ВЕБ-ХАКИНГ. Часть 2
INHIDE
6. Reverse-IP. На одном IP и на одном сервере может находится множество сайтов:

Не существует 100% способа узнать все сайты на одном IP. Онлайн сервисы позволяют находить сайты на одном IP только благодаря большим базам (парсят денно и нощно). Поэтому необходимо использовать максимальное кол-во сервисов reverse-ip:
- http://www.yougetsignal.com/tools/we...on-web-server/
- http://reverseip.domaintools.com/
- http://ipaddress.com/reverse_ip/
- http://www.iwebtool.com/reverse_ip
- http://www.ipfingerprints.com/reverseip.php
- http://viewdns.info/reverseip/
- http://www.majesticseo.com/reports/n...urhood-checker
- http://www.myipneighbors.com/
- http://logontube.com/reverseip/
- http://www.tcpiputils.com/domain-neighbors
- http://ip-www.net/
- http://www.ip-address.org/reverse-lookup/reverse-ip.php
- http://bgp.he.net/ip/
- http://bing.com/?q=ip:xxx.xxx.xxx.xxx
Сайты меняют хостинг, домены дропаются, поэтому полученные данные надо обязательно перепроверять. Если IP-адреса сайтов совпадают, можно утверждать, что они находятся на одном сервере. В некоторых случаях сайты могут находится на одном сервере, даже если у них различается последний октет IP адреса - 121.1.1.1, 121.1.1.2, 121.1.1.3.
7. SEO-параметры.
Узнаем основные seo-параметры сайта:
1. Тиц. PR. Яндекс-каталог. DMOZ.
2. Беклинки
3. Внешние ссылки.
Получив все эти данные мы можем сделать несколько выводов.
Во-первых, мы узнаем, на какую примерную сумму можно рассчитывать, если продавать доступ к данному сайту(50 шекелей? 30? 10?).
Во-вторых, мы можем проверить совпадают ли IP беклинков и внешних ссылок с IP цели. Если есть совпадения, то мы можем предположить, что эти сайты находятся не только на одном сервере, но и на одном аккаунте хостинга. Это означает, что достаточно взломать всего 1 сайт и мы автоматом получим доступ к остальным (которые совпали).
Объясню прошлый абзац. Представьте, что есть фрилансер Феофан Крохоборов. Феофан делает сайты. И берет за них деньги. А чтобы заработать больше денег, Феофан размещает сайты своих клиентов на одном аккаунте хостинга (в итоге Феофану платят 10 человек по 100р в месяц за хостинг, а сам Феофан платит за хостинг 50р в месяц, выгода!) Только Феофан не осознает, что взломав даже 1 сайт из 10, подлый хацкер получит доступ и ко всем остальным 9. А вычислят Феофана легко - он везде ставит линк на основной сайт ("Сделано в студии Феофана КРохоборова"), а если он прочитал пару статей по SEO, то еще и перелинкует все ресурсы.
Если на сайте target.com используется счетчик liveinternet, то получить статистику можно по следующим ссылкам:
Если счетчиков нет, то можно попробовать определить кол-во трафика через AlexaRank. Это актуально для бурж сайтов.
8. Разработчики. Для успешного взлома, будет нелишним узнать кто создавал сайт. Методы относительно простые:
8.1. Смотрим футер сайта, ищем надпись, кровоточащую эгоизмом и завышенной самооценкой, что-то вроде "Элитарная студея разрабатывания сайтингов". Переходим на сайт, если линк активный, либо гуглим название.
8.2. Проверяем собранные беклинки. Есть ненулевой шанс, что изучаемый нами сайт находится в портфолио у какой-нибудь студии/фрилансера.
8.3. Проверяем мета-теги, комментарии. Ищем что-то в духе:
<meta name="author" content="Petroff Studio">
или:
<!-- super-site by artemka-diz.ru -->
8.4. Если прошлые способы не помогли, пробуем определить CMS сайта. Если нам повезло и на сайте явно используется что-то редкое и самописное, мы гуглим название CMS и пытаемся выйти на разработчика. Если сайт сделан на распространенном движке, то переходим к последнему способу.
8.5. Спросить владельца сайта. Ссым в уши, дескать, дизайн вашего сайта настолько великолепен, что мы не можем не спросить вас, кто же создал такое дивное чудо, достойное вершин поисковой выдачи и сотен тысяч WMZ. Нередки ситуации, когда создатель сайта == владелец сайта.
Когда нам становится известно, кто являлся разработчиком сайта, у нас появляется несколько лазеек:
- Мы можем сделать заказ на разработку сайта (разумеется если CMS самописная) и получить исходники. Изучить их вдоль и поперек и найти все возможные дыры. Велик шанс, что в сайт вшит дефолтный пароль или бекдор.
- В процессе общения, разработчику легко пихнуть троян и получить доступ к сохраненным логинам/паролям и исходникам.
- Если общение с разработчиком неуместно или не дало результатов, мы будем ломать все сайты в портфолио (если это реально, разумеется). В случае успеха - скачиваем исходники и ищем уязвимости. И потом пробуем пароли со взломанного сайта к другим ресурсам в портфолио. Крайне эффективная методика.
- Если совсем ничего не получилось, информацию о разработчике можно использовать для атаки с использованием социальной инженерии. Рассылаем по клиентам "свежее обновление", "патч", "заплатку", просим предоставить логин/пасс. Я уверен вы придумаете что-нибудь поинтересней.
9. Контакты. Достаточно мельком взглянуть на сайт, чтобы найти контакты:
Нас интересует все. Телефоны, e-mail, skype, icq, jabber, facebook, linkedin, формы обратной связи, фактический адрес (снимок Google Earth со спутника добавит нотку экзотики). Каждый из контактов - возможная зацепка, возможный способ взлома.
10. Сотрудники. Если на сайте есть список сотрудников, то все становится еще веселее - атака с применением социальной инженерии будет особенно эффективной. Собирайте всю информацию по сотрудникам - адреса, контакты, дни рождения, аккаунты соцсетей, фотографии с работы (можно найти очень интересные данные). Если работаете по буржу, можете воспользоваться сервисами поиска:
- pipl.com
- people-search сервисы
- people.yahoo.com
- address.com
- www.123people.com
- zabasearch.com
- wink.com
- publicpeoplefinder.com
- peoplefinders.com
- peoplelookup.com
Обязательно ознакомьтесь с утилитой maltego - великолепная штука для сбора информации (хорошее описание есть тут - http://habrahabr.ru/post/73306/).
Фактически, чем больше в конторе сотрудников, тем больше шансов, что найдется долбоеб, готовый запустить crober_priv8_bootkit.exe, предварительно отключив антивирус и файрволл (и взлом сайта будет лишь приятным дополнением).
Хорошая иллюстрация вышесказанного:

