Using little-known Google features to find hidden thingsUse little-known Google features to find hidden things
Obtaining private data does not always mean hacking - sometimes it is published in the public domain. Knowing Google's settings and a little bit of wit can lead to a lot of interesting things, from credit card numbers to FBI documents.

All information is provided for informational purposes only. Neither the editors nor the author are responsible for any possible harm caused by the materials in this article.
Nowadays, everything is connected to the Internet, with little concern for restricting access. That is why many private data are preyed upon by search engines. Robots "spiders" are no longer limited to web pages, and index all available content on the web and constantly add to their databases of information not intended for disclosure. It's easy to find out these secrets, you just need to know how to ask for them.
Searching for files
In the right hands, Google will quickly find all sorts of things on the web, such as private information and proprietary files. They are often hidden like a key under a doormat: there are no real access restrictions, the data simply lie at the back of the site, where no links lead. Google's standard web interface provides only basic advanced search settings, but even they will suffice.
You can limit your search to certain kinds of files on Google by using two operators: filetype and ext. The first specifies the format that the search engine has determined from the file header, the second specifies the extension of the file, regardless of its internal contents. When searching in both cases, you only need to specify the extension. Originally, ext operator was conveniently used when files had no specific format attributes (e.g., to search for configuration files ini and cfg, which can contain anything). Now Google algorithms have changed, and there is no visible difference between operators - the results are the same in most cases.

Filter output
By default, Google searches all of the files on the indexed pages for words and, by default, for any characters you type. You can limit the search area by the top-level domain, a specific site, or by the location of the sequence in the files themselves. For the first two options, the operator site is used, after which the name of the domain or the selected site is entered. In the third case, a set of operators allows you to search for information in the service fields and metadata. For example, allinurl finds what you want in the links body, allinanchor finds it in the text with the <a name> tag, allintitle finds it in the page titles and allintext finds it in the page body.
For each operator there is a lighter version with a shorter name (without prefix all). The difference is that allinurl finds links with all words, while inurl finds links with only the first of them. The second and subsequent words in the query can be found anywhere on Web pages. The inurl operator is also different from the other, similar in meaning, site. The former also allows to find any sequence of characters in a link to the document sought (e.g., /cgi-bin/), which is widely used to search for components with known vulnerabilities.
Let's try it in practice. We filter allintext and make a query with a list of credit card numbers and verification codes, that will expire in two years only (or when their owners will be fed up with feeding everyone).
allintext: card number expiration date /2017 cvv
Searching for files
In the right hands, Google will quickly find all sorts of things on the web, such as private information and proprietary files. They are often hidden like a key under a doormat: there are no real access restrictions, the data simply lie at the back of the site, where no links lead. Google's standard web interface provides only basic advanced search settings, but even they will suffice.
You can limit your search to certain kinds of files on Google by using two operators: filetype and ext. The first specifies the format that the search engine has determined from the file header, the second specifies the extension of the file, regardless of its internal contents. When searching in both cases, you only need to specify the extension. Originally, ext operator was conveniently used when files had no specific format attributes (e.g., to search for configuration files ini and cfg, which can contain anything). Now Google algorithms have changed, and there is no visible difference between operators - the results are the same in most cases.

When you read in the news that a young hacker "hacked into the servers" of the Pentagon or NASA, stealing classified information, most of the time it is this elementary technique of using Google. Suppose we are interested in a list of NASA employees and their contact information. Surely such a list is available electronically. For convenience, or by oversight, it may lie on the site of the organization. It is logical that in this case it will not be referenced, because it is intended for internal use. What words can be in such a file? At least the "address" field. Checking all these assumptions is easy.

Write
inurl:nasa.gov filetype:xlsx "address"
and get links to files with lists of employees.
и получаем ссылки на файлы со списками сотрудников.

