VLM Survey
Если вы зашли сюда и вас интересует заголовок статьи, значит вам, вероятно, не нужно объяснять для чего используются и какие задачи решают современные Vision-Language Models.
Решил для вас собрать обзорку по VLM: что почитать, чтобы понять основные идеи. Сразу оговорюсь - я не претендую на полноту, скорее, я хочу провести вас по тем дорожкам, которые для себя я вытаптывал самостоятельно в этом лесу под названием arxiv.
И да, CLIP клево, но мы сейчас не про CLIP, а ближе к нашим дням. Но не упомянуть дедушку нельзя, так как он заложил первый камушек в фундамент дружбы текстов и изображений (вот кажется и упомянули).
Только факты, без воды. Во всех деталях сможете разобраться сами — ссылки в названиях моделей.
Flamingo
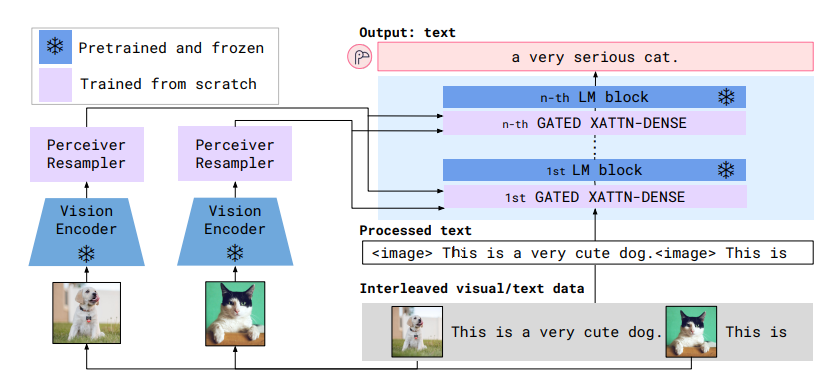
Первая статья, реализовавшая ключевую идею всех современных VLM: использовать предобученные бекбоны.
- Есть Vision Encoder (VE), его сначала учат в CLIP режиме на парах текст-картинка.
- Есть трансформерный адаптер (Perceiver Resampler, PR), который берет аутпут из VE, обучаемые queries, прогоняет через cross-attention и на выход выдает визуальный эмбеддинг.
- Берут LLM и в каждый трансформер блок добавляют слой cross-attention, в котором текстовая информация миксуется с визуальным эмбеддингом (да, претрен ломается от этого).
- Слои self-attention из исходной LLM заморожены, учатся только нововставленные cross-attention.
- Для работы с видео независимо подают в VE кадры, прибавляя на выходе номер кадра. Можно вставить до 32 кадров(фиксированный размер входа в PR).
Основная фишка: первые использовали связку предобученных VE-LLM через cross-attention.
BLIP
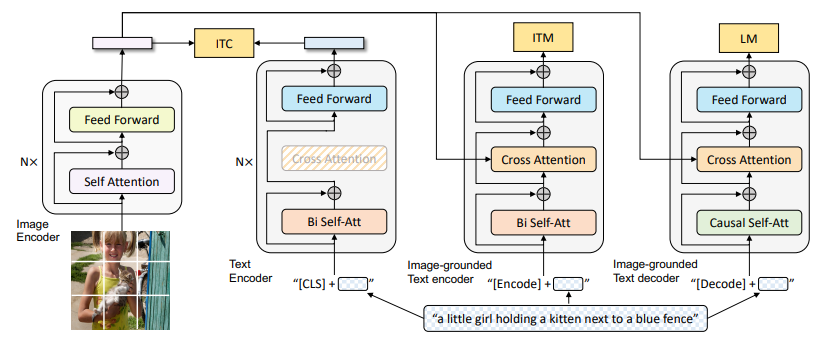
Популярное семейство, которое уже затмили другие семьи, но пошумели в свое время.
Интересным является то, как они учат эту модель. Авторы решают 3 задачи.
- ITC - контрастное обучение, как в CLIP.
- ITM - бинарная классификация, ответ на вопрос по паре картинка-текст "является ли текст описанием картинки".
- LM - генерация текста по картинке.
Как видно по иллюстрации, авторы связывают VIT и BERT (тут именно они) через cross-attention, добавленный в BERT.
