Углублённое погружение в пространство имён в Linux (Часть 1)
ЛЕТОПИСЕЦ КИТЕЖ-ГРАДА
Введение: Данная статья будет построена на основе следующих двух частей из блога Quarkslab's:
- https://blog.quarkslab.com/digging-into-linux-namespaces-part-1.html
- https://blog.quarkslab.com/digging-into-linux-namespaces-part-2.html
Ранее мы уже затрагивали тему пространств имен, когда обозревали Docker. Однако в этот раз постараемся более предметно рассмотреть концепцию пространств имен в рамках системы Linux. Итак, приступим.
Определение пространства имён: Пространство имен – это функция ядра Linux, которая появилась в версии 2.6.24 в 2008 году. Данная функция предоставляет процессам собственное представление о системе, тем самым изолируя независимые процессы друг от друга. Другими словами, пространства имен определяют набор ресурсов, которые может использовать процесс (вы не можете взаимодействовать с тем, чего не видите). На высоком уровне они обеспечивают детальное разделение глобальных ресурсов операционной системы, таких как точки монтирования, сетевое взаимодействие, а также инструменты межпроцессного взаимодействия. Сильная сторона пространств имен заключается в том, что они ограничивают доступ к системным ресурсам без ведома работающего процесса. В типичной системе Linux они представлены в виде файлов в каталоге /proc/<pid>/ns:
echo $$
4622
ls /proc/$$/ns -al
total 0 dr-x--x--x 2 cryptonite cryptonite 0 Jun 29 15:00 . dr-xr-xr-x 9 cryptonite cryptonite 0 Jun 29 13:13 .. lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 net -> 'net:[4026532008]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 time -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 user -> 'user:[4026531837]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 uts -> 'uts:[4026531838]'
Когда мы запускаем новый процесс, все пространства имен наследуются от его родителя:
/bin/zsh
# father PID verification ╭─cryptonite@cryptonite ~ ╰─$ ps -efj | grep $$ crypton+ 13560 4622 13560 4622 1 15:07 pts/1 00:00:02 /bin/zsh ╭─cryptonite@cryptonite ~ ╰─$ ls /proc/$$/ns -al total 0 dr-x--x--x 2 cryptonite cryptonite 0 Jun 29 15:10 . dr-xr-xr-x 9 cryptonite cryptonite 0 Jun 29 15:07 .. lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 net -> 'net:[4026532008]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 time -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 user -> 'user:[4026531837]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 uts -> 'uts:[4026531838]'
Пространства имен создаются с помощью системного вызова clone с одним из следующих аргументов:
CLONE_NEWNS: Создать новое пространство имен MNT.
CLONE_NEWUTS: Создать новое пространство имен UTS.
CLONE_NEWIPC: Создать новое пространство имен IPC.
CLONE_NEWPID: Создать новое пространство имен PID.
CLONE_NEWNET: Создать новое пространство имен NET.
CLONE_NEWUSER: Создать новое пространство имен USR.
CLONE_NEWCGROUP: Создать новое пространство имен cgroup.