11. Вакансии. Если фирма крупная, имеет смысл просматривать сайты с вакансиями.
- Рунет:http://www.job.ru/
- http://www.avito.ru/
- http://zarplata.ru/
- http://www.superjob.ru/
- http://rabota.ru/
- и т.д.
Бурж:
Будет повод вступить в переписку, отправить троян или в конце концов устроиться на нормальную работу ("...и вынести все под ноль" (с) Не грози южному централу). Если вам повезло и вакансия IT-шного характера, можно выудить массу информации о настройках сервера, используемых фреймворках, получить тестовый доступ и т.д.
12 Конкурентная разведка. Она же бизнес-разведка или деловая разведка.
Если очень вкратце, то конкурентная разведка - это сбор всей доступной о цели информации из открытых источников (то бишь этично и благородно).
Если мы ломаем топовую фирму, работающую в высококонкурентной сфере, или крупную организацию (коммерческую, некоммерческую, государственную) то даже крупицы информации могут сыграть ключевую роль. Вместо тысячи слов - http://www.slideshare.net/SkillFactory/10-27807036
Разумеется, если цель - сайт вашей школы, то смело пропускайте этот пункт. Да и вообще, как вы до сюда дочитали? Тут нет ни читов, ни ддос-ботов, ни локеров...
13. Смотрим веб-архив. Заходим на интернет-архив(http://archive.org
/web/):

