VGG
DeepSchoolАрхитектура
VGG-16 и 19 — детище Visual Geometry Group — академической группы Оксфордского университета. При создании своей архитектуры, авторы учли опыт Нью-Йоркских коллег и стали использовать меньший размер свёртки (3х3) и меньший шаг (stride=1) на первом свёрточном слое. Для сравнения AlexNet использовала свёртку 11х11 и stride равный 4 в начале сети.
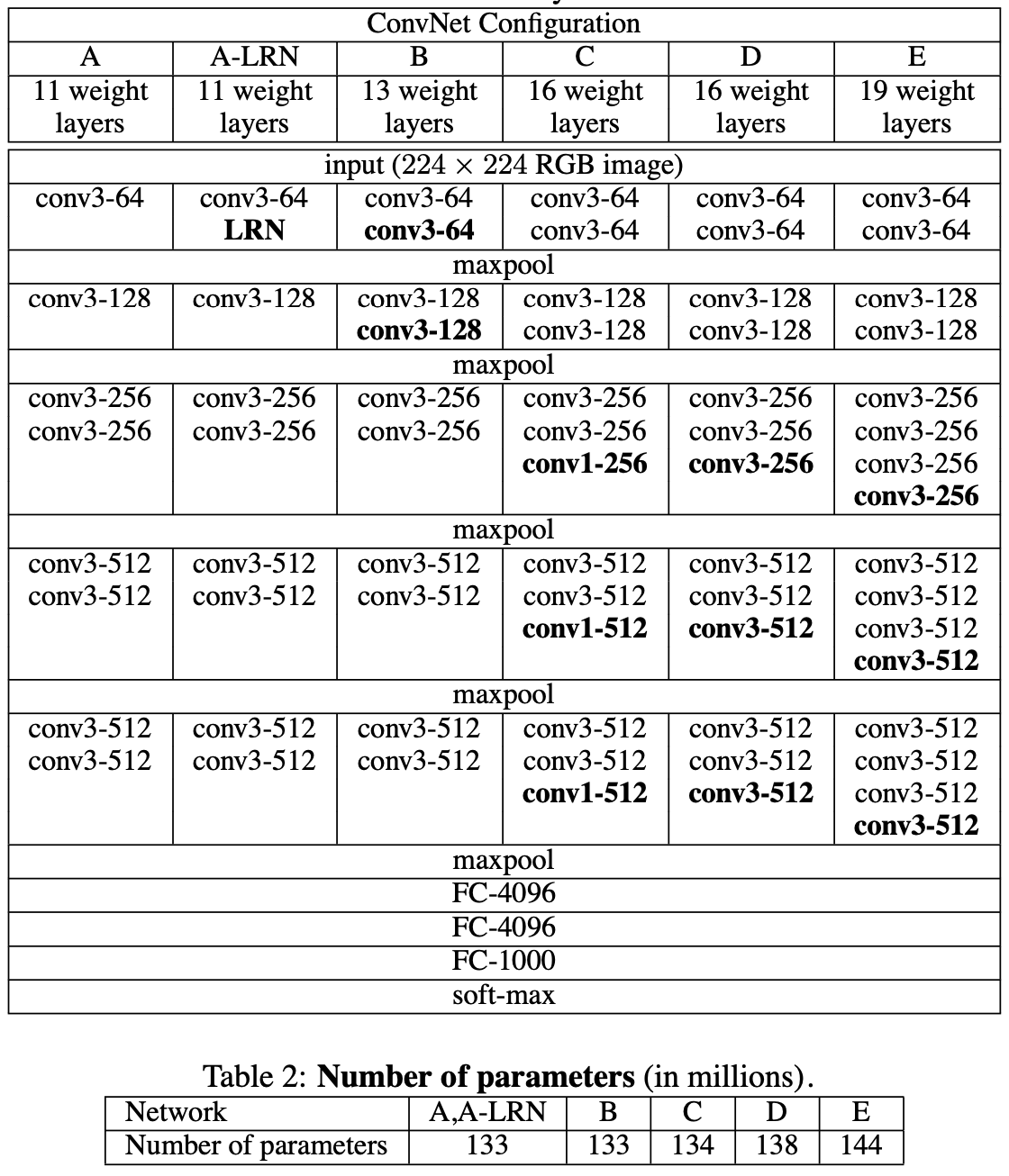
В своей статье авторы VGG изучали, как глубина сети влияет на точность классификации ImageNet. При этом использовались свертки двух размеров: 3х3 (преимущественно) или 1х1 . В статье было исследовано шесть различных вариантов архитектур и выбраны две наилучшие: VGG-16 и VGG-19. Первая состоит из 16 слоёв, а вторая (барабанная дробь….) из 19. Архитектура представлена на рисунке ниже.