Пространство имен также можно создать с помощью системного вызова unshare. Разница между clone и unshare заключается в том, что clone порождает новый процесс внутри нового набора пространств имен, а unshare перемещает текущий процесс внутрь нового набора пространств имен (отменяет совместное использование текущих). Если мы представим пространства имен как блоки для процессов, содержащих некоторые абстрактные глобальные системные ресурсы, то преимущество этих блоков заключается в том, что вы можете добавлять и удалять данные из одного блока, и это не повлияет на содержимое других блоков. Или, если процесс A в блоке (наборе пространств имен) сойдет с ума и решит удалить всю файловую систему или сетевой стек в этом блоке, это не повлияет на абстракцию самих ресурсов, предоставляемых процессу B, помещенному в другой блок. Более того, пространства имен могут предоставить расширенную изоляцию, тем самым позволив процессам A и B совместно использовать некоторые системные ресурсы (например, совместно использовать точку монтирования или сетевой стек). Пространства имен часто используются, когда ненадежный код должен быть выполнен на данном узле без ущерба для операционной системы хоста. Платформы для соревнований по программированию, такие как Hackerrank, Codeforces и Rootme, используют среды с пространством имен для безопасного выполнения и проверки кода участников, не подвергая риску свои серверы. Поставщики PaaS, такие как Google Cloud Engine, используют среды с пространством имен для запуска нескольких пользовательских сервисов (например, веб-серверов, баз данных и т.д.) на одном и том же оборудовании, без возможности вмешательства этих сервисов в общую систему. Таким образом пространства имен можно рассматривать как полезные средства для эффективного совместного использования ресурсов. Другие технологии, такие как Docker или LXC, также используют пространства имен как средство изоляции процессов. Эти технологии помещают процессы в изолированные среды, называемые контейнерами. Например, запуск процессов в контейнерах Docker аналогичен их запуску на виртуальных машинах. Разница между контейнерами и виртуальными машинами заключается в том, что контейнеры совместно используют ядро ОС хоста, что делает их значительно легче виртуальных машин, поскольку в них отсутствует аппаратная эмуляция. Такое увеличение общей производительности происходит главным образом за счет использования пространств имен, которые непосредственно интегрированы в ядро Linux. На момент написания оригинальной статьи стабильной версией ядра являлась версия 5.7, которая на тот момент имела семь различных пространств имен:
PID Namespace: Изоляция дерева системных процессов.
NET Namespace: Изоляция сетевого стека хоста.
MNT Namespace: Изоляция точек монтирования файловой системы хоста.
UTS Namespace: Изоляция имени хоста.
IPC Namespace: Изоляция утилит межпроцессного взаимодействия (общие сегменты, семафоры).
USER Namespace: Изоляция идентификаторов пользователей системы.
CGROUP Namespace: Изоляция виртуальной файловой системы Cgroup хоста.
Пространства имен представляют собой атрибуты каждого процесса. Каждый процесс может воспринимать не более одного пространства имен. Другими словами, в любой момент любой процесс принадлежит ровно одному экземпляру каждого пространства имен. Например, когда данный процесс хочет обновить таблицу маршрутов в системе, ядро показывает ему копию таблицы маршрутов того пространства имен, к которому он принадлежит в данный момент. Если процесс запрашивает свой идентификатор в системе, ядро ответит идентификатором процесса в его текущем пространстве имен (в случае вложенного пространства имен). Мы собираемся подробно рассмотреть каждое пространство имен, чтобы понять, какие механизмы операционной системы стоят за каждым из них. Понимание этого поможет нам найти то, что скрывается под капотом сегодняшних контейнерных технологий.
