Вариация в тестировании
Алан Ричардсон
Краткое содержание: вариация – полезная тактика для тестирования. Зачастую это случайная вариация внутри класса эквивалентности. Варьировать можно также и при исследовательском тестировании. Подумайте над варьированием порядка, данных, состояний, времени.
Наткнулся на ситуацию, похожую на потенциальный баг обработки хэштегов LinkedIn, и это заставило меня задуматься, как бы тут пригодилась тактика вариации.
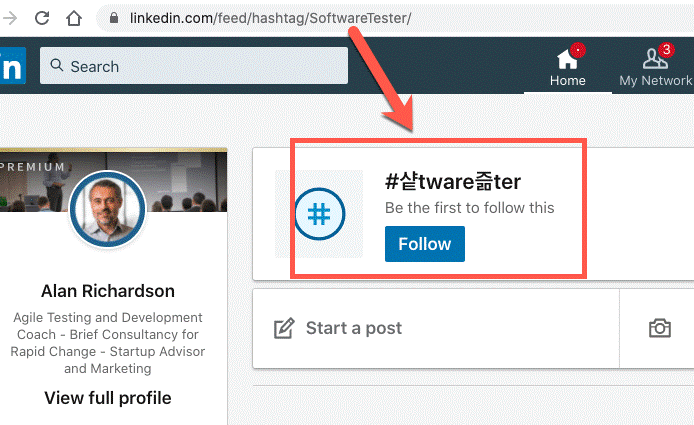
Хэштеги
Я планировал ряд постов в социальных сетях, и исследовал хэштеги LinkedIn.
Я часто использую CamelCase для представления нескольких слов в одном, к примеру:
- SoftwareTesting
- SoftwareTester
Как правило, я пользуюсь им, когда пишу URL или хэштеги.
Копируя и вставляя хэштеги, которые я изучал в LinkedIn, я обнаружил, что хэштеги с CamelCase обрабатывались не так, как я предполагал:
К примеру:
- https://www.linkedin.com/feed/hashtag/SoftwareTester
SoftwareTester превратился в 샽tware즒ter
Этого я не ожидал.
Кодировка
Уверен, что существует какое-то объяснение через кодировку, но я не буду в этом копаться.
И я убежден, что если бы я обсуждал это с командой, то мы бы говорили о:
- мультиязыковой поддержке
- кодировке символов
- заголовках запроса accept-language
- заголовках запроса accept-encoding
Тестирование кодировки сильно зависит от системы и технологии, и может быть связано с очень специфическими нюансами.
Вариация
Вместо этого я задумался о вариации. Вариация очень важна в тестировании. Мы часто говорим о том, что 100% тестирование невозможно ввиду количества возможных применимых комбинаций. Поэтому я хочу включить вариацию в комбинации, которые я уже выбрал для применения.
Пример:
По ссылке выше – Java-код на GitHub для класса ChangeCaseifier. В нем есть метод randomlyChangeCaseOf
Я могу использовать его так:
new ChangeCaseifier().randomlyChangeCaseOf("softwaretester");
А затем использовать полученное значение и вставить его в URL, чтобы увидеть, будут ли различия.
Я пользовался этим, когда писал тесты для своего API:
String getApiPlayerUrl() {
String theUserName = this.forUser;
//мутационное тестирование для проверки регистров
theUserName = changeCase.randomlyChangeCaseOf(theUserName);
return String.format("/api/player/%s", theUserName);
}
Разные прогоны могут вызывать разные URL, от которых я ожидаю эквивалентной реакции системы.
- /api/player/bob
- /api/player/bOb
- /api/player/BOb
- /api/player/BOB
Примечание: API часто ожидают, что URL чувствительны к регистру, и /api/Player/bob может отличаться от /api/player/bob. Если это так, то это разные классы эквивалентности, и моя тактика неприменима.
Я делаю это, так как ожидаю, что регистр URL неважен для его обработки системы. Вместо того, чтобы пытаться протестировать все возможные в URL комбинации букв, я добавил вариацию в те комбинации, которые выбрал для тестирования.
В URL LinkedIn я ожидал, что часть URL с данными будет эквивалентно обрабатываться вне зависимости от регистра.
Классы эквивалентности
В традиционной терминологии тестирования я определяю вариации имени пользователя в URL как класс эквивалентности. Я ожидаю, что любые сочетания нижнего и верхнего регистра определенного имени пользователя будут обрабатываться одинаково.
Классы эквивалентности – полезное место для применения вариации к систематическому запуску автотестов, если они стабильны – это расширяет масштабы применяемых в тестировании данных.
Так как вариация находится в пределах класса эквивалентности, мы ожидаем, что результаты обработки также будут эквивалентными. Если что-то пошло не так, мы наткнулись на граничный случай или предположение, которое неосознанно сделали.
Зачастую у нас есть фиксированный набор значений из класса эквивалентности – мы считаем, что раз это класс эквивалентности, то неважно, какие значения мы выберем, и если взять эти три значения из сотни, все будет хорошо. Рандомизация позволяет нам расширить покрытие и протестировать наши предположения о классе эквивалентности.
И зачастую это можно сделать автоматизированно, потратив всего ничего.
Вариация не в данных
Возможности для варьирования существуют не только при работе с данными.
При заполнении полей я могу варьировать порядок их заполнения:
- Имя, почта, адрес, подтвердить.
- Почта, имя, адрес, подтвердить.
- Адрес, имя, почта, подтвердить.
На экран в разные моменты могут выводиться разные сообщения, но для "подтвердить" порядок по идее должен быть неважен, поэтому его можно рассматривать как эквивалентный – в финале все соответствует условию "все поля заполнены".
Если вы рассматриваете последовательность как переменную, это может принести дивиденды при тестировании, так как формы и приложения часто предполагают определенный порядок заполнения полей пользователем.
Основная идея тут такая: применяйте вариации к порядку, а не только к содержимому.
Это можно рассматривать как эквивалентность состояний, если мы смоделировали форму или взаимодействие как машину состояний.
Что еще?
Множество наших взаимодействий с системой – часть "неявных" классов эквивалентности. Мы часто даже не рассматриваем их как нечто, могущее повлиять на нашу работу.
Пример: время между завершением одной операции и переходом к следующей.
Время зачастую очень мало варьируется при автоматизации. Как правило, мы хотим, чтобы прогон проходил как можно быстрее, и намеренно пытаемся снизить время пауз между действиями.
Мы можем "варьировать" это время и посмотреть, будет ли разница. Зачастую это можно получить "бесплатно", взаимодействуя с приложением при исследовательском тестировании, но мы можем не осознать потенциально важный источник вариации, и не изучить его.
Ищите вариации
Ищите возможности добавить вариации в ваше тестирование.
Помните урок многообразия предпосылок из кибернетики:
- "только многообразие может поглотить многообразие" – Стаффорд Бир.
- "только многообразие может уничтожить многообразие" – Росс Эшби.
Чем больше вариаций мы применяем к системе, тем лучше мы убедимся в ее способности выживать.