Основная фишка: авторы предложили новый метод работы с датасетами. Обучаем таким образом сетку, далее берем пары картинка-текст, через токен [Encode] понимаем подходит ли подпись картинке, если не подходит, то генерим ей новую и на новом "очищенном" датасете переобучаемся.
BLIP2
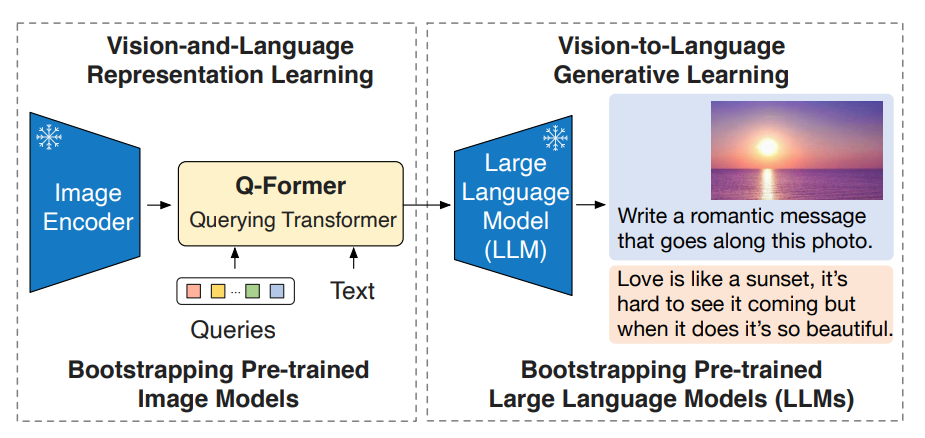
Первая статья в нашем обзоре в духе самых современной архитектуры: VE-Adapter-LLM.
Продолжение предыдущей статьи, им так понравилось учить на эти 3 задачи, что они решили не останавливаться.
Обучение идет в 2 этапа.
- Обучается адаптер (здесь он называется Q-Former). Берем BERT и делаем все то же самое, что мы делали в предыдущей статье, только теперь у нас еще есть обучаемые queries. И именно они, пройдя через Q-Former, будут отвечать за визуальный эмбеддинг.
- Добавляем LLM. Картинка проходит через VE, заходит в Q-Former, там на выходе мы получаем набор эмбеддингов, которые дальше через линейную проекцию становятся размерности токенов и добавляются к тексту, которые поступают в LLM. Учится на этом этапе Q-Former и линейная проекция.
Основная фишка: наконец-то появляется связка VE-Adapter-LLM и Q-Former долгое время будет цитироваться во всех статьях как пример крутого адаптера.
InstructBLIP
Основная фишка: собрали кучу датасетов на разные задачи, чтобы модель (BLIP2) научилась не только хорошо в подписи к картинкам, а стала ближе к general и более адаптирована к чатовому формату работы.
LLaVA
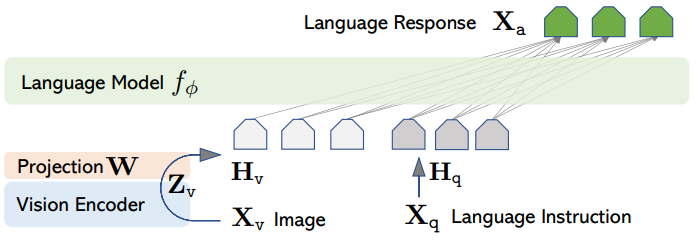
Бессмертная (пока) классика. Простейшая до безумия, но потому и замечательная архитектура. Семейство с честным VE-Adapter-LLM.
- Берем предобученный VE из CLIP (по факту любой энкодер, тут просто такой брали).
- Берем адаптер, авторы пишут, что какой угодно, цитируя Q-Former, в частности, в данном случае они берут light-weight линейную проекцию.
- Берем любую LLM.
- Картинка идет через VE, далее эмбеддинг через адаптер становится размерности токенов, то, что получилось, добавляется к токенам текста и все это обрабатывается в LLM.
Основная фишка: придумали самый простой и действенный метод на сегодняшний день, многое далее - вариации на тему.