Пространство имён PID: Исторически ядро Linux поддерживало единое дерево процессов. Древовидная структура данных содержит ссылку на каждый процесс, выполняющийся в данный момент в иерархии родитель-ребенок. Она также перечисляет все запущенные процессы в ОС. Данная структура поддерживается в так называемой файловой системе procfs, которая является собственностью работающей системы (то бишь, присутствует только во время работы ОС). Эта структура позволяет процессам с достаточными привилегиями присоединяться к другим процессам, проверять и/или уничтожать их. Она также содержит информацию о корневом каталоге процесса, его текущем рабочем каталоге, дескрипторах открытых файлов, адресах виртуальной памяти, доступных точках монтирования и т. д.:
ls /proc/1/
arch_status coredump_filter gid_map mounts pagemap setgroups task attr cpu_resctrl_groups io mountstats patch_state smaps timens_offsets cgroup environ map_files numa_maps root stat uid_map clear_refs exe maps oom_adj sched statm
При загрузке системы первым процессом, запускаемым в большинстве современных ОС Linux, является systemd (системный демон), который расположен в корневом узле дерева. Его родительским элементом является PID=0, который в свою очередь представляет собой несуществующий процесс в ОС. После основной инициализации данный процесс будет отвечать за запуск других служб/демонов, которые представлены как его дочерние элементы, необходимые для нормального функционирования ОС. Эти процессы будут иметь PID > 1, а PID в древовидной структуре является уникальным. С введением пространства имен PID стало возможным создавать вложенные деревья процессов. Это позволяет процессам, отличным от systemd (PID=1), воспринимать себя как корневой процесс, перемещаясь по вершине поддерева, получая таким образом PID=1 в этом поддереве. Все процессы в одном и том же поддереве также получают идентификаторы относительно пространства имен этого процесса. Это также означает, что некоторые процессы могут иметь несколько идентификаторов в зависимости от количества пространств имен процессов, в которых они находятся. Однако в каждом пространстве имен не более одного процесса может иметь заданный PID (уникальное значение узла в дереве процессов). Другими словами, процесс в новом пространстве имен PID все еще прикреплен к своему родительскому процессу, таким образом являясь частью его родительского пространства имен PID. Эти отношения между всеми процессами можно увидеть в пространстве имен корневого процесса, но в пространстве имен вложенного процесса они не видны. Это означает, что процесс в пространстве имен вложенного процесса не может взаимодействовать со своим родителем или любым другим процессом в пространстве имен верхнего процесса. Это связано с тем, что, находясь на вершине нового пространства имен PID, процесс воспринимает свой PID как единицу, а перед единицей ничего другого быть не может:

В ядре PID представлен в виде структуры. Внутри мы можем найти пространства имен, частью которых является процесс, в виде массива структуры upid:
struct upid {
int nr; /* the pid value */
struct pid_namespace *ns; /* the namespace this value
