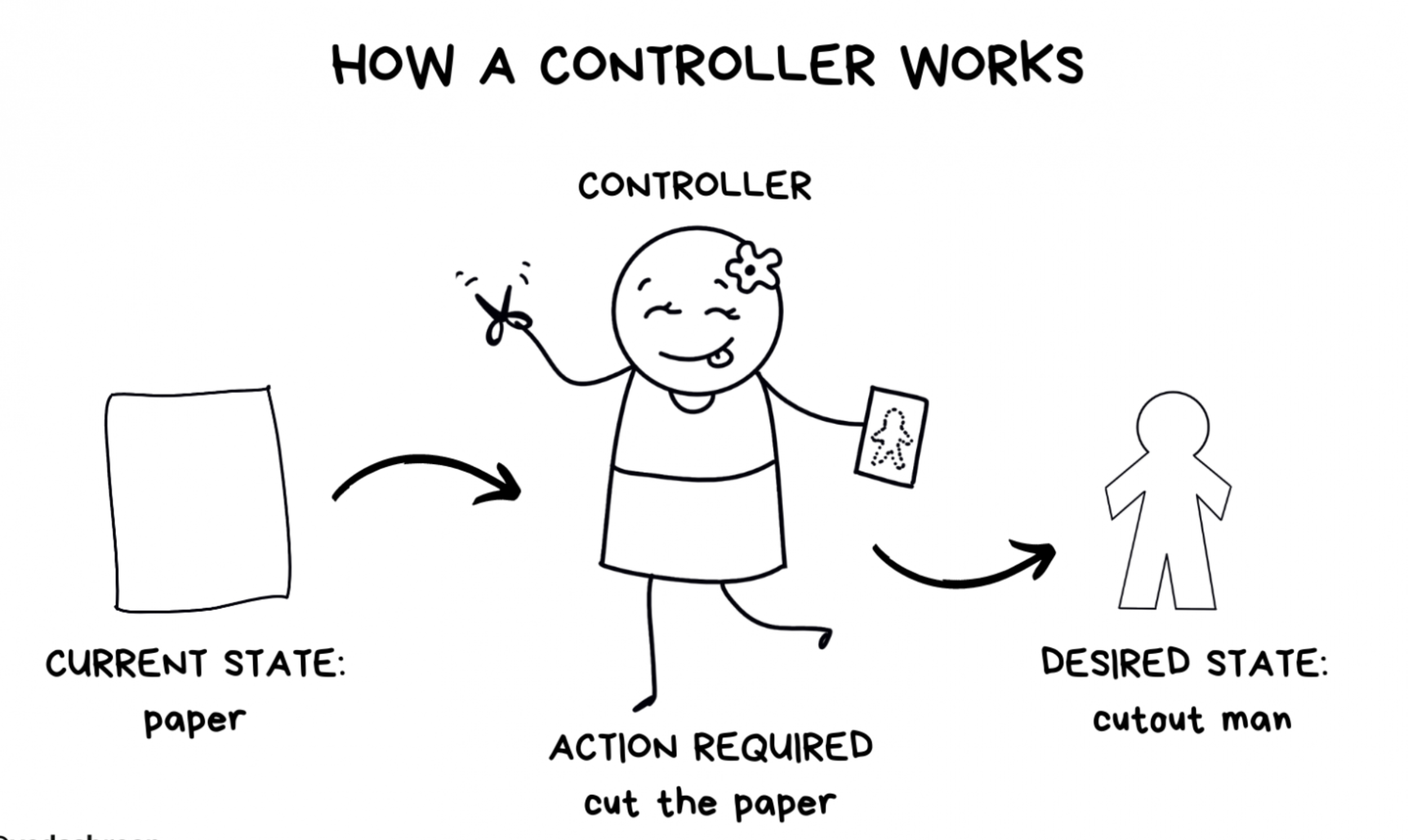
Или другой пример: вам требуется двадцать секунд, чтобы пробежать стометровку. Чтобы уменьшить это время до пятнадцати, придется каждый день тренироваться, чтобы достичь цели. Это и есть переход из текущего состояния в желаемое.
На самом деле контроллер — это просто бесконечный цикл, который постоянно следит за неким ресурсом в кластере (например, за Pod’ом). Если что-то идет не так, он исправляет возникшую проблему.
Теперь вернёмся к нашему менеджеру.
Менеджер контроллеров (Controller Manager) — это набор различных контроллеров. Например, может быть один контроллер, который наблюдает за узлами, другой — за задачами (Jobs), и так далее.
Но такой менеджер — это инструмент «всё в одном». По сути, он отслеживает сразу все ресурсы. За это отвечает ОДИН процесс, но благодаря многозадачности складывается впечатление, что одновременно работают несколько контроллеров. Вот некоторые из самых популярных:
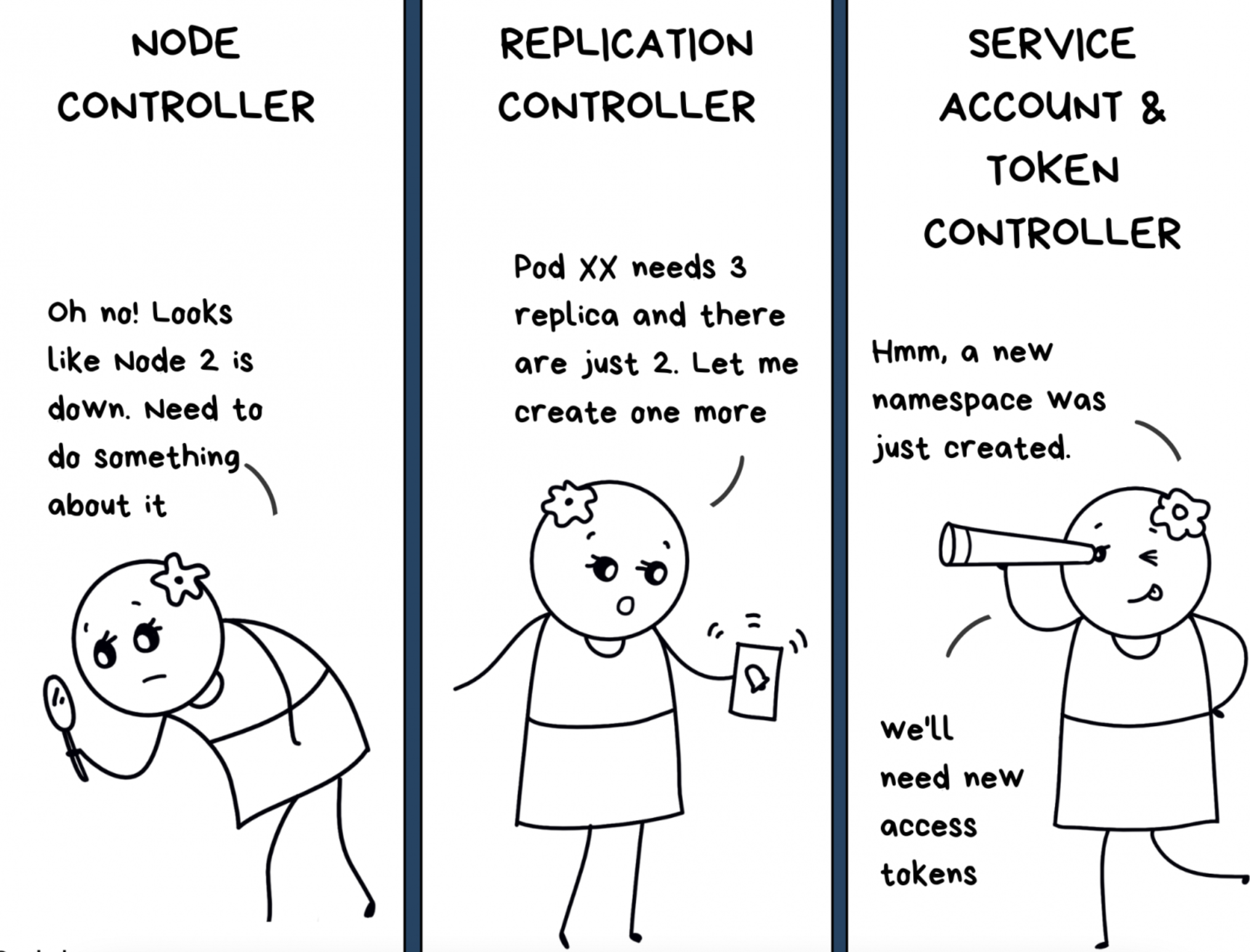
Контроллер репликации: «Pod'у XX нужны три реплики, а там только две. Надо создать ещё одну».
Контроллер учётных записей и токенов: «Хм-м, новое пространство имён. Нужны новые токены доступа».
Etcd
Etcd — это личный журнал Kubernetes. Скажите, зачем люди ведут личные дневники и журналы? Все просто: чтобы сохранить в памяти мимолетные моменты (увы, мозг не способен хранить все события каждого дня нашей жизни).
То же самое и с Kubernetes. Всё, что происходит в кластере, должно быть записано и сохранено. Вообще всё! И тут на сцену выходит etcd. Эта база данных типа ключ-значение выступает резервным хранилищем для Kubernetes.