LLaVA 1.5
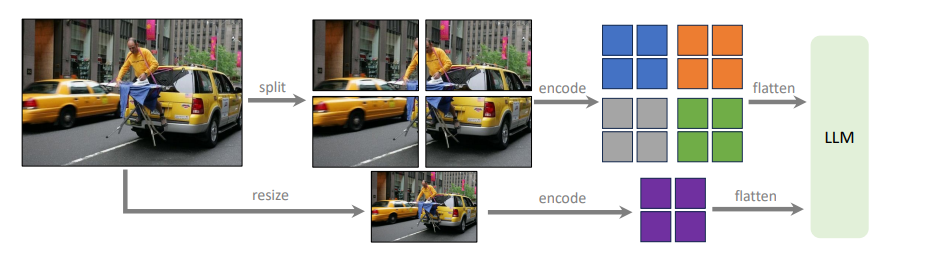
- Изучают отличия VQA датасетов и Instruct, говорят, что с академическими датасетами надо работать иначе.
- Переходят от линейной проекции к двум MLP слоям в адапторе.
- Придумали как насытить данные картинками с большим разрешением - режут их на части и подают друг за другом.
Основная фишка: вроде ничего не придумали, но далее большинство статей в качестве адаптера будут использовать именно два MLP слоя, а такой подход к работе с большим разрешением на данный момент вообще основной.
PALM-E
Статья написана под соусом создания general модели для роботов. Ничего интересного, кроме философии.
Основная фишка: читателю дарится идея того, что любые входные данные можно прогнать через специализированный эмбеддер (картинки, звук, таблицы и тд.), все это соберем вместе и засунем как промпт в LLM.
CogVLM
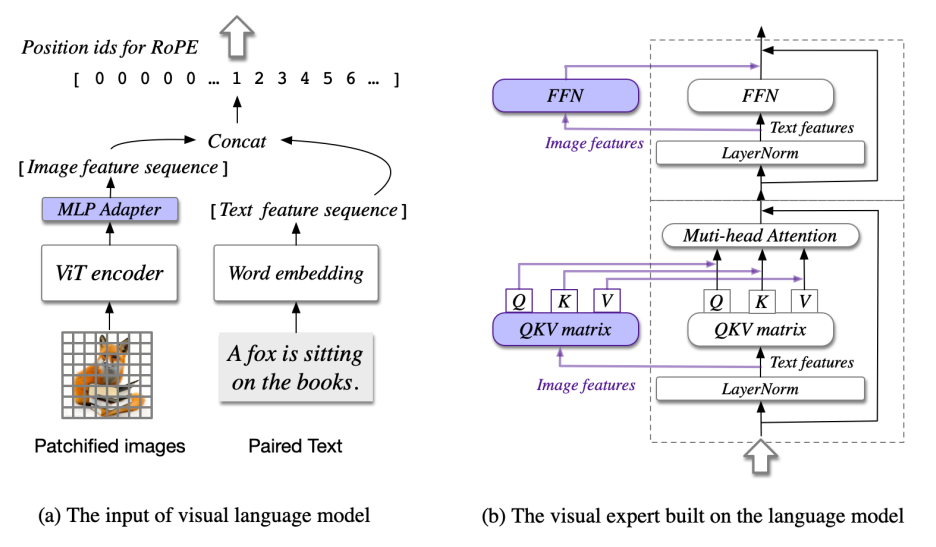
Статья с хорошими мыслями, при том недокрученная, как будто.
- Размышляют, что дообучение на парах текст-картинки очень тупят LLM, поэтому они берут LLM и удваивают ее веса. Делают свои QKV и FFN для картинок. Идея такая: если на вход картинки не будет, то LLM отработает как и раньше. А на этапе обучения будем учить только эти картиночные части, что не сломает претрейн.
- Первые добавляют RoPE (позиционные эмбеддинги). Которые различные для текста и для картинок. Далее это будет повсеместно и умнее чем тут. Здесь просто одна картинка имеет единый индекс, слова разные индексы.
- Впервые добавляют для обучения датасеты на object detection. То есть LLM по входным данным пытается предсказывать bbox, такую задачу в контексте VLM называют grounding. Далее почти все обучающие сеты для VLM будут содержать датасеты с этой задачей.
Основная фишка: появление RoPE, позиционные эмбеддинги для картинок, далее в статьях разовьют эту тему. Датасеты на задачу object detection.