* is visible in */
struct hlist_node pid_chain; /* hash chain for faster search of PIDS in the given namespace*/
};
struct pid {
atomic_t count; /* reference counter */
struct hlist_head tasks[PIDTYPE_MAX]; /* lists of tasks */
struct rcu_head rcu;
int level; // number of upids
struct upid numbers[0]; // array of pid namespaces
};
Чтобы создать новый процесс внутри нового пространства имен PID, необходимо вызвать системный вызов clone() со специальным флагом CLONE_NEWPID. В то время как другие пространства имен, обсуждаемые ниже, также могут быть созданы с помощью системного вызова unshare(), пространство имен PID может быть создано только во время запуска нового процесса с помощью системных вызовов clone() или fork():
sudo unshare --pid /bin/bash
bash: fork: Cannot allocate memory [1]
ls
bash: fork: Cannot allocate memory [1]
Что в данном случае произошло? Кажется, что оболочка застряла между двумя пространствами имен. Это связано с тем, что unshare не входит в новое пространство имен после выполнения (вызов execve()). Текущий процесс unshare вызывает системный вызов unshare, создавая новое пространство имен pid, но текущий процесс unshare не находится в новом пространстве имен pid. Процесс B создает новое пространство имен, но сам процесс B не будет помещен в это новое пространство имен. Туда попадут только подпроцессы процесса B. После создания пространства имен программа unshare выполнит /bin/bash. Затем /bin/bash создаст несколько новых подпроцессов для выполнения некоторых задач. Эти подпроцессы будут иметь PID относительно нового пространства имен, и когда эти процессы завершатся, они завершат работу, оставив пространство имен без PID=1. Ядру Linux не нравится, когда у пространства имен PID отсутствует процесс PID=1 внутри. Поэтому, когда пространство имен остается пустым, ядро отключает некоторые механизмы, связанные с распределением PID внутри этого пространства имен, что приводит к продемонстрированной ранее ошибке. Вместо этого мы должны сообщить программе unshare о создании нового процесса после того, как будет создано пространство имен. Тогда этот новый процесс будет иметь PID=1 и начнет выполнять заданную программу оболочки. Таким образом когда подпроцесс /bin/bash выходит из пространства имен, всё равно будет существовать процесс с идентификатором PID=1:
sudo unshare --pid --fork /bin/bash
echo $$
1
ps
PID TTY TIME CMD 7239 pts/0 00:00:00 sudo 7240 pts/0 00:00:00 unshare 7241 pts/0 00:00:00 bash 7250 pts/0 00:00:00 ps
Но почему наша оболочка не имеет PID 1, когда мы используем программу ps? И почему мы все еще видим процесс из корневого пространства имён? Программа ps использует виртуальную файловую систему procfs для получения информации о текущих процессах в системе. Эта файловая система монтируется в каталог /proc. Однако в новом пространстве имен данная точка монтирования описывает процессы из корневого пространства имен PID. Есть несколько способов того, как этого можно избежать:
# Создание нового пространства имен монтирования и последующее монтирование внутри него нового procfs:
sudo unshare --pid --fork --mount /bin/bash