Переходим к рабочим узлам (worker nodes).
«Команда» рабочих узлов
Мы уже рассмотрели, что такое мастер-узел. Но настоящая работа происходит именно на рабочих узлах. А всё потому, что на каждом узле есть компоненты, отвечающие за его бесперебойное функционирование. Они включают в себя:
- kubelet;
- kube-proxy;
- container runtime.
kubelet
Этот парень, пожалуй, самый важный. kubelet — это агент, который следит за тем, чтобы на узле всё работало должным образом. Подобная работа подразумевает ряд задач.
Первая — взаимодействие с мастер-узлом. Обычно мастер-узел отправляет задачу в форме манифеста или спецификации (Podspec). Манифест определяет, какие работы необходимо провести и какие Pod’ы нужно создать.

Вторая — взаимодействие с исполняемой средой контейнера (container runtime) на узле. Исполняемая среда скачивает нужные образы, после чего вступает в действие kubelet, мониторя Pod’ы, созданные с использованием этих образов.

Третья — проверки (probes) состояния Pod’ов. Кто отвечает за них? Конечно же, kubelet! Потому что следить за здоровьем Pod’а — его обязанность!

kube-proxy
Следующий неотъемлемый элемент — работа с сетью, и kube-proxy готов позаботиться об этом. Он работает как балансировщик нагрузки, распределяя трафик между Pod’ами, а также следит за соблюдением сетевых правил. Можно сказать, что kube-proxy полностью отвечает за коммуникации внутри кластера.

Заключение
В статье рассмотрены основные компоненты кластера Kubernetes. Но процесс познания далек от завершения — ещё необходимо освоить множество важных понятий. Например, мы лишь упомянули работу с сетью, ничего не сказали о рабочих нагрузках и конфигурациях в Kubernetes.