Pixtral
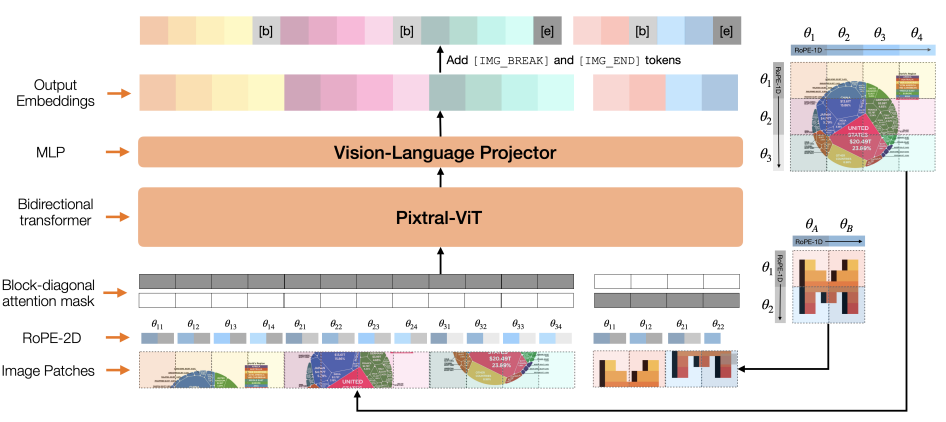
Напоминание Mistral AI о себе.
- При разбиении изображения на патчи добавляют специальный токен [IMAGE BREAK] для обозначения, что строка с патчами перенеслась (понятнее на изображении выше).
- Добавили RoPE-2D - позиционные эмбеддинги, описывающие положение патча изображения относительно всей картинки.
- Маскировка для attention, чтобы одна картинка "не видела" другую.
- Заменили FFN на Gated FFN (но кажется после них никто так не делал).
Основная фишка: RoPE-2D.
BAICHUAN-OMNI
- Работают с текстом, видео, картинками и аудио. Под каждую задачу просто берут свой энкодер (по классике видео и изображения - общий).
- Архитектура базовая Encoder-Adapter-LLM.
- Учат сначала каждый домен отдельно. В несколько этапов. Сначала только адаптер размораживают, потом размораживают энкодер, после чего размораживают вообще все.
- А финальный этап: finetune на кросс-доменных данных.
Основная фишка: хороший техрепорт, особенно классно расписано про работу с данными.
InternVL
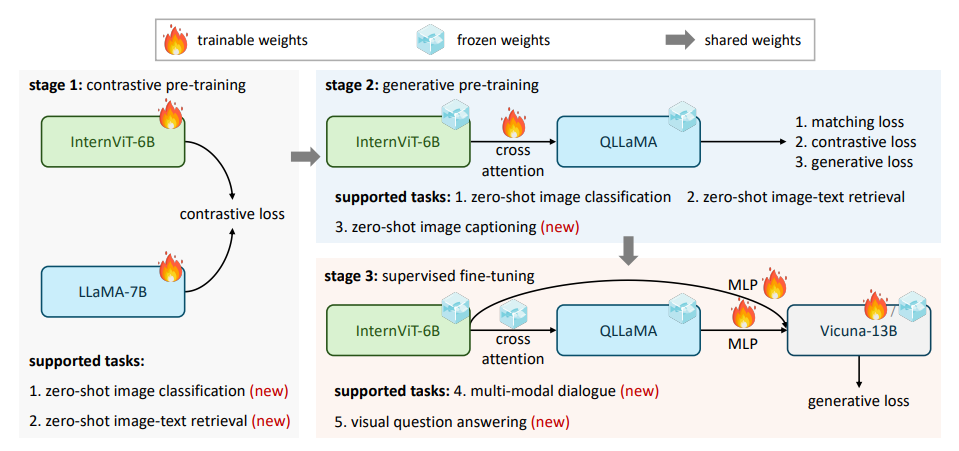
Еще одно очень популярное семейство. Более поздний его представитель сейчас находится в топах бенчмарков.
- Сделали гигантский VIT, до этого это были сотни миллионов параметров, сейчас 6B. Претрейнят его в CLIP-like манере.
- Берут LLaMA и через cross-attention дружат ее с VIT. Это такой гигантский адаптер, который они назвали QLLaMA. Учат эту пару генерировать текст по картинке.
- Берут уже финальную LLM и к ней на вход подают выходы как VE, так и после адаптера (QLLaMA), которые прогоняются через MLP слои.
Основная фишка: сделали гигантский VE, в остальном ничего выдающегося.