mount -t proc proc /proc
ps
PID TTY TIME CMD 1 pts/2 00:00:00 bash 9 pts/2 00:00:00 ps
# Использование оболочки unshare с флагом --mount-proc, который проделывает то же самое:
sudo unshare --fork --pid --mount-proc /bin/bash
ps
PID TTY TIME CMD 1 pts/1 00:00:00 bash 8 pts/1 00:00:00 ps
Пространство имён NET: Сетевое пространство имен ограничивает вид процесса хост-сети. Оно позволяет процессу иметь свое собственное сетевое пространство, отличное от сетевого стека хоста (набор сетевых интерфейсов, правил маршрутизации и т.д.). Давайте создадим новое сетевое пространство имен и проверим работу сетевого стека в рамках этого пространства:
sudo unshare --net /bin/bash
ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
ip route
Error: ipv4: FIB table does not exist. Dump terminated
iptables --list-rules
-P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT
Мы видим, что весь сетевой стек процесса изменился. Остался только интерфейс loopback, который также не работает. Другими словами, этот процесс недоступен в рамках сетевого взаимодействия. И это проблема, не так ли? Зачем нам нужен практически изолированный сетевой стек, если мы не можем общаться через него со всеми остальными? Вот иллюстрация ситуации:
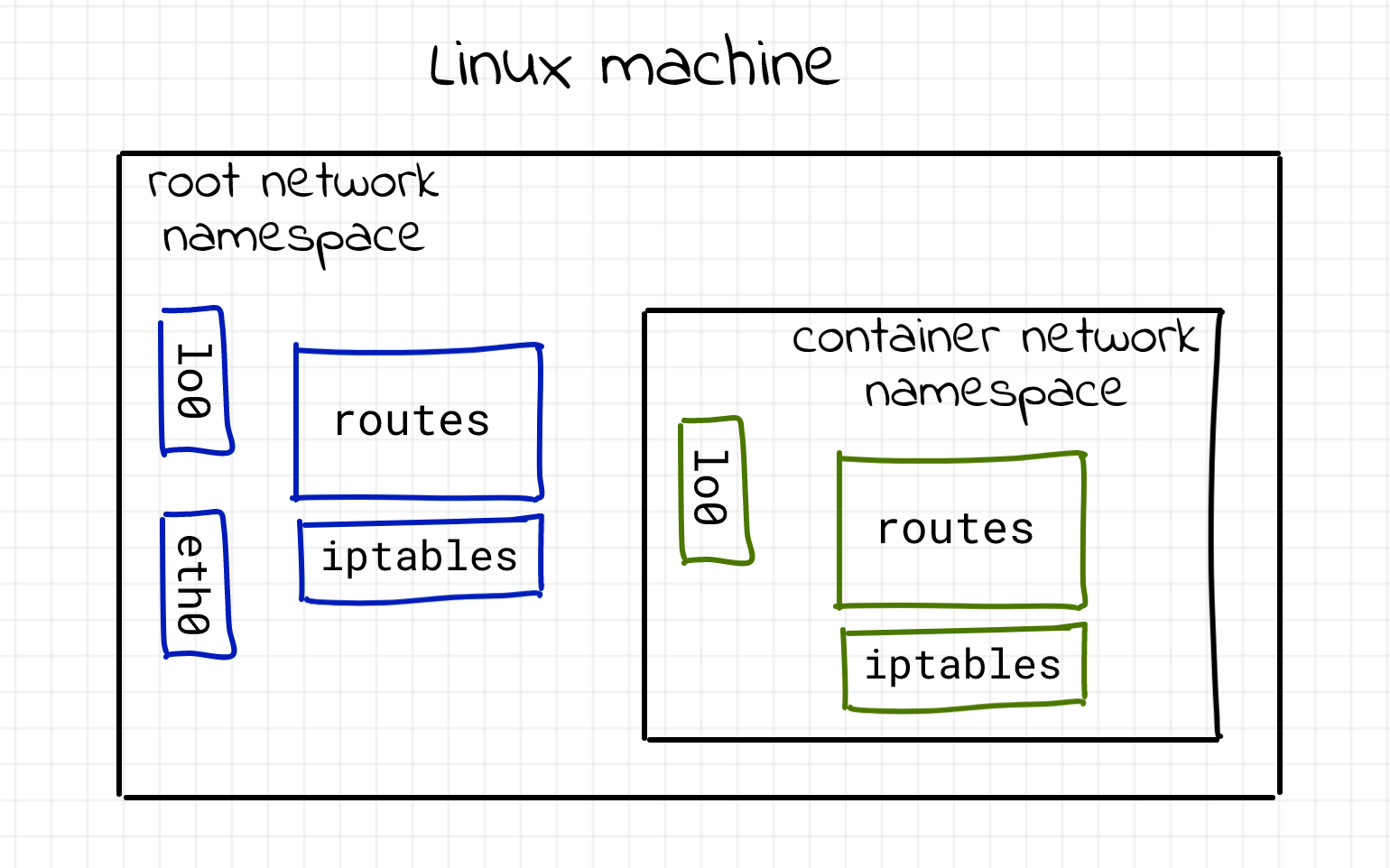
Поскольку обычно мы хотим иметь возможность каким-либо образом взаимодействовать с данным процессом, нам необходимо предоставить способ соединения нескольких сетевых пространств имен между собой. Чтобы сделать процесс внутри нового сетевого пространства имен доступным из другого сетевого пространства имен, необходима пара виртуальных интерфейсов. Эти два виртуальных интерфейса поставляются с виртуальным кабелем. Поэтому, если мы хотим соединить пространство имен (скажем, N1) с другим таким же пространством имен (например, N2), мы должны поместить один из виртуальных интерфейсов в сетевой стек N1, а другой – в сетевой стек N2:

Давайте построим функциональную сеть между различными сетевыми пространствами имен. Важно отметить, что существует два типа сетевых пространств имен – именованные и анонимные, однако подробнее об этом мы говорить не будем. Итак, сперва организуем сетевое пространство имен, а затем создадим пару виртуальных интерфейсов:
# Создание сетевого пространства имён и проверка валидности:
sudo ip netns add netnstest
ls /var/run/netns
netnstest
# Проверка того, что наша конфигурация не использовалась ранее:
sudo nsenter --net=/var/run/netns/netnstest /bin/bash
root@cryptonite:/home/cryptonite# ip link
root@cryptonite:/home/cryptonite# exit
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# Создание пары виртуальных сетевых интерфейсов и проверка на наличие:
sudo ip link add veth0 type veth peer name ceth0
ip link | tail -n 4
8: ceth0@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f6:1a:ee:9c:26:0c brd ff:ff:ff:ff:ff:ff
9: veth0@ceth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ae:4d:95:44:ab:39 brd ff:ff:ff:ff:ff:ff
# Помещаем один из интерфейсов в ранее созданное сетевое пространство имен, а другой конец оставим в корневом сетевом пространстве имен:
sudo ip link set ceth0 netns netnstest
ip link
...