И смотрим, что было раньше с сайтом:

Мы можем найти контакты, которые уже убрали с сайта, можем найти информацию об ошибках, узнать насколько давно меняли сайт. Если сайт не менялся очень давно, есть шанс, что система давно не патчилась, и у нас больше шансов найти уязвимости.
Вообще очень полезный инструмент во всех отношениях.
14. Поисковые системы. Если вам нужно изучить контент сайта, но не хочется следить в логах, можно изучить сохраненной копией страницы (к примеру в Google, но это фича доступна и для других поисковиков).

Мы также можем найти ошибки и многое-многое другое. Если вам не знаком термин Google-hacking, то вот вам блиц курс:
1. Читаем ман https://support.google.com/websearch/
2. Используя полученные знания ищем инфу по всем операторам поиска Google.
3. Бонус. Гуглим про гугль-хакинг.
Используем Google-хакинг супротив нашей цели:
- Поиск папок открытых на просмотр:
- site:target.com intitle:index.of
- Поиск файлов с настройками:
- site:target.com ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini
- Поиск файлов с бекапами БД:
- site:target.com ext:sql | ext:dbf | ext:mdb
- Поиск файлов с логами:
- site:target.com ext:log
- Поиск бекапов:
- site:target.com ext:bkf | ext:bkp | ext:bak | ext:old | ext:backup
- Поиск админки:
- site:target.com inurl:login
- Поиск ошибок, говорящих о SQL-инъекциях:
- site:target.com intext:"sql syntax near" | intext:"syntax error has occurred" | intext:"incorrect syntax near" | intext:"unexpected end of SQL command" | intext:"Warning: mysql_connect()" | intext:"Warning: mysql_query()" | intext:"Warning: pg_connect()"
- Поиск документов:
- site:target.com ext:doc | ext:docx | ext:odt | ext:pdf | ext:rtf | ext:sxw | ext:psw | ext:ppt | ext:pptx | ext:pps | ext:csv
- Поиск файла с phpinfo():
- site:target.com ext:php intitle:phpinfo "published by the PHP Group"
Еще больше дорков (дорк - это хитрый запрос для получения информации) тут - http://www.exploit-db.com/google-dorks/. Вообще в сссрнете по разному трактуют слово "dork", учитывая что простой перевод с английского дает черти-что ("мужлан", "придурок"), а судя из контекста, очень сложно дать единственно верную, точную формулировку.
Также ищем упоминания о сайте/фирме/проекте в сети. Не забываем гуглить найденные ранее контакты - возможно получится узнать что-то новое о ресурсе, подготовить почву для атаки методами соц.инженерии.
И не зацикливайтесь только на гугле, используйте все поисковики:
- Yandex
- Bing
- Yahoo
- Shodan (!!!)
- DuckDuckGo
Shodan - весьма непривычный поисковик. Всю мощь его можно оценить, вбив в поиск "default password" или "nuclear". Ищет не по контенту сайтов, а по http-заголовкам, IP, баннерам сервисов на разных портах и т.д. К сожалению без регистрации можно делать не более 10 запросов (прокси никто не отменял) и выдача серьезно ограничена. С регистрацией - 50.

