Уменьшение Размерности (Обобщение)
Сегодня используют для:
- Рекомендательные Системы
- Красивые визуализации
- Определение тематики и поиска похожих документов
- Анализ фейковых изображений
- Риск-менеджмент
Популярные алгоритмы: Метод главных компонент (PCA), Сингулярное разложение (SVD), Латентное размещение Дирихле (LDA), Латентно-семантический анализ (LSA, pLSA, GLSA), t-SNE (для визуализации)
Изначально это были методы хардкорных Data Scientist'ов, которым сгружали две фуры цифр и говорили найти там что-нибудь интересное. Когда просто строить графики в экселе уже не помогало, они придумали напрячь машины искать закономерности вместо них. Так у них появились методы, которые назвали Dimension Reduction или Feature Learning.

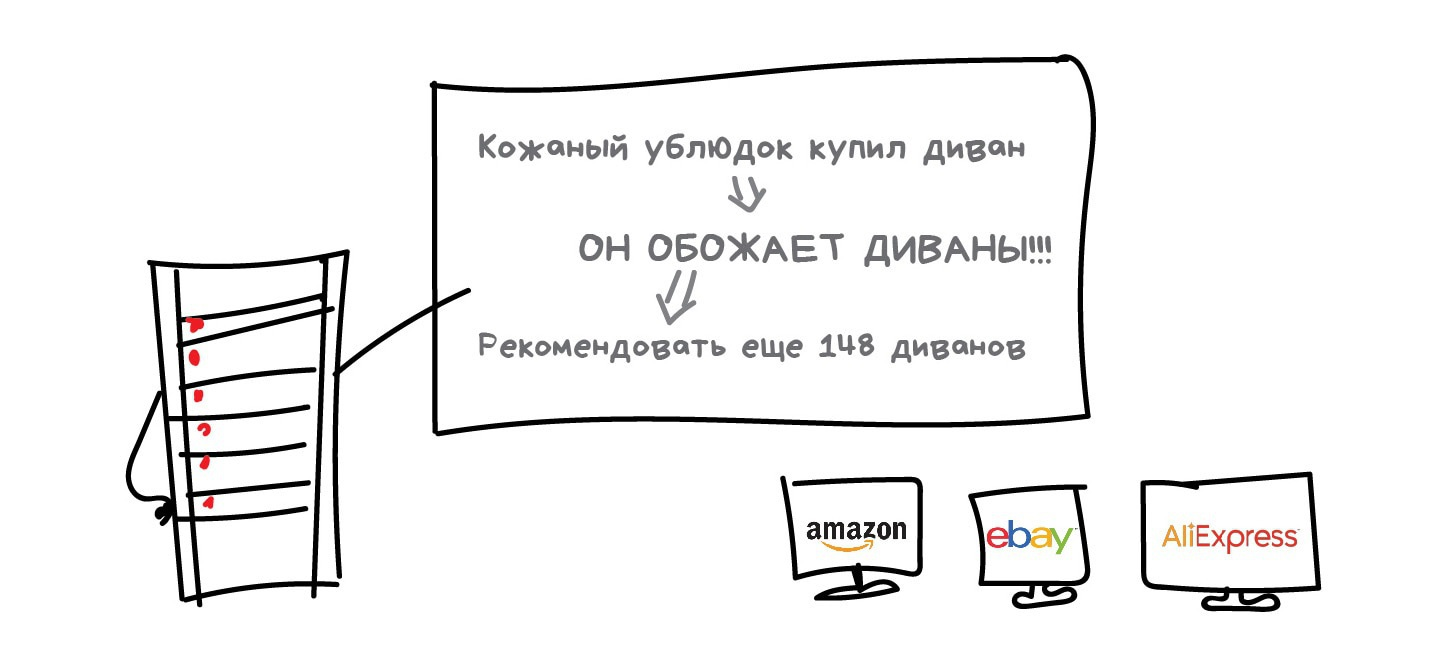
Для нас практическая польза их методов в том, что мы можем объединить несколько признаков в один и получить абстракцию. Например, собаки с треугольными ушами, длинными носами и большими хвостами соединяются в полезную абстракцию «овчарки». Да, мы теряем информацию о конкретных овчарках, но новая абстракция всяко полезнее этих лишних деталей. Плюс, обучение на меньшем количестве размерностей идёт сильно быстрее.
