Уменьшаем расход памяти вдвое, добавив всего одну строчку кода
PythonGuru
Привет, любитель Python!
В одном проекте, где необходимо было хранить и обрабатывать довольно большой динамический список, тестировщики стали жаловаться на нехватку памяти. Простой способ, как «малой кровью» исправить проблему, добавив лишь одну строку кода, описан ниже. Результат на картинке:

Как это работает
Рассмотрим простой «учебный» пример — создадим класс DataItem, содержащий данные о человеке, например имя, возраст и адрес.
class DataItem(object):
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
Сколько такой объект занимает в памяти?
Попробуем решение в лоб:
d1 = DataItem("Alex", 42, "-")
print ("sys.getsizeof(d1):", sys.getsizeof(d1))
Получаем ответ 56 байт. Вроде немного, вполне устраивает.
Однако, проверяем на другом объекте, в котором данных больше:
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("sys.getsizeof(d2):", sys.getsizeof(d2))
Ответ — снова 56. На этом моменте понимаем, что что-то здесь не то, и не все так просто, как кажется на первый взгляд.
Интуиция нас не подводит, и все действительно не так просто. Python — это очень гибкий язык с динамической типизацией, и для своей работы он хранит немалое количество дополнительных данных. Которые и сами по себе занимают немало. Просто для примера, sys.getsizeof("") вернет 33 — да, целых 33 байта на пустую строку! А sys.getsizeof(1) вернет 24 — 24 байта для целого числа. Для более сложных элементов, таких как словарь, sys.getsizeof(dict()) вернет 272 байта — и это для пустого словаря. Дальше продолжать не будем, принцип ясен.
Однако вернемся к нашему классу DataItem и вопросу. Сколько занимает такой класс в памяти? Для начала, выведем целиком все содержимое класса на более низком уровне:
def dump(obj):
for attr in dir(obj):
print(" obj.%s = %r" % (attr, getattr(obj, attr)))
Эта функция покажет то, что скрыто «под капотом», чтобы все функции Python (типизация, наследование и прочие плюшки) могли функционировать.
Результат впечатляет:

Сколько это все занимает целиком? На github нашлась функция, подсчитывающая реальный объем данных, рекурсивно вызывая getsizeof для всех объектов.
def get_size(obj, seen=None):
# From https://goshippo.com/blog/measure-real-size-any-python-object/
# Recursively finds size of objects
size = sys.getsizeof(obj)
if seen is None:
seen = set()
obj_id = id(obj)
if obj_id in seen:
return 0
# Important mark as seen *before* entering recursion to gracefully handle
# self-referential objects
seen.add(obj_id)
if isinstance(obj, dict):
size += sum([get_size(v, seen) for v in obj.values()])
size += sum([get_size(k, seen) for k in obj.keys()])
elif hasattr(obj, '__dict__'):
size += get_size(obj.__dict__, seen)
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
size += sum([get_size(i, seen) for i in obj])
return size
Пробуем ее:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("get_size(d2):", get_size(d2))
Получаем 460 и 484 байта соответственно, что больше похоже на правду.
Имея эту функцию, можно провести ряд экспериментов. Например интересно, сколько места займут данные, если структуры DataItem положить в список. Функция get_size([d1]) возвращает 532 байта — видимо, это «те самые» 460 + некоторые накладные расходы. А вот get_size([d1, d2]) вернет 863 байта — меньше, чем 460 + 484 по отдельности. Еще интереснее результат для get_size([d1, d2, d1]) — мы получаем 871 байт, лишь чуть больше, т.е. Python достаточно «умен» чтобы не выделять память под один и тот же объект второй раз.
Теперь мы переходим ко второй части вопроса — можно ли уменьшить расход памяти? Да, можно. Python это интерпретатор, и мы в любой момент можем расширить наш класс, например добавить новое поле:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d1.weight = 66
print ("get_size(d1):", get_size(d1))
Это замечательно, но если нам не нужна эта функциональность, мы можем принудительно указать интерпретатору список объектов класса с помощью директивы __slots__:
class DataItem(object):
__slots__ = ['name', 'age', 'address']
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
Более подробно прочитать можно в документации (RTFM), в которой написано что "__slots__ allow us to explicitly declare data members (like properties) and deny the creation of __dict__ and __weakref__. The space saved over using __dict__ can be significant".
Проверяем: да, действительно significant, get_size(d1) возвращает… 64 байта вместо 460, т.е. в 7 раз меньше. Как бонус, создаются объекты примерно на 20% быстре (см. первый скриншот статьи).
Увы, при реальном использовании такого большого выигрыша в памяти не будет за счет других накладных расходов. Создадим массив на 100000 простым добавлением элементов, и посмотрим расход памяти:
data = []
for p in range(100000):
data.append(DataItem("Alex", 42, "middle of nowhere"))
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
total = sum(stat.size for stat in top_stats)
print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Имеем 16.8 Мбайт без __slots__ и 6.9 Мб с ним. Не в 7 раз конечно, но и так вполне неплохо, учитывая что изменение кода было минимальным.
Теперь о недостатках. Активация __slots__ запрещает создание всех элементов, включая и __dict__, значит к примеру, не будет работать такой код перевода структуры в json:
def toJSON(self):
return json.dumps(self.__dict__)
Но это просто исправить, достаточно сгенерировать свой dict программно, перебрав все элементы в цикле:
def toJSON(self):
data = dict()
for var in self.__slots__:
data[var] = getattr(self, var)
return json.dumps(data)
Также невозможно будет динамически добавлять новые переменные в класс, но в моем случае этого и не требовалось.
И последний тест на сегодня. Интересно посмотреть, сколько памяти занимает программа целиком. Добавим в конец программы бесконечный цикл, чтобы она не закрывалась, и посмотрим расход памяти в диспетчере задач Windows.
Без __slots__:

16.8Мб каким-то чудом превратилось (правка — объяснение чуда ниже) в 70Мб (программисты Си надеюсь еще не вернулись к экрану?).
С включенным __slots__:
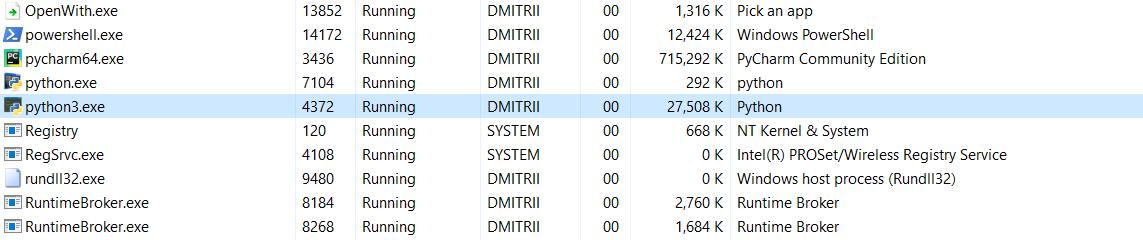
6.9Мб превратились в 27Мб… ну, все-таки память мы сэкономили, 27Мб вместо 70 это не так уж плохо для результата добавления одной строчки кода.
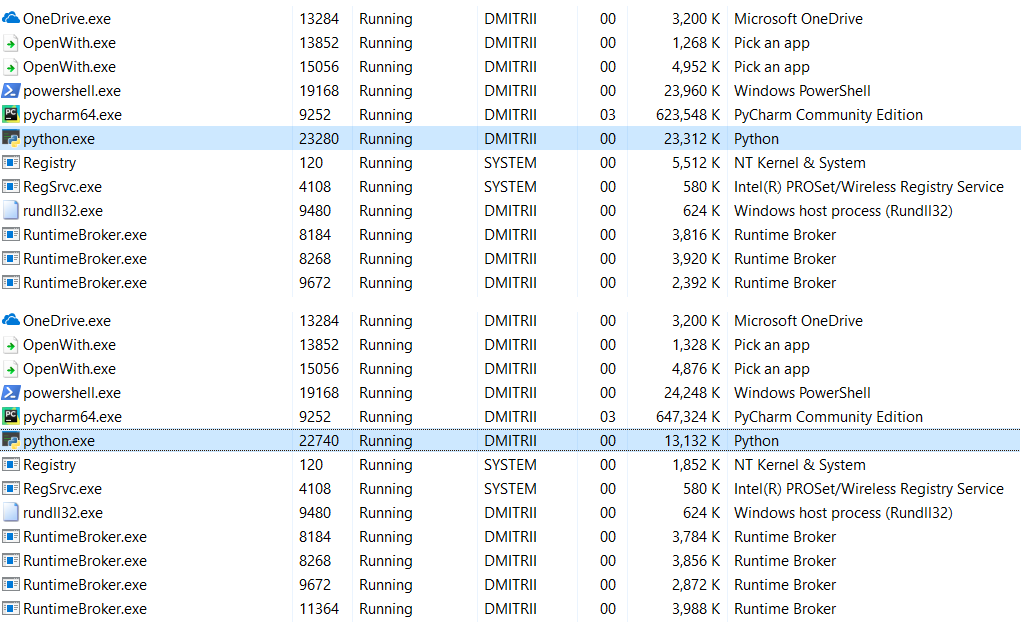
Правка: в комментариях (спасибо robert_ayrapetyan за проделанный тест) подсказали, что много дополнительной памяти занимает использование отладочной библиотеки tracemalloc. Видимо, она добавляет дополнительные элементы к каждому создаваемому объекту. Если отключить ее, суммарный расход памяти будет гораздо меньше, на скриншоте показаны 2 варианта:
Что делать, если нужно сэкономить еще больше памяти? Это возможно с использованием библиотеки numpy, позволяющей создавать структуры в Си-стиле, но в моем случае это потребовало бы более глубокой доработки кода, да и первого способа оказалось вполне достаточно.
Заключение
Может показаться, что данная статья является антирекламой Python, но это совсем не так. Python — очень надежный (чтобы «уронить» программу на Python надо очень сильно постараться), легко читабельный и удобный для написания кода язык. Эти плюсы во многих случаях перевешивают минусы, ну а если нужна максимальная производительность и эффективность, можно использовать библиотеки вроде numpy, написанные на С++, которые работают с данными вполне быстро и эффективно.
Совершенствуй знания по Python каждый день у нас на канале, PythonGuru.
Вопросы, реклама - @pythonguru_admin