InternVL 1.5
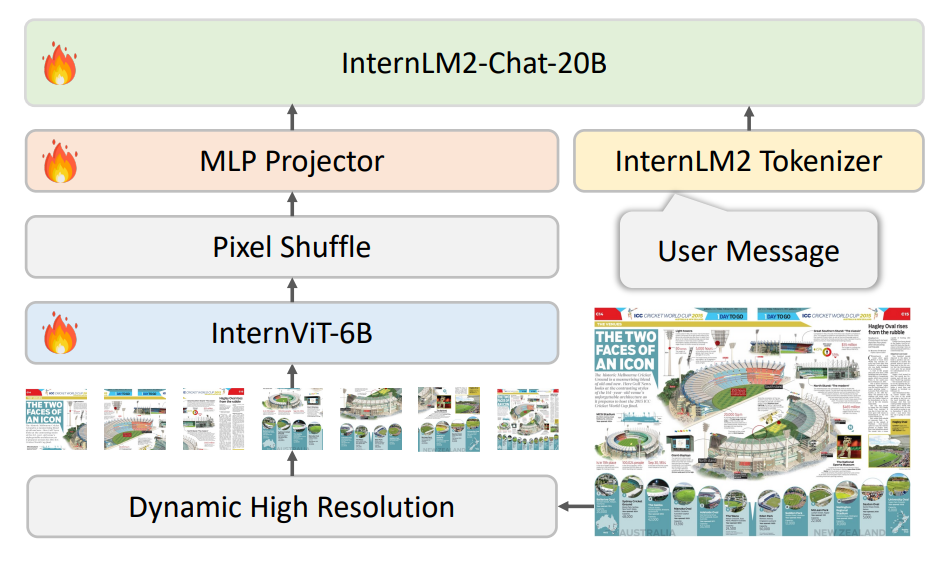
- Забили на гигантский адаптер и перешли к стандартным двум MLP.
- Бьют картинку на патчи для работы с высоким разрешением. При этом каждое приходящее изображение относится к одному из предефайненых соотношений сторон, что помогает грамотнее бить на патчи. Грамотнее равно добавлять наименьший паддинг.
- Есть слой Pixel Shuffle, который уменьшает количество токенов, относящихся к визуальной части. Просто для экономии ресурсов.
Основная фишка: еще чуть закопались в высокое разрешение, но в целом никаких особых новшеств.
InternVL 2.5
Вообще ничего такого, плюс минус как прошлая версия, чуть поменяли модельки, немного изменили датасеты, сильнее постарались и получили на текущий момент одну из лучших моделей по бенчмаркам.
NVLM
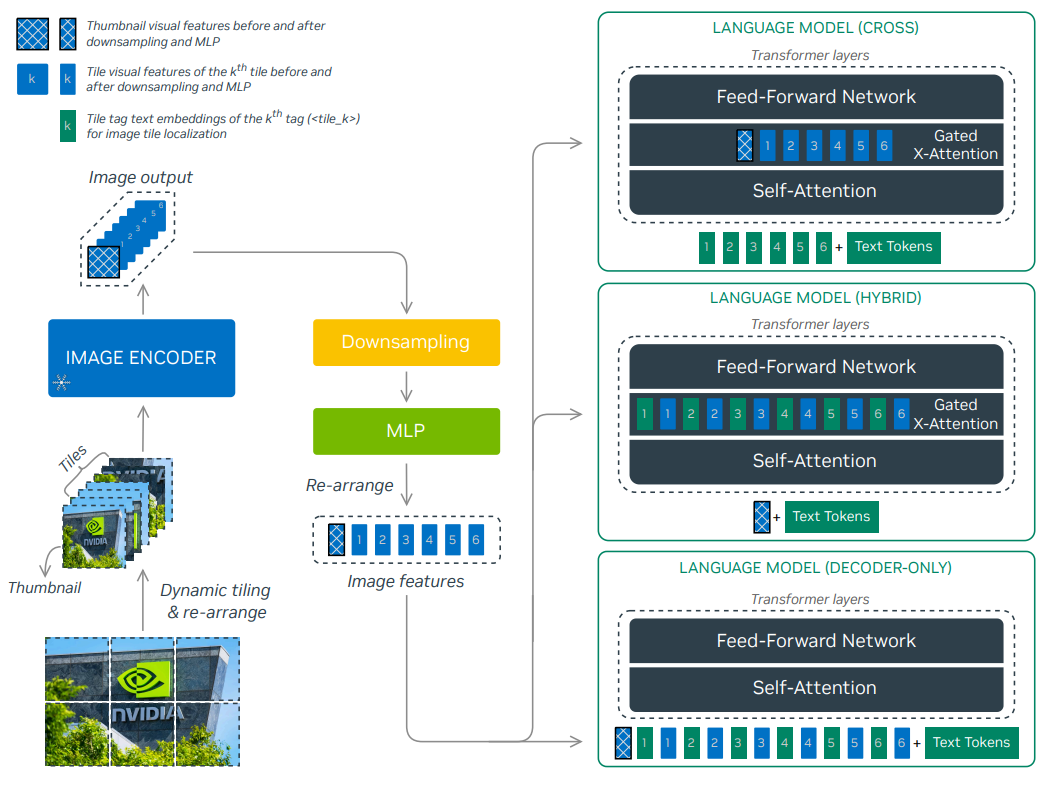
Смешная статья, которая делает TL;DR всех текущий статей по VLM.