Taking advantage of bureaucracy.
Such finds are nice little things. A really solid catch is a more detailed knowledge of Google's operators for webmasters, the web itself, and the specifics of the structure of what you're looking for. Knowing the details makes it easy to filter the output and refine the properties of the desired files to get really valuable data in the remainder. The funny thing is that this is where bureaucracy comes in. It produces standard formulations that make it easy to search for secret information that was accidentally leaked.
For example, a Distribution statement from the U.S. Defense Department's office indicates standardized restrictions on document distribution. A indicates public releases that are not classified, B - intended for internal use only, C - strictly confidential, and so on to F. There is a separate X, which stands for especially valuable information that is a top-level state secret. Let those who are supposed to search for such documents search for them, and we will limit ourselves to files with the letter C. According to DoDI 5230.24, this designation is assigned to documents containing descriptions of critical technologies that are subject to export control. Such closely guarded information can be found on sites in the U.S. Army's .mil top-level domain.
"DISTRIBUTION STATEMENT C" inurl:navy.mil

Conveniently, the .mil domain contains only sites from the U.S. Department of Defense and its contract organizations. Search results with domain restriction are exceptionally clean, and the headings speak for themselves. Looking for Russian secrets in this way is practically useless: the .ru and .rf domains are chaotic, and the names of many weapons systems sound nerdy (Kiparis, Acacia) or even fabulous (Buratino).

A close look at any document from a .mil site reveals other markers to refine your search. For example, a reference to "Sec 2751" export restrictions, which is also a good place to look for interesting technical information. From time to time it is removed from official sites where it once appeared, so if you can't follow an interesting link in the search results, use Google's cache (cache operator) or the Internet Archive site.
Climbing the cloud
In addition to accidentally declassified government agency documents, links to personal files from Dropbox and other storage services occasionally pop up in Google's cache, which create "private" links to publicly published data. It's even worse with alternative and homemade services. For example, the following query finds data from all Verizon customers who have an FTP server installed on their router and are actively using it.
allinurl:ftp:// verizon.net
There are now over forty thousand such smart guys, and in the spring of 2015 there were many more. Instead of Verizon.net, you can substitute the name of any well-known provider, and the more famous it is, the bigger the catch can be. Through the built-in FTP server, you can see files on an external storage device connected to the router. Usually this is a NAS for remote work, a personal cloud or some sort of peer-to-peer file downloader. All the contents of such media turn out to be indexed by Google and other search engines, so you can access the files stored on external drives through a direct link.

Looking into configurations
Before the mass migration to the clouds, simple FTP-servers ruled as remote storages, which also had enough vulnerabilities. Many of them are still relevant today. For example, popular program WS_FTP Professional stores data on configuration, user accounts and passwords in file ws_ftp.ini. It is easy to find and read, because all entries are saved in text format, and passwords are encrypted with Triple DES algorithm after minimal obfuscation. In most versions, you just need to discard the first byte.

Such passwords can be easily decrypted using WS_FTP Password Decryptor utility or free web service.

When talking about hacking an arbitrary site, we usually mean obtaining the password from logs and backups of CMS configuration files or e-commerce applications. If you know their typical structure, you can easily specify keywords. Lines like those found in ws_ftp.ini are extremely common. For example, in Drupal and PrestaShop there is always a user ID (UID) and the corresponding password (pwd), and all information is stored in files with the extension .inc. They can be searched as follows:
"pwd=" "UID=" ext:inc
Discovering DBMS passwords
The configuration files of SQL servers store user names and email addresses in clear text, and their MD5 hashes are written instead of passwords. Strictly speaking, they are impossible to decrypt, but you can find a match between known hash-password pairs.

There are still DBMSs that do not even use password hashing. The configuration files of any of them can simply be viewed in a browser.
intext:DB_PASSWORD filetype:env

With the advent of Windows servers, the place of configuration files is partially taken by the registry. You can search its branches in exactly the same way, using reg as the file type. For example, like this:
filetype:reg HKEY_CURRENT_USER "Password"=

Don't forget the obvious
Sometimes it is possible to get to the classified information with the help of data accidentally opened and caught by Google. The ideal option is to find a list of passwords in some common format. Only desperate people can keep account information in a text file, Word document or Excel spreadsheet, but there are never enough of them.
filetype:xls inurl:password

On the one hand, there are a lot of tools to prevent such incidents. It is necessary to specify adequate access rights in htaccess, patch CMS, not to use illegal scripts and close other holes. There is also a robots.txt file with an exceptions list, which prevents search engines from indexing files and directories mentioned in it. On the other hand, if the robots.txt structure on any server differs from the standard one, it immediately becomes apparent what the server is trying to hide.