9: veth0@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ae:4d:95:44:ab:39 brd ff:ff:ff:ff:ff:ff link-netns netnstest
# Включаем интерфейс, назначаем на него IP-адрес и переходим в созданное пространство имен:
sudo ip link set veth0 up
sudo ip addr add 172.12.0.11/24 dev veth0
sudo nsenter --net=/var/run/netns/netnstest /bin/bash
root@cryptonite:/home/cryptonite# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
8: ceth0@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f6:1a:ee:9c:26:0c brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@cryptonite:/home/cryptonite# ip link set lo up
root@cryptonite:/home/cryptonite# ip link set ceth0 up
root@cryptonite:/home/cryptonite# ip addr add 172.12.0.12/24 dev ceth0
root@cryptonite:/home/cryptonite# ip addr | grep ceth
8: ceth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
inet 172.12.0.12/24 scope global ceth0
Теперь мы можем проверить подключение виртуальных интерфейсов:
# Внутри корневого пространства имён:
ping 172.12.0.12
PING 172.12.0.12 (172.12.0.12) 56(84) bytes of data. 64 bytes from 172.12.0.12: icmp_seq=1 ttl=64 time=0.125 ms 64 bytes from 172.12.0.12: icmp_seq=2 ttl=64 time=0.111 ms ...
# Внутри созданного сетевого пространства имён:
root@cryptonite:/home/cryptonite# tcpdump
17:18:17.534459 IP 172.12.0.11 > 172.12.0.12: ICMP echo request, id 2, seq 1, length 64 17:18:17.534479 IP 172.12.0.12 > 172.12.0.11: ICMP echo reply, id 2, seq 1, length 64 17:18:18.540407 IP 172.12.0.11 > 172.12.0.12: ICMP echo request, id 2, seq 2, length 64 ....
# Попытка проверки наоборот:
root@cryptonite:/home/cryptonite# ping 172.12.0.11
PING 172.12.0.11 (172.12.0.11) 56(84) bytes of data. 64 bytes from 172.12.0.11: icmp_seq=1 ttl=64 time=0.108 ms ...
# Возвращаемся в корневое пространство имён:
sudo tcpdump -i veth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes 17:22:27.999342 IP 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net: ICMP echo request, id 18572, seq 1, length 64 17:22:27.999417 IP 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net: ICMP echo reply, id 18572, seq 1, length 64 17:22:29.004480 IP 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net: ICMP echo request, id 18572, seq 2, length 64
Из фрагмента выше мы узнаем, как можно создать новое сетевое пространство имен и подключить его к корневому пространству имен с помощью соединения типа Pipe. Родительское пространство имен сохранило один из интерфейсов и передало другой дочернему пространству имен. Все, что входит с одной стороны, выходит из другой. Всё как в настоящем сетевом соединении:

Мы рассмотрели как можно изолировать, виртуализировать и подключать сетевые стеки Linux. Имея возможности виртуализации, мы могли бы пойти дальше и создать виртуальную локальную сеть между процессами. И для создания виртуальной локальной сети будет использоваться другая утилита виртуализации Linux – Bridge. Мост Linux ведет себя как настоящий сетевой коммутатор уровня 2 – он пересылает пакеты между интерфейсами, которые подключены к нему, используя таблицу ассоциаций MAC-адресов. Давайте создадим нашу виртуальную локальную сеть:
# Предыдущая конфигурация была удалена. Создаем новую пару сетевых пространств имён:
sudo ip netns add netns_0
sudo ip netns add netns_1
tree /var/run/netns/
/var/run/netns/ ├── netns_0 └── netns_1 ...