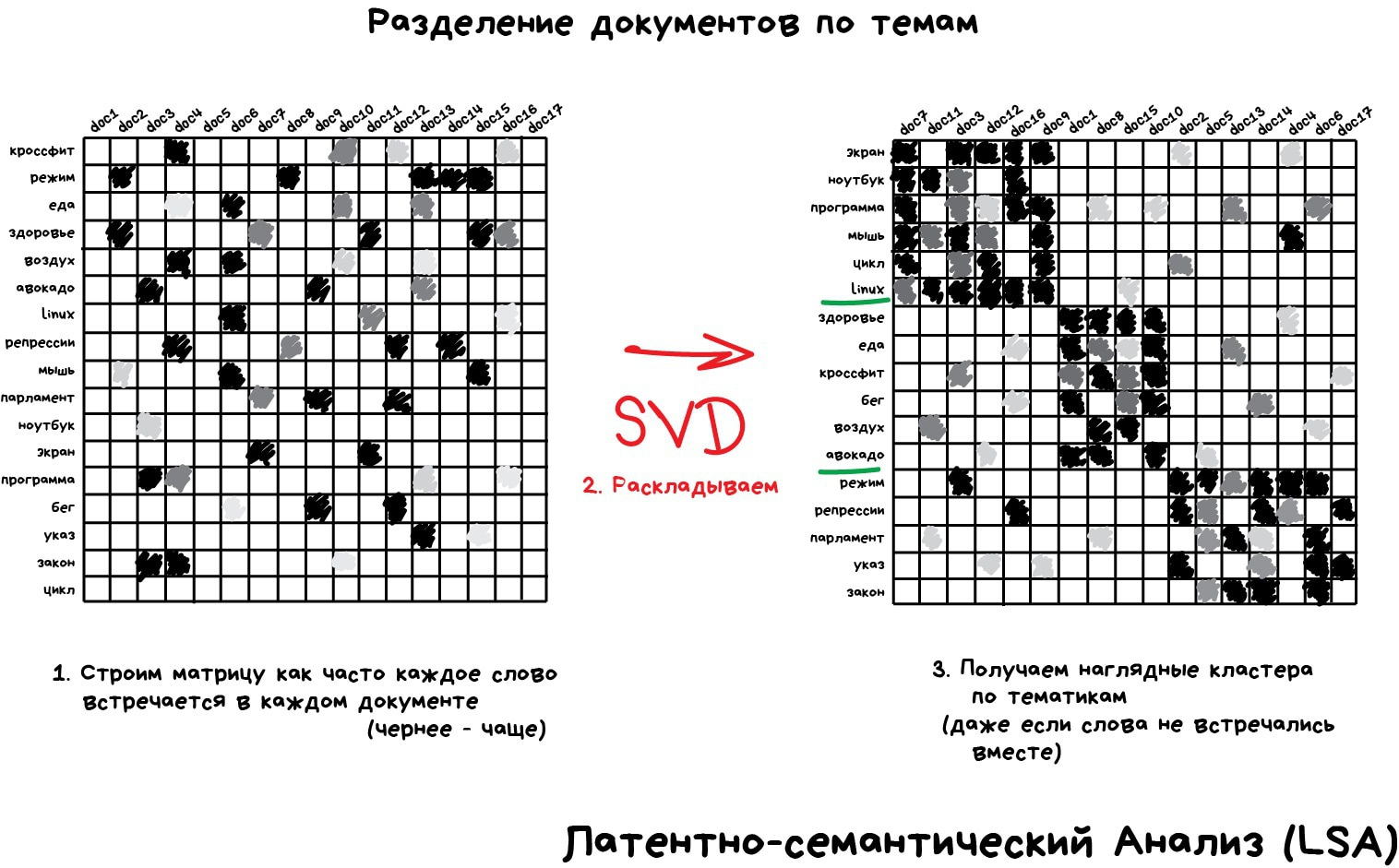
Инструмент на удивление хорошо подошел для определения тематик текстов (Topic Modelling). Мы смогли абстрагироваться от конкретных слов до уровня смыслов даже без привлечения учителя со списком категорий. Алгоритм назвали Латентно-семантический анализ (LSA), и его идея была в том, что частота появления слова в тексте зависит от его тематики: в научных статьях больше технических терминов, в новостях о политике — имён политиков. Да, мы могли бы просто взять все слова из статей и кластеризовать, как мы делали с ларьками выше, но тогда мы бы потеряли все полезные связи между словами, например, что батарейка и аккумулятор, означают одно и то же в разных документах.