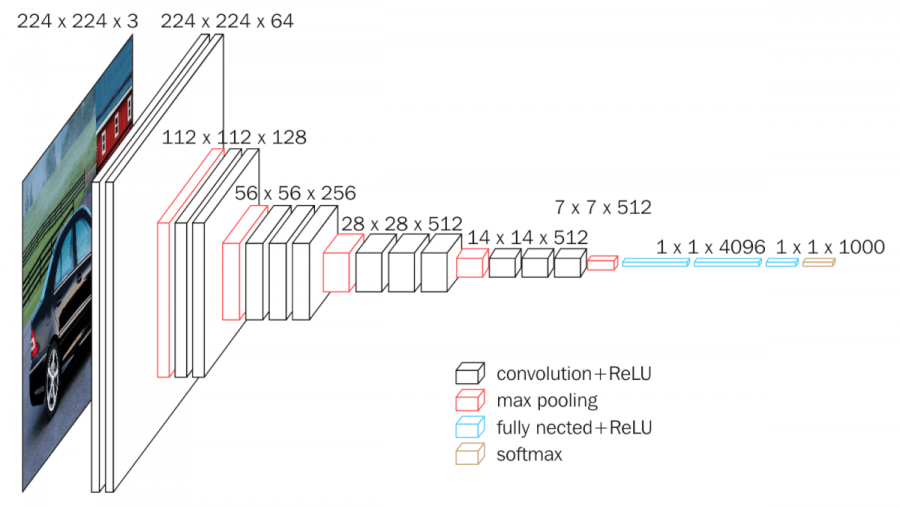
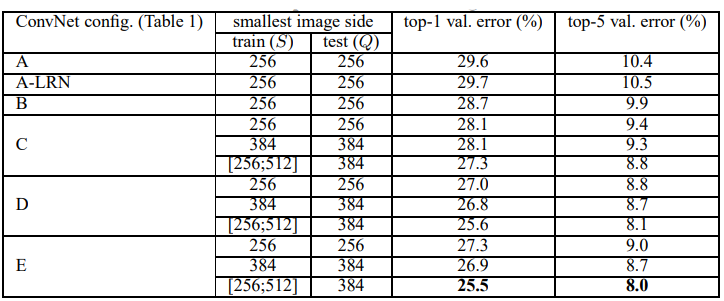
Авторы также показали, что докинув в архитектуру сверток 1х1, они лишь немного увеличили размер сети, но повысили ее точность. На рисунке 2 архитектуры B и C отличаются только дополнительной свёрткой 1х1. Это утяжелило сеть всего на 0.7%, но уменьшило ошибку на 2% (рис. 3). Как утверждают авторы, сеть стала перформить лучше из-за дополнительной нелинейности, что позволяет запомнить более сложные паттерны в данных.
Именно во времена VGG стало понятно, что вместо одной крупной свертки лучше использовать несколько сверток меньшего размера. Ведь рецептивное поле будет таким же, а вычислительная сложность ниже, плюс еще и “нелинейности” в сети станет больше.
Пример: одна свертка 5х5 при stride=1, потребует (W*H*C_in)*(5*5)*C_out операций, а две свертки 3х3 потребуют (W*H*C_in)*(3*3)*2*C_out. Получается свертка 5х5 потребует в 1.4 раза больше вычислений (не считаем тут нелинейность), а при этом рецептивное поле в обоих случаях будет одинаковое.
Выводы
В общем и все: работа показала, что глубина для сети играет очень важную роль :) Но мы с вами в 2022 году уже хорошо знаем, что бесконечно увеличивать глубину не получится из-за неизбежного затухания градиента. Эту проблему удалось решить авторам архитектуры ResNet, но об этом мы подробнее расскажем уже в следующих постах :)
Не смотря на свой возраст (статье уже более 7 лет), VGG используется и по сей день. Она избыточна, в ней много параметров, и это позволяет извлекать много признаков (возможно, не самых лучших, но зато много), что как раз используется в Content Loss при обучении GAN-ов. Однако для других задач лучше использовать более современные архитектуры, ибо у VGG есть ряд недостатков:
- медленная скорость обучения;
- тяжелая избыточная архитектура, которая используется недостаточно эффективно (VGG-16 весит более 533 МБ, при этом ResNet18, у которой 18 слоёв, весит 45 МБ);
- не получится сделать сеть еще глубже, иначе начнет затухать градиент.
Ссылки на дополнительные источники
Видео (рус). Понятное видео с объяснением архитектуры, основных идей и реализацией на keras.