UniLecs #155. Алгоритм сжатия RLE
UniLecsЗадача: дана строка, необходимо написать алгоритм сжатия RLE, заменяющий повторяющиеся символы (серии) на один символ и число его повторов.
Примечание: упростим алгоритм сжатия RLE: если полученная строка оказалась больше исходной, то вывести исходную.
Входные данные: str - строка, состоящая из буквенных символов, в кодировке Unicode, размер строки от 1 до 1000.
Вывод: "сжатую" по алгоритму RLE строку.
Пример:
1. str = "зззААнууууДааааа"
Answer = "з3А2н1у4Д1а5"
2. str = "abc"
Answer = "abc"
Идея: проходим по строке и считаем последовательности одинаковых символов стоящих подряд. Важным моментом является тот факт, что после сжатия строка может оказаться больше исходной. Например: строка "abcca" после сжатия получится вида "a1b1c2a1". В таком случае нам нужно выводить первоначальную строку. Этот случай мы должны предусмотреть и не производить сжатие.
Реализация:

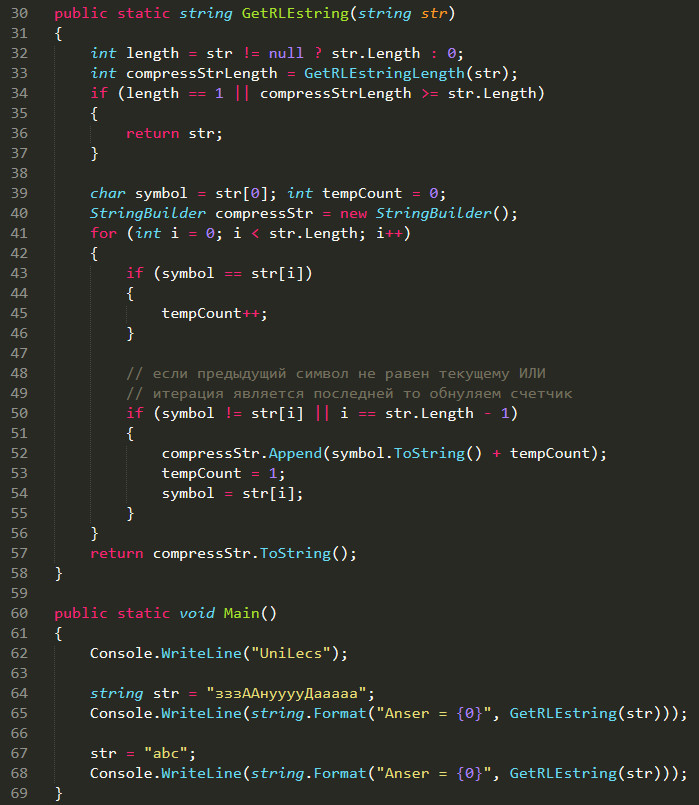
https://gist.github.com/unilecs/d9f662c5707d9bbfcfbf04c20f721eb5
Test: https://dotnetfiddle.net/ldeHCr
Применение алгоритма RLE
Распространённые форматы для упаковки данных с помощью RLE включают в себя PackBits, PCX и ILBM. Этим методом кодирования могут быть сжаты произвольные файлы с двоичными данными, поскольку спецификации на форматы файлов часто включают в себя повторяющиеся байты в области выравнивания данных.
Хотя стоит отметить, что современные системы сжатия чаще используют алгоритмы на основе LZ77, который мы рассмотрим позже.