Устанавливаем ComfyUI и используем Stable Diffusion 3
LOLZTEAM
Пользуемся новой нейросетью на Windows!
Статья носит образовательный характер, мы ни к чему не призываем и не обязываем. Информация представлена исключительно в ознакомительных целях.
Больше интересных статей на нашем форуме: https://zelenka.guru/articles/
Подписывайтесь на канал и делитесь ссылкой на статью с друзьями!

На сегодняшний день это самая продвинутая open-source модель для генерации изображений с 2 миллиардами параметров, которая адекватно функционирует даже на ноутбуках. Её качество генерации изображений на высшем уровне, а понимание текстовых запросов впечатляющее, по сравнению с предыдущими версиями Stable Diffusion.

Поддержка модели уже есть в ComfyUI, для Automatic1111 придётся подождать. Поэтому в этой статье мы убьём одним выстрелом двух зайцев: расскажем, как установить ComfyUI и поставим Stable Diffusion 3..

ComfyUI — это пользовательский интерфейс (UI) для создания изображений с преобразованием текста в изображение с использованием моделей Stable Diffusion. Он предлагает большую гибкость и контроль, чем Automatic1111, что делает его лучшим выбором для опытных пользователей, которым нужен больший контроль над процессом создания изображений.

Переходим на официальный репозиторий GitHub:
https://github.com/comfyanonymous/ComfyUI
Теперь заходим в раздел Releases, который находится на этой же странице репозитория - https://github.com/comfyanonymous/ComfyUI/releases.

Здесь вы найдете единственный релиз с установщиком последней версии и автообновлениями. Нам нужно будет нажать на гиперссылку «Download Link with stable pytorch 2.3 cu121»
Делаем клик по гиперссылке:

Если вы всё правильно сделали, начнётся скачивание архива, в котором будет находиться всё необходимое для работы.

По окончании загрузки распаковываем архив в удобное для нас место.


После проделанных действий, изображённых выше, начнётся процесс распаковки.

По окончании распаковки заходим в папку «ComfyUI_windows_portable» и запускаем файл «run_nvidia_gpu.bat».

После проделанных действий должна запуститься командная строка и открыться сайт http://127.0.0.1:8188.

Немного про ноды (узлы) в интерфейсе ComfyUI
По изображению выше, вы уже можете представить себя в роли сис. админа, прокладывающего кабели. Все, что вы видите на картинке, — это стандартная схема, используемая по умолчанию в ComfyUI.
Ноды — это функциональные блоки для алгоритмов на Python, которые можно соединять линиями в логические цепочки. Они выполняют ту же роль, что и меню в automatic1111, задавая параметры для формирования изображения, но здесь их можно конструировать в сложные системы вручную и тонко настраивать, что в automatic1111 было бы невозможно. Это и плюс, и минус одновременно: множество возможностей, но разобраться в них непросто.
Для удобного взаимодействия с нодами можно поставить ComfyUI-Manager, но об этом чуть позже.
Заходим на https://huggingface.co/stabilityai/stable-diffusion-3-medium. Для доступа к файлам необходимо заполнить небольшую форму (проявляем смекалочку и заполняем на рандом).