Точность такой системы — полное дно, даже не пытайтесь.
Нужно как-то объединить слова и документы в один признак, чтобы не терять эти скрытые (латентные) связи. Отсюда и появилось название метода. Оказалось, что Сингулярное разложение (SVD) легко справляется с этой задачей, выявляя для нас полезные тематические кластеры из слов, которые встречаются вместе.
Для понимания рекомендую статью Как уменьшить количество измерений и извлечь из этого пользу, а практическое применение хорошо описано в статье Алгоритм LSA для поиска похожих документов.
Другое мега-популярное применение метода уменьшения размерности нашли в рекомендательных системах и коллаборативной фильтрации. Оказалось, если абстрагировать ими оценки пользователей фильмам, получается неплохая система рекомендаций кино, музыки, игр и чего угодно вообще.
Полученная абстракция будет с трудом понимаема мозгом, но когда исследователи начали пристально рассматривать новые признаки, они обнаружили, что какие-то из них явно коррелируют с возрастом пользователя (дети чаще играли в Майнкрафт и смотрели мультфильмы), другие с определёнными жанрами кино, а третьи вообще с синдромом поиска глубокого смысла.
Машина, не знавшая ничего кроме оценок пользователей, смогла добраться до таких высоких материй, даже не понимая их. Достойно. Дальше можно проводить соцопросы и писать дипломные работы о том, почему бородатые мужики любят дегенеративные мультики.
На эту тему есть неплохая лекция Яндекса — Как работают рекомендательные системы
Поиск правил (ассоциация)
Сегодня используют для:
- Прогноз акций и распродаж
- Анализ товаров, покупаемых вместе
- Расстановка товаров на полках
- Анализ паттернов поведения на веб-сайтах
Популярные алгоритмы: Apriori, Euclat, FP-growth
Сюда входят все методы анализа продуктовых корзин, стратегий маркетинга и других последовательностей.
Предположим, покупатель берёт в дальнем углу магазина пиво и идёт на кассу. Стоит ли ставить на его пути орешки? Часто ли люди берут их вместе? Орешки с пивом, наверное да, но какие ещё товары покупают вместе? Когда вы владелец сети гипермаркетов, ответ для вас не всегда очевиден, но одно тактическое улучшение в расстановке товаров может принести хорошую прибыль.
То же касается интернет-магазинов, где задача еще интереснее — за каким товаром покупатель вернётся в следующий раз?
По непонятным мне причинам, поиск правил — самая хреново продуманная категория среди всех методов обучения. Классические способы заключаются в тупом переборе пар всех купленных товаров с помощью деревьев или множеств. Сами алгоритмы работают наполовину — могут искать закономерности, но не умеют обобщать или воспроизводить их на новых примерах.
В реальности каждый крупный ритейлер пилит свой велосипед, и никаких особых прорывов в этой области я не встречал. Максимальный уровень технологий здесь — запилить систему рекомендаций, как в пункте выше. Хотя может я просто далёк от этой области, расскажите в комментах, кто шарит?