A list of directories and files on any site is preceded by the standard index of. Since it must appear in the header for service purposes, it makes sense to limit its search to the intitle operator. Interesting things can be found in /admin/, /personal/, /etc/, and even /secret/.

Staying up to date
There are so many dorks today that the problem is no longer to find one of them, but to choose the most interesting ones (to study and improve your own security, of course). Examples of search queries that reveal someone's secrets are called Google dorks. One of the first tools to automatically check the security of sites for known queries on Google was McAfee SiteDigger, but its latest version was released in 2009. Now there are many other tools available to simplify the search for vulnerabilities. For example, SearchDiggity by Bishop Fox, as well as populated databases with a collection of relevant examples.
Being up to date is very important here: old vulnerabilities are being closed very slowly, but Google and its search results are changing all the time. There is even a difference between "last second" filter (&tbs=qdr:s at the end of the request url) and "real-time" filter (&tbs=qdr:1).
The time interval of the date when the file was last updated by Google is also specified implicitly. Through web GUI you can select one of the typical periods (hour, day, week, etc.) or specify a range of dates, but this method is not suitable for automation.
You can only guess from the appearance of the address bar that there is a way to limit result output using the &tbs=qdr: construct. The letter y after it sets the limit of one year (&tbs=qdr:y), m shows results for last month, w for last week, d for last day, h for last hour, n for last minute, and s for last second. The most recent results, which have just become known to Google, is found using the filter &tbs=qdr:1.
If you need to write a tricky script, it will be helpful to know that the date range is specified in Google in Julian format using the daterange operator. For example, this is how you can find a list of PDF documents with the word confidential uploaded from January 1 to July 1, 2015.
confidential filetype:pdf daterange:2457024-2457205
The range is given in Julian date format without the fractional part. It is not convenient to translate them manually from the Gregorian calendar. It is easier to use a date converter.
Targeting and filtering again
In addition to specifying additional operators in the search query you can send them directly in the link body. For example, the specification of filetype:pdf corresponds to the construction as_filetype=pdf. This makes it easy to specify any kind of refinement. For example, output only from Honduras is specified by adding cr=countryHN into search URL, and only from Bobruisk - gcs=Bobruisk. You can find the full list in the section for developers.