sudo ip link add veth0 type veth peer name ceth0
sudo ip link add veth1 type veth peer name ceth1
sudo ip link set veth1 up
sudo ip link set veth0 up
sudo ip link set ceth0 netns netns_0
sudo ip link set ceth1 netns netns_1
Создаем первое соединение для интерфейса -> net_namespace=netns_0:
sudo ip netns exec netns_0 ip link set lo up
sudo ip netns exec netns_0 ip link set ceth0 up
sudo ip netns exec netns_0 ip addr add 192.168.1.20/24 dev ceth0
Создаем ещё одно соединение для интерфейса -> net_namespace=netns_1:
sudo ip netns exec netns_1 ip link set lo up
sudo ip netns exec netns_1 ip link set ceth1 up
sudo ip netns exec netns_1 ip addr add 192.168.1.21/24 dev ceth1
# Создаем Bridge:
sudo ip link add name br0 type bridge
# Назначаем IP-адрес и включаем интерфейс сетевого моста:
ip addr add 192.168.1.11/24 brd + dev br0
sudo ip link set br0 up
# Соединяем созданные сетевые пространства имен в корневом пространстве имен с Bridge:
sudo ip link set veth0 master br0
sudo ip link set veth1 master br0
bridge link show br0
10: veth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 12: veth1@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
# Разрешаем пересылку данных в корневом сетевом пространстве имен, чтобы интерфейс мог пересылать данные между пространствами имен в зависимости от различных политик Iptables (шаг является опциональным):
iptables -A FORWARD -i br0 -j ACCEPT
# Проверяем сетевое соединение в рамках netns_test1 -> netns_0:
sudo ip netns exec netns_1 ping 192.168.1.20
PING 192.168.1.20 (192.168.1.20) 56(84) bytes of data. 64 bytes from 192.168.1.20: icmp_seq=1 ttl=64 time=0.046 ms ...
# Проверяем сетевое соединение в рамках root_namespace -> netns_0:
ip route
... 192.168.1.0/24 dev br0 proto kernel scope link src 192.168.1.11 ...
ping 192.168.1.20
PING 192.168.1.20 (192.168.1.20) 56(84) bytes of data. 64 bytes from 192.168.1.20: icmp_seq=1 ttl=64 time=0.150 ms ...
# Проверяем сетевое соединение в рамках netns_test0 -> netns_1:
sudo ip netns exec netns_0 ping 192.168.1.21
PING 192.168.1.21 (192.168.1.21) 56(84) bytes of data. 64 bytes from 192.168.1.21: icmp_seq=1 ttl=64 time=0.040 ms
Работает. Действительно важно, чтобы виртуальный интерфейс имел соответствующие разрешения на пересылку пакетов в текущем сетевом стеке. Чтобы не путаться с правилами Iptables, можно повторить эту процедуру в отдельном сетевом пространстве имен, где таблица правил будет пустой по умолчанию. Теперь давайте подключим локальную сеть к Интернету:
# Пытаемся достучаться до узла в сети Интернет:
sudo ip netns exec netns_1 ping 8.8.8.8
ping: connect: Network is unreachable
sudo ip netns exec netns_1 ip route
192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.21
# Отсутствует маршрут для интерфейса хоста. Нет разрешения в рамках ARP-таблицы и межсетевого взаимодействия. Но мы можем сделать Bridge шлюзом по умолчанию для обоих пространств имен и позволить ему пересылать весь трафик в верхнее сетевое пространство имен:
sudo ip -all netns exec ip route add default via 192.168.1.11
sudo ip -all netns exec ip route
netns: netns_1 default via 192.168.1.11 dev ceth1 192.168.1.0/24 dev ceth1 proto kernel scope link src 192.168.1.21 netns: netns_0 default via 192.168.1.11 dev ceth0 192.168.1.0/24 dev ceth0 proto kernel scope link src 192.168.1.20
# Пробуем ещё раз:
ip netns exec netns_0 ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. ^C --- 8.8.8.8 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, ...
# И ещё один момент. Внешний мир не знает о нашей локальной сети, как и сам хост, поэтому нам