Как только у нас появится доступ к репозиторию на Hugging Face, переходим во вкладку с файлами: https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main. Здесь нам будут доступны модели и текстовые кодировщики.
Про разницу моделей:
Для удобства пользователей мы подготовили три варианта упаковки модели SD3 Medium, каждый из которых оснащен одинаковым набором весов MMDiT и VAE.
- sd3_medium.safetensors включает в себя грузики MMDiT и VAE, но не включает в себя текстовые кодировщики.
- sd3_medium_incl_clips_t5xxlfp8.safetensors содержит все необходимые веса, включая fp8-версию текстового кодера T5XXL, обеспечивая баланс между качеством и требованиями к ресурсам.
- sd3_medium_incl_clips.safetensors содержит все необходимые веса, кроме текстового кодировщика T5XXL. Он требует минимальных ресурсов, но без кодировщика текста T5XXL производительность модели будет отличаться.
- Папка text_encoders содержит три текстовых кодировщика и ссылки на их оригинальные карты моделей для удобства пользователей. На все компоненты в папке text_encoders (и их аналоги, включенные в другие пакеты) распространяются соответствующие оригинальные лицензии.
- Папка example_workfows содержит примеры удобных рабочих процессов.
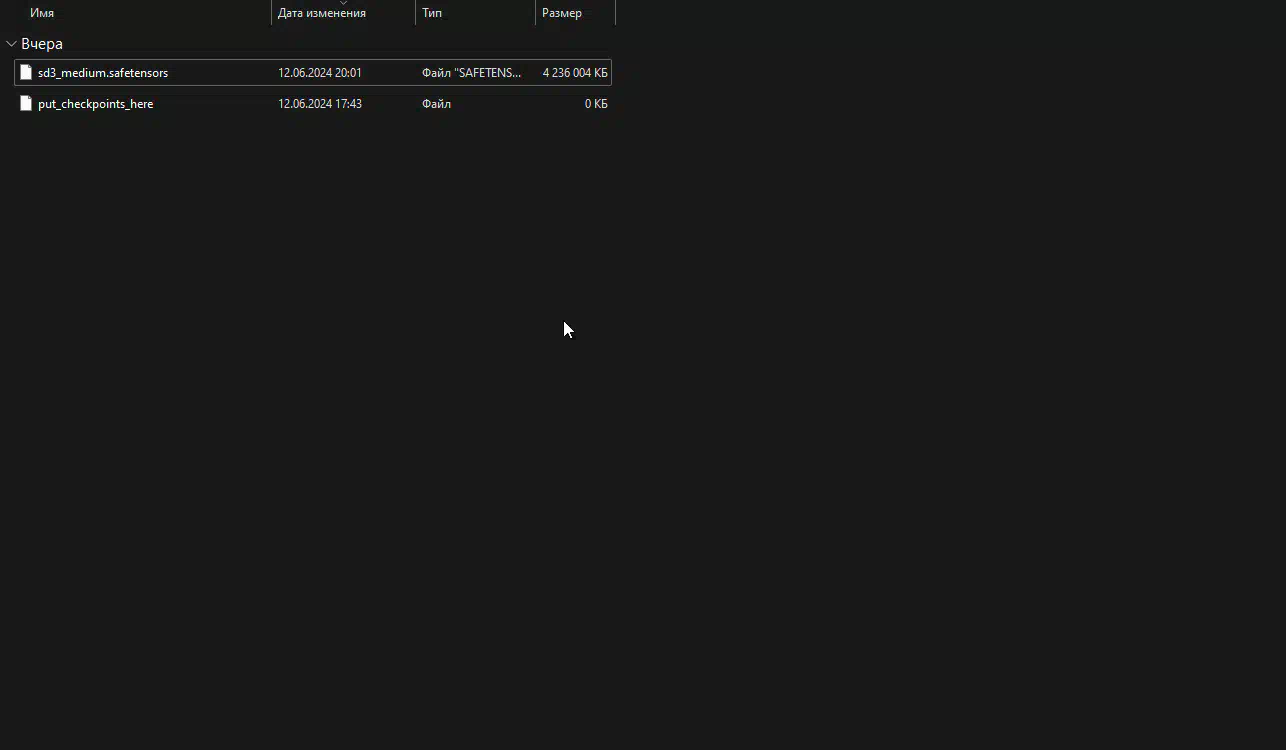
Лично я буду скачивать sd3_medium и кодировщики текста к нему (clip_g.safetensors, clip_l.safetensors, t5xxl_fp8_e4m3fn.safetensors).

Кодировщики текста нужно будет закинуть по пути \ComfyUI_windows_portable\ComfyUI\models\clip, а модели в \ComfyUI_windows_portable\ComfyUI\models\checkpoints.
Закидываем модели по соответствующим папкам:
Теперь можем вернуться в наш интерфейс и нажать кнопку «Refresh» для обновления списка моделей.
Обновляем список моделей через кнопку Refresh в интерфейсе

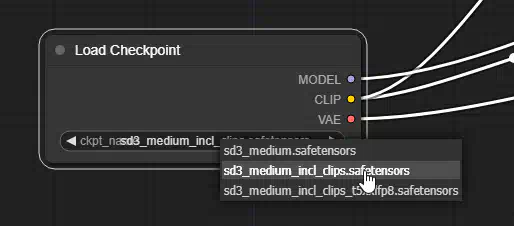
Если вы выбрали модели с текстовым кодировщиком внутри, то вам будет достаточно использовать стандартную схему, останется лишь выбрать модель. Кликаем по тексту в Load Checkpoint и открываем список с моделями.
Выбираем модель:
Для тех, кто скачал текстовые кодировщики отдельно, следует перейти на страницу https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main/comfy_example_workflows с готовыми базовыми схемами и скачать ту, которая нужна. Я сделал выбор на «sd3_medium_example_workflow_basic.json».
Скачиваем схему и импортируем ее в ComfyUI:
Жмем кнопочку «Load» в интерфейсе и выбираем схему:

После импорта схемы мы увидим что-то страшное и непонятное, но нам самое главное найти «Load Checkpoint» и «TripleCLIPLoader», а затем выставить необходимые настройки.