Идея авторов следующая: существует всего два подхода как подружить картинки и текст.
- Через cross-attention.
- Через адаптер.
Что делают предприимчивые разработчики NVIDIA. Они обучают одну такую модель, одну такую и представляют миру гибридный вариант. Когда часть информации идет в cross-attention, а часть еще проходит через MLP и подается в качестве промпта.
Основная фишка: авторы дали подтверждение идеи, что в сфере VLM еще поле непаханое, и стоит пробовать что-то новое.
Qwen-VL
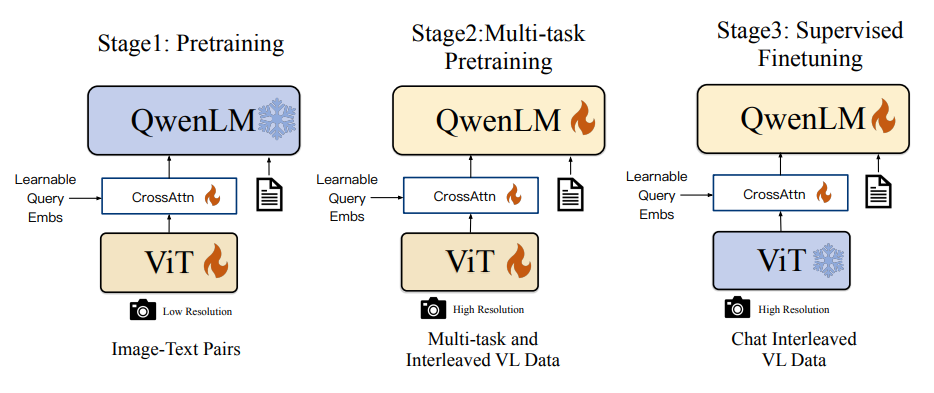
Архитектура чем-то похожа на BLIP2. Говорим, что за визуальную часть будут отвечать предобученные queries, которые через cross-attention обмениваются информацией в адаптере с выходом VE и подаются в LLM вместе с текстом.
Основная фишка: первый представитель семейства, которое сейчас главенствует в бенчмарках.
Qwen2-VL
- Возможность подавать изображение любого разрешения, как и у прочих за счет разбиения на патчи.
- Используют 2D-RoPE. Но также могут работать с видео, а для них уже используют M-RoPE. Фактически каждый патч изображения имеет свои координаты в трех проекциях, где третья проекция это время.
Основная фишка: навели красоту, придумали M-RoPE для видео.
Qwen2.5-VL
- Докрутили M-RoPE, теперь эмбеддинги завязаны на fps. В предыдущей версии были просто индексы кадров, тут связано с абсолютным временем.
- В VIT заменяют self-attention на window attention, для оптимизации (буквально как переход от VIT к Swin в свое время). От квадратной сложности к линейной.
- Увеличили датасет относительно прошлой версии в 3.5 раза. Куча разнообразных данных. Говорят круто прокачались в grounding-е.
Основная фишка: огромная толпа данных, подтюнили прошлые наработки, вышли в топы.
Сейчас уже появилась модель Qwen-QwQ, которая, кажется, побила своих младших братьев, но статьи пока не вышло, чтобы узнать детали.