Google automation tools are designed to make life easier, but often add problems. For example, a user's IP through WHOIS determines his city. Based on this information Google not only balances the load between servers, but also changes the results of search results. Depending on the region with the same query on the first page will get different results, and some of them may be completely hidden. If you want to feel like a cosmopolitan and search for information from any country, use its two-letter code after directive gl=country. For example, the code of the Netherlands - NL, and the Vatican and North Korea in Google do not have their own code.
Search results are often cluttered, even after using several advanced filters. In that case, it's easy to refine the query by adding a few exclusion words (with a minus sign in front of each one). For example, banking, names and tutorial are often used with the word personal. Therefore, cleaner search results will be shown not by the textbook example of the query, but by the specified one:
intitle: "Index of /Personal/" -names -tutorial -banking
One last example
A sophisticated hacker differs in that he provides everything he needs on his own. For example, VPN is a handy thing, but it is either expensive or temporary and has limitations. It's too expensive to subscribe for yourself alone. The good thing is that there are group subscriptions, and with Google, it's easy to become part of some group. All you have to do is find the Cisco VPN configuration file, which has a rather non-standard PCF extension and a recognizable path: Program Files\Cisco Systems\VPN Client\Profiles. One request, and you join, for example, the friendly team of the University of Bonn.
filetype:pcf vpn OR Group
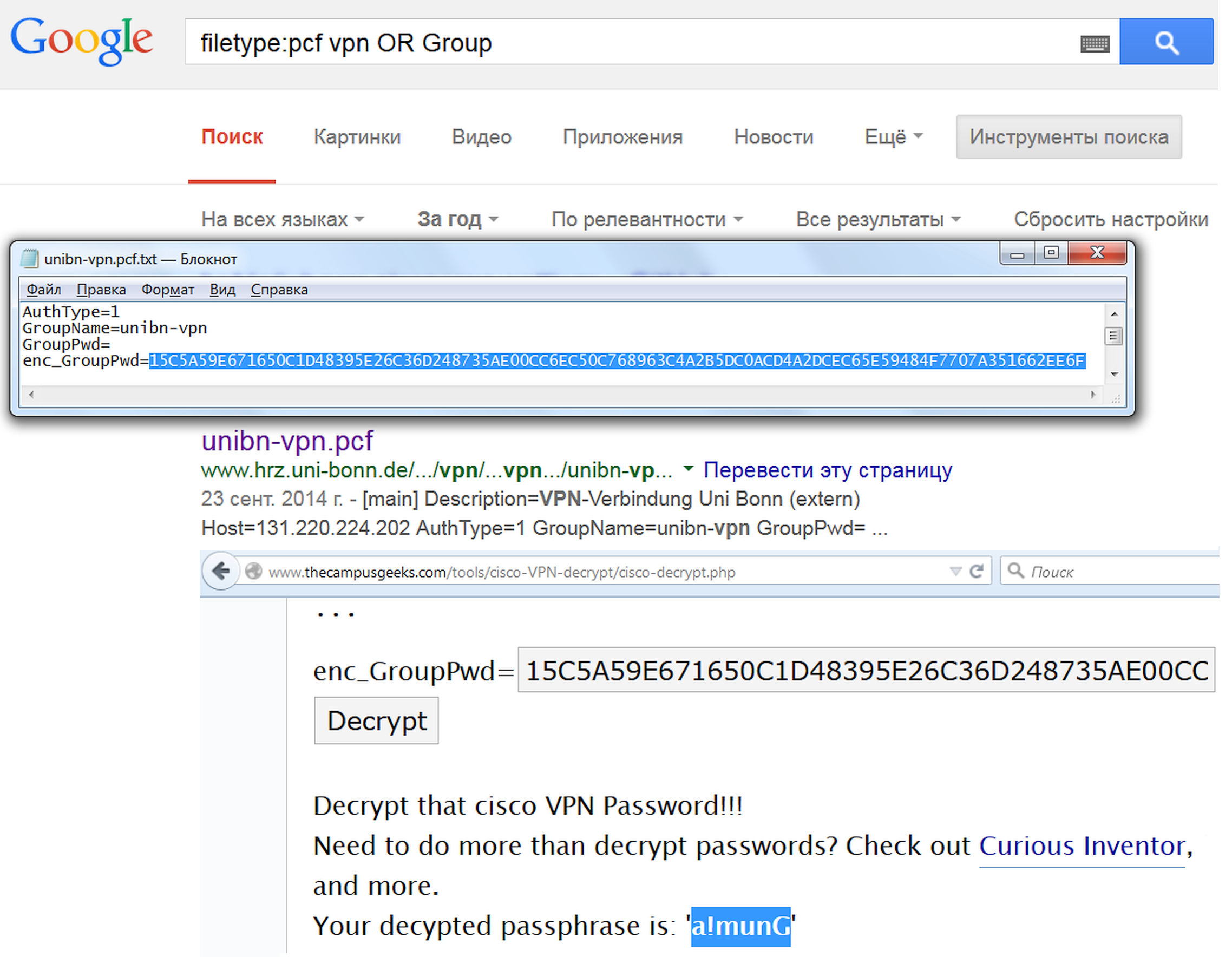
INFO
Google finds configuration files with passwords, but many of them are encrypted or replaced with hashes. If you see fixed-length strings, look for a decryption service right away.
Passwords are stored encrypted, but Maurice Massar has already written a program to decrypt them and provides it for free through thecampusgeeks.com.
There are hundreds of different types of attacks and penetration tests performed with Google. There are many variants affecting popular programs, major database formats, numerous PHP vulnerabilities, clouds, and so on. If you know exactly what you're looking for, it makes it a lot easier to get the information you want (especially that which was not planned to be in the public domain). Not Shodan's single feed of interesting ideas, but any database of indexed network resources!
SOURCES:
https://www.googleguide.com/advanced_operators_reference.html
https://www.exploit-db.com/google-hacking-database
https://xakep.ru/2015/07/08/google-hidden-functions/#toc01.