15. Проверка на virustotal/blacklist's. Вполне может быть, что раньше сайт/сервер ломали. И можно найти что-то интересное. Заходим на вирустотал:

Выбираем "Найти". И вуаля:

Все уже поломано до нас. Если кто-то смог, то и мы сможем) А может и шелл до сих пор не удалили и пароль стоит по умолчанию...
Разумеется не стоит ограничиваться исключительно virustotal'ом.
На этом все. Мы рассмотрели основные способы пассивного сбора информации (т.е. с минимальным взаимодействием с целью). Если исключить отправку писем с вопросами о хостинге или разработчиках, то мы можем собрать уйму информации, даже ни разу не заходя на исследуемый сайт и никак не контактируя с его владельцами! Вот до чего техника дошла!!!
Сбор информации
Информации на прошлом этапе было собрано достаточно. Теперь мы будем активно работать с сайтом. Много следить в логах, использовать кул-хацкерские программы, сканерочки, парсерки и прочие веселые программки.
Общая схема того, что мы будем делать на данном этапе такая:

Ничего страшного, все довольно просто. Мы пойдем по списку:
- Определение CMS
- Определение тем, плагинов, модулей, компонентов
- Поиск уязвимостей в CMS и плагинах
- Сканирование директорий
- Краулер
- Обход mod_rewrite (и аналогов этого модуля)
- Сбор параметров (Get, Post, Cookie, Headers)
- Поиск и эксплуатацию уязвимостей оставим для следущих уроков, а пока мы занимаемся исключительно сбором информации.
Активный сбор информации.
1. Определение CMS. Пробуем определить используемую CMS (или CMSки, ведь никто не запрещает использовать несколько CMS на одном домене). Если используется распространенный движок, то определить это можно с вероятностью в 99%.
Если вам в лом самим определять CMS, можете воспользоваться сервисами:
Можно использовать плагин для браузера - wappalyzer.
Очень удобно, сразу видно движок, язык, js-фреймворки и т.д.:

Определяет больше двух сотен движков. Плагин не всегда работает точно. Например, попробуйте зайти с включенным плагином wappalayzer на эту страничку - /misc/crazywappalayzer.php Если вас интересует, как этот плагин определяет движки, посмотрите исходник:
https://github.com/ElbertF/Wappalyze...let/js/apps.js
Вы поймете, что анализируются:
- http-заголовки (в том числе cookie)
- meta-теги
- подключаемые скрипты (<script src='blabla'>)
- пути к файлам (картинкам, таблицам стилей и т.д.)
- комментарии в html-коде
- прочее (по регуляркам) в html-коде ("Powered by ...", "MegaSuperCMS")
- URL (/index.php?showtopic=666 - явно сатанинский форум, /?p=1488 - нс-бложик)
Для точного определения CMS нужно также проверять:
robots.txt - в данном текстовике указаны папки и файлы которые нужно/не нужно индексировать. Файл либо лежит в корне сайта, либо его вообще нет. Выглядит примерно так:

Наметанный глаз мигом определит WordPress. Ненаметанный метнется по адресу /wp-login.php и опять таки определит WordPress.
Админ-панель - Определить адрес админки можно внимательно изучив файл robots.txt или проверив все распространенные пути к админкам (руками или софтом - об этом чуть далее). К примеру, вход в админку Joomla!:

- Joomla. http://target.com/administrator
- WordPress. http://target.com/wp-admin/
- Drupal. http://target.com/user
- DLE. http://target.com/admin.php
- Любая другая CMS - http://google.com/?q=найти+админку+cmsname
Файлы и Папки. CMS можно определить по наличию/отсутствию некоторых файлов и папок. Например, в большинстве CMS есть файлы с названиями типа Changelog.htm, readme.txt, config.example и подобными. Скачиваем распространенные движки, изучаем структуру файлов и папок, пробуем найти интересные файлы/папки на изучаемом сайте.
Таким способом можно очень точно определить используемый движок и его версию.
Просто потренируйтесь - устанавливайте разные движки, ставьте разные шаблоны, плагины. После небольшой практики, вы сможете определять движок взглянув одним (прищуренным) глазом на главную страницу.
В результате, после выполнения всех вышеописанных проверок, возможны 3 варианта:
- CMS определена, исходники можно изучить.
- CMS определена, но нет возможности изучить исходники.
- CMS не определена.
2. Определение тем/плагинов/модулей/компонентов. Если мы работаем с одной из распространненых CMS, то мы можем проверить еще и модули/плаигны. Для этого можно быстренько набыдлокодить свой убер-скрипт либо воспользоваться существующим софтом (к примеру для скана плагинов WP):
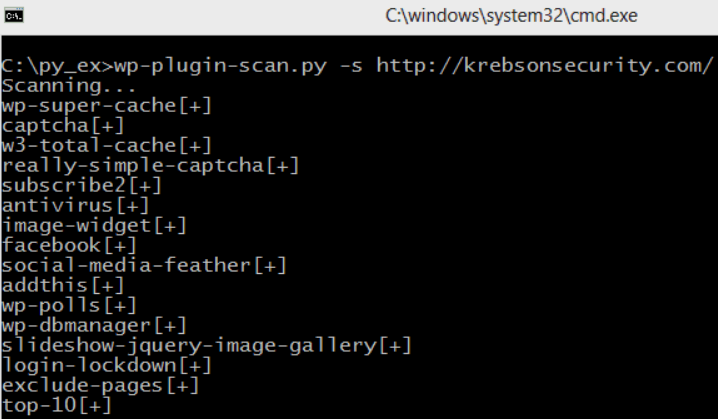
Разумеется, этот пункт относится только к популярным движкам (wp, joomla, drupal и подобным), а не студийным поделкам сумрачных гениев.
3. Ищем уязвимости в CMS. Первым делом идем на bug-трекеры. Чекаем CMS на сайтах:
- http://1337day.com/
- http://exploit-db.com/
- http://securityfocus.com/
- http://securiteam.com/
- http://osvdb.org/
- http://cxsecurity.com/exploit/
- http://packetstormsecurity.com/files/tags/exploit/
- http://cve.mitre.org/
Стоит особенно отметить 1337day (наследник милворма):

И exploit-db:

Если сплойт не пашет, то внимательно изучите исходник, есть шанс, что в сплойте допущена ошибка (по старой хэккерной традиции). Также очень часто бывает, что исходники движка нельзя найти, а сплойт под движок - легко.
Если ничего в паблике не нашлось, идем на страницы разработчиков и внимательно читаем changelog. Какие ошибки были исправлены, когда, обязательно обращаем внимание на патчи связанные с безопасностью.
4. Сканер директорий. После того как мы узнали CMS (или не узнали), мы натравливаем на сайт сканер директорий - DirBuster.

- DirBuster многопоточен, кроссплатформенен, красив и умен. Скачать можно по ссылке - http://sourceforge.net/projects/dirbuster/. Благодаря сканеру директорий, мы можем найти:WYSIWIG-редакторы
- файловые менеджеры
- phpmyadmin (и аналоги)
- скрипты статистики
- старые версии скриптов (index.php.old и т.д.)
- бекапы
- многое другое
Обыкновенно, сторонние скрипты подключают "as is", не беспокоясь о возможных уязвимостях. В общем никогда не забывайте пользоваться сканером директорий, даже если CMS определена и плагины успешно найдены. Может быть в забытой кодерами папке "/upload_old/new1/new11/new1111/old/upload.php" вас ждет форма заливки файлов без проверки на расширения и прочие условности.
5. Сбор параметров. После того как мы просканировали директории и файлы, необходимо узнать все точки входа.
Образно говоря, если бы мы грабили квартиру, то сначала проверили бы все двери, окна, замки, затем выбрали самую уязвимую цель (открытая форточка, фанерная дверь, китайский замок), затем мы бы начали использовать отмычки(или другой инструмент), чтобы попасть внутрь.
В хаке сайтов все то же самое - находим все точки входа в приложение (Get, post, cookie, заголовки приложения), затем ищем уязвимые параметры и пытаемся их экплуатировать (только если домушник пихает отмычки в замок, мы пихаем кавычки и скобки в формочки или строку браузера).
Для автоматизированного сбора страниц прекрасно подойдет Burp Suite (шикарная утилита, с которой вы скоро не будете расставаться).
- Скачать burp-suite - http://portswigger.net/burp/
- Справка по burp-suite - http://h4s-team.ru/bs/index/index.html
В обязательном порядке установите и ознакомьтесь со справкой. Это настоящий швейцарский нож для веб-приложений. И одна из его возможностей как раз позволяет собрать все страницы и все формы с сайта:

Запускаем спайдер, и он парсит все страницы со скоростью бешеной курицы, с горящими перьями.
Но не стоит скидывать со счетов и ручной анализ.
6. Обход mod_rewrite. Сейчас все повернулись на всяких seo-фишках. И многие юзают mod_rewrite (и подобные вещи), что сделать из некрасивой ссылки вида:
http://www.target.com/index.php?id=8...id=87&order=11
Получать такие ссылки:
http://www.target.com/content/8787/
К счастью, у нас не будет возникать проблем со сбором Post и Сookie параметров. Итак, чтобы обойти ЧПУ (человеко-подобный урл) нам нужно:
1. Узнать имя скрипта.
2. Узнать параметры скрипта.
3. Узнать принимаемые параметром значения.
Я бы конечно с радостью расписал все что нужно делать, но лучше всего написали тут - http://www.securitylab.ru/analytics/399778.php. Правда скрипт, упоминаемый в статье, уже удалили или перенесли. Но мы его заботливо сохранили для будущих поколений:
Код:
<?php
// defines
ini_set('max_execution_time', 0);
$charset = Array(
'a','b','c','d','e',
'f','g','h','i','j',
'k','l','m','n','o',
'p','q','r','s','t',
'u','v','w','x','y',
'z','-','_');
$wordlist = Array();
$param_file = './params.txt';
$separator = '_';
$words = Array();
$maxlen = $_GET['length'];
$def_length=0;
$site = $_GET['url'];
$count = 0;
$type = $_GET['type'];
$symbol = $_GET['sym'];
$arr = $_GET['arr'];
$max_len_of_url=2048;
function getlen($site_check)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$site_check);
curl_setopt($ch, CURLOPT_FAILONERROR, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
$length = strlen(curl_exec($ch));
curl_close($ch);
return $length;
}
function check($site_check,$from,$to)
{
global $def_length,$words,$site,$symbol;
$curr_len = getlen($site_check);
if ($curr_len<>$def_length)
{
// пытаемся определить нужный нам символ
echo '<b>[+] Find <a href='.$site_check.'>smth</a> Try to detect.</b><br>';
flush();
$site_1 = $site;
$site_2 = $site;
if ($to-1-$from > 0)
{
for ($i=$from;$i<=$to-1;$i++)
{
if ($i<=$from+(($to-$from)/2) - 1)
{$site_1 .= $words[$i].(($arr==1)?'[]':'').'='.$symbol.'&';}
else
{$site_2 .= $words[$i].(($arr==1)?'[]':'').'='.$symbol.'&';}
}
check($site_1 ,$from,(int)($from+(($to-$from)/2)));
check($site_2 ,(int)($from+(($to-$from)/2)),$to);
flush();
}
else
{
echo '<b>[+] Find! <a href='.$site_check.'>'.$site_check.'</a></b><br>';
}
}
}
function recurse($width, $position, $base_string)
{
global $charset,$site_new,$site,$words,$count, $values,$type,$separator,$wordlist,$symbol,$max_len_of_url;
for ($i = 0; $i < count($charset); ++$i)
{
// если длина сообщения меньше требуемой - берем символ и рекурсивно вызываем сами себя
if ($position < $width - 1)
{
recurse($width, $position + 1, $base_string . $charset[$i]);
}
// когда рекурсивные вызовы заканчиваются, возвращаемся на шаг назад по числу символов и выводим
if (!in_array($base_string.$charset[$i],$values))
{
$words[$count] = $base_string.$charset[$i].(($arr==1)?'[]':'');
$count++;
$site_new .= $base_string . $charset[$i].(($arr==1)?'[]':'').'='.$symbol.'&';
}
if ((strlen($site_new)+strlen($base_string)+4)>$max_len_of_url)
{
check($site_new,0,$count);$site_new = $site;$count = 0;
}
}
if (($position == 0) && ($site_new != $site))
{check($site_new,0,$count);}
}
if (empty($_GET['url']) || empty($_GET['length']) || empty($_GET['type']) || empty($_GET['sym']))
{
echo '<b>[+] Use http://'.$_SERVER['HTTP_HOST'].$_SERVER['PHP_SELF'].'?url=<url>&type=<type of attack>&length=<max len>&sym=<parameter value><br> </b>
<b> url examples:</b> <br/> http://site.com/index.php <br/> http://site.com/index.php?param=123 <br/> http://site.com/index.php?param=123%26param2=q <br/>
<b> types of attack:<br/> </b>
1 - only bruteforce<br/>
2 - only wordlist<br/>
3 - word+separator+brute values<br/>
&arr=1 - try [] postfix values<br/>
</b>';
exit;
}
if (strpos($site,'?')>0)
{$site=$site.'&';}
else
{$site=$site.'?';}
$site_new = $site;
// найдем все параметры
preg_match_all("/[\?&]?([^&?=]+)=([a-zA-Z0-9\-_\.%]+)&/",
$site,
$out, PREG_PATTERN_ORDER);
$values = $out[1];
echo '<b>[+] Analyze <a href='.$site.'>'.$site.'</a></b><br>';
flush();
if ($type >=2)
{
$file = fopen($param_file,"r");
if(!file)
{
echo("<b>[+] Error: wordlist not exists - ".$param_file.'</b></br>');
}
else
{
while ($wordlist[] = trim(fgets($file)))
{}
unset ($wordlist[count($wordlist)-1]);
echo "<b>[+] Wordlist loaded...".count($wordlist)." words.</b><br/>";
}
}
// определим дефолтные значения
$def_length = getlen($site);
switch ($type) {
case 1:
recurse($maxlen, 0, '');
break;
case 2:
unset($charset);
$charset[] = '';
for ($j = 0; $j < count($wordlist);$j++)
{
if (!in_array($wordlist[$j],$values))
{
$words[$count] = $wordlist[$j].(($arr==1)?'[]':'');
$count++;
$site_new .= $wordlist[$j].(($arr==1)?'[]':'').'='.$symbol.'&';
}
if ((strlen($site_new)+strlen($base_string)+4)>2048)
{
check($site_new,0,$count);$site_new = $site;$count = 0; //unset ($words); $words = array();// $words = array();
}
}
if ($site_new != $site)
{check($site_new,0,$count);}
break;
case 3:
if (!in_array('',$charset))
{$charset[count($charset)]='';}
for ($j = 0; $j < count($wordlist);$j++)
{recurse($maxlen, 0, $wordlist[$j].$separator);}
break;
}
echo '<b>[+] Done</b><br>';
?>
Возможно, что сейчас информация про обход mod_rewrite кажется для вас лишней. Если будет нужно - вернетесь к данному материалу позже. А пока просто отметьте для себя, что можно успешно ломать сайты и с ЧПУ.
В принципе со сбором информации мы закончили. Если на прошлом этапи мы собирали общую информацию, то тут мы занимались исключительно веб-приложением. Узнали CMS, модули, искали сплоиты, просканировали директории и файлы, собрали все точки входа.