DeepSeek-VL
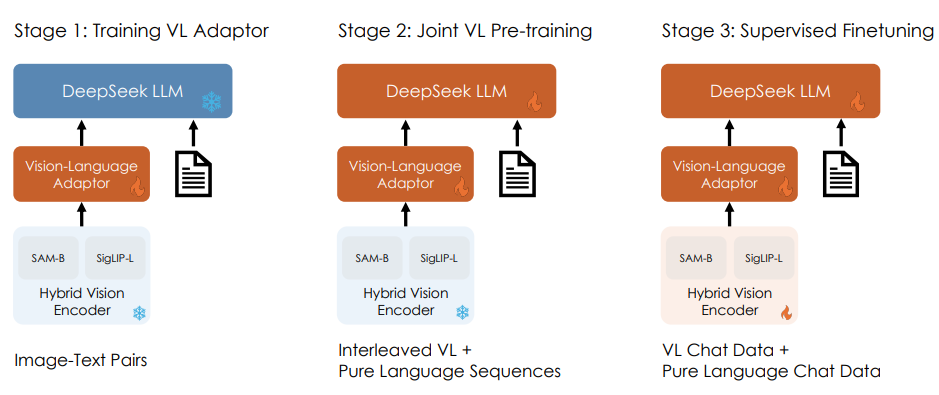
А вот и представители недавно нашумевшего семейства.
- Для обработки изображений высокого разрешения делают VE из двух энкодеров. SAM-B и SigLIP-L. SAM обрабатывает изображения с входным разрешением 1024, SigLIP 384 (картинка одна и та же, просто разный ресайз используется), по итогу фичи обеих моделей конкатенируются в конце, получая общий визуальный эмбеддинг. Аля таким образом они хорошо работают с высоко и низко уровневыми фичами.
- В качестве адаптера два MLP слоя.
- Используют RoPE.
- Как обычно куча разнообразных датасетов под все виды задач.
Основная фишка: используют свой подход работы с высоким разрешением, изучают как правильно обучать модель, контролируя соотношение текстовых и визуальных данных на разных этапах, чтобы ничего не деградировало.
DeepSeek-VL2
- Используют MoE-based LLM.
- Сильно расширяют обучающий набор данных относительно предыдущей версии.
- Отказались от гибридного VE, перешли как и все к разбиению изображения на патчи.
- Как и в InternVL классифицируют изображению по соотношению сторон, чтобы добавлять минимум паддинга к патчам.
- Используют Pixel Shuffle для понижения размерности визуальных токенов.
- Добавляют "перенос строки" как в Pixtral.
Основная фишка: пересмотрели способ работы с высоким разрешением, использовали MoE-based LLM, что дало хороший прирост.
SmolVLM
Самая маленькая VLM на сегодняшний день. Существует в 3 вариациях: 256М, 512М, 2B. Удобная модель, чтобы поиграться на небольших мощностях, при этом 512М уже вполне себе умная.
Основная фишка: заводится на чайнике, калькуляторе и стилусе.
Заключение
Аспекты SOTA VLM, или как собрать ракету в домашних условиях:
- Архитектура VE-Adapter-LLM.
- VE предобучить в CLIP-like режиме, видимо так визуальные эмбеддинги уже и без адаптера становятся более похожи на текстовые.
- В качестве Adapter берем несколько MLP слоев.
- Берем SOTA LLM, ее вклад сейчас все еще ключевой.
- Добавляем RoPE-2D, или любые другие позиционные эмбеддинги, которые отделят картинки и текст, а также дадут структуру изображениям.
- Дотошно собираем датасеты на абсолютно разные задачи. VQA, grounding, в общем все то, чему сейчас посвящена каждая работа по VLM, это почти всегда основная часть статьи.
- Мало ресурсов - учим только Adapter (вроде это называется Model Grafting), дальше, чем больше ресурсов, тем больше всего можно пробовать размораживать.
- Добавляем датасеты с большим разрешением, с ними работаем за счет разбиения исходного изображения на патчи.
- Охапка дров и SOTA VLM готова.
Эта статья написана для того, чтобы дать легкий старт в теме VLM, рассказать основные идеи и показать путь зарождения этих идей у авторов по всему миру. Надеюсь, она была вам полезна!
Пересылайте эту статью своим друзьям ML-щикам, порадуйте их!
Ну и не забывайте подписываться на Лечим эйай.
Такие материалы можно найти только там!