Выбор модели и текстовых кодировщиков завершен, теперь можем поговорить немного о базовых настройках в схеме.
Рандомизация сидов, размер изображения на выходе и снова про узлы из текущей схемы
Базовые настройки и их определение:
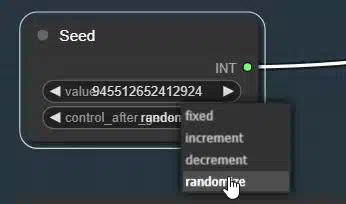
Если вы хотите использовать генерацию случайного сида для каждого изображения, поставьте «randomize».
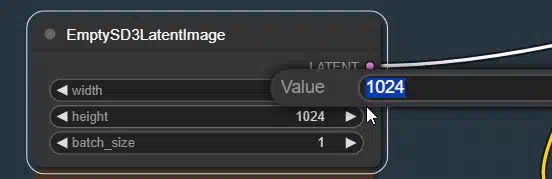
Настройка ширины и высоты на выходе. Я бы советовал оставить текущие параметры.
Про prompt и negative prompt
Промпт (от англ. prompt) — это запрос к нейросети с целью получить желаемое изображение или текст. Чем четче и правильнее прописан промпт, тем более релевантным будет результат.
Negative Prompt (или отрицательная подсказка) - это дополнение к Prompt, которое уточняет, что не следует включать в изображение. Он указывает на элементы или аспекты, которые пользователь не хочет видеть на создаваемом изображении.
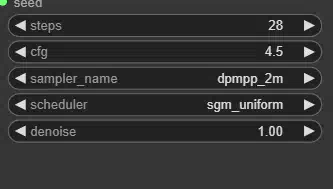
steps, cfg, sampler name, scheduler, denoise steps — количество шагов, используемых при денуазировании. Чем больше шагов может сделать сэмплер, тем точнее будет результат.
CFG Scale (classifier-free guidance scale) — это величина соответствия текстовому запросу. Чем больше, тем ближе результат к запрошенному, но вместе с тем и более шумный.
sample name — какой сэмплер будет использовать ComfyUI
scheduler — тип используемого расписания
denoise — сколько информации о латентах должно быть стерто шумом.
Описание для каждого узла из схемы.
Load Checkpoint Узел Load Checkpoint можно использовать для загрузки диффузионной модели, диффузионные модели используются для денуации латентов. Этот узел также предоставит соответствующую модель VAE и CLIP.
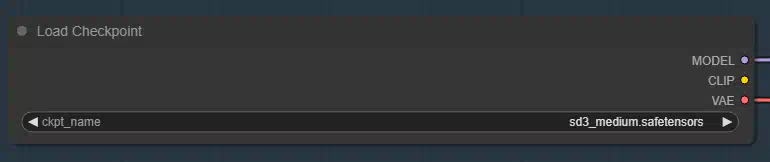
Load CLIP:
Узел Load CLIP можно использовать для загрузки определенной модели CLIP. Модели CLIP используются для кодирования текстовых подсказок, которые направляют процесс распространения.
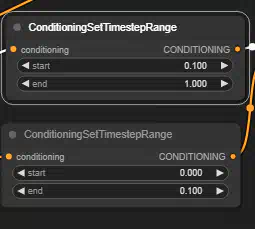
ConditioningSetTimestepRange — это новый узел в ComfyUI, а также один из самых мощных инструментов кондиционирования текста, которые у нас есть.
Узел позволяет задать временную позицию запуска/остановки для каждого запроса. Допустим, у нас есть 20 шагов, вы можете сказать сэмплеру, чтобы он начал «раскрашивать» кота на 5 шагов (которые, вероятно, самые важные), а затем забыть о кошке и начать генерировать собаку для оставшихся 15.
Sampling nodes:
Узлы cэмплирования обеспечивают возможность устранения скрытых помех на изображениях с использованием диффузионной модели. Чтобы получить обзор доступных графиков и выборок, воспользуйтесь,
Seed:
Интуитивно понятный узел управления сидами, который работает очень похоже на управление сидами от Automatic1111.
Empty latent image:
Пустой узел скрытого изображения можно использовать для создания нового набора пустых скрытых изображений. Эти скрытые изображения затем можно использовать, например, в рабочем процессе text2image, добавляя к ним шумы с помощью узла sampler.
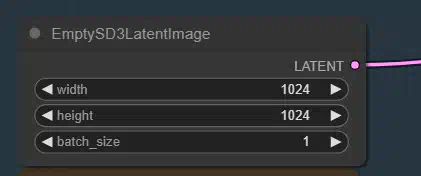
CLIP Text Encode (Prompt):
Узел CLIP Text Encode можно использовать для кодирования текстовой подсказки с помощью модели CLIP во вставку, которая может быть использована для направления модели диффузии на генерацию определенных изображений.
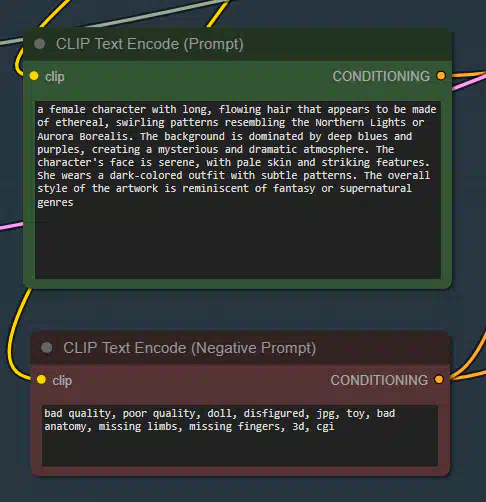
ConditioningZeroOut:
ConditioningZeroOut - этот узел обнуляет определенные элементы в структуре данных обусловливания, эффективно нейтрализуя их влияние на последующих этапах обработки. Он предназначен для расширенных операций кондиционирования, где требуется прямое манипулирование внутренним представлением обусловливания.
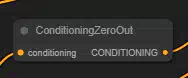
Conditioning (Combine):
Узел Conditioning (Combine) можно использовать для объединения нескольких кондиционирований путем усреднения прогнозируемого шума диффузионной модели. Обратите внимание, что это отличается от узла Conditioning (Average). Здесь выходы диффузионной модели, обусловленные различными условиями (т. е. все части, составляющие условие), усредняются, а узел Conditioning (Average) интерполирует текстовые вкрапления, хранящиеся внутри условия.
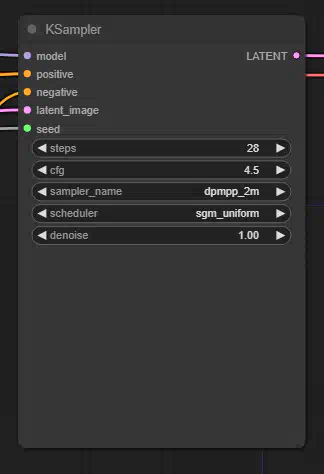
KSampler:
KSampler использует предоставленную модель и положительные и отрицательные условия для создания новой версии латента. Сначала латент подвергается шумоподавлению в соответствии с заданными параметрами seed и denoise strength, в результате чего стирается часть латентного изображения. Затем этот шум удаляется с использованием заданной модели и положительных и отрицательных условий в качестве руководства, "создавая" новые детали в тех местах, где изображение было стерто шумом.
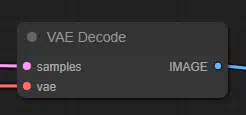
VAE Decode Узел VAE Decode может использоваться для декодирования изображений латентного пространства обратно в изображения пиксельного пространства с помощью предоставленного VAE.
Preview Image:
Узел Preview Image можно использовать для предварительного просмотра изображений в графе узлов.
Как только настроите ComfyUI под свои требования, а также укажите prompt и negative prompt, можно будет перейти к генерации изображения. Для генерации нажимаем кнопочку «Queue prompt».
Генерируем изображение:
Как мы видим, изображение было добавлено в очередь.
В командной строке мы также можем наблюдать за процессом генерации изображений.

Как только генерация будет завершена, мы увидим картинку в превьюшке (output).
Итоговый результат

ComfyUI-Manager — это расширение, предназначенное для повышения удобства использования ComfyUI. Он предлагает функции управления для установки, удаления, отключения и включения различных пользовательских узлов ComfyUI. Кроме того, это расширение предоставляет функцию концентратора и удобные функции для доступа к широкому спектру информации в ComfyUI.

Чтобы его установить переходим по пути \ComfyUI\custom_nodes и открывать в этой папке cmd


В командной строке пишем «git clone https://github.com/ltdrdata/ComfyUI-Manager.git» и дожидаемся завершения загрузки. (если git нет — установите с сайта https://git-scm.com/downloads)

Перезагружаем интерфейс и радуемся жизни.

На этом всё. Удачи!
Наш форум: https://zelenka.guru
Наши проекты в Telegram: https://t.me/zelenka_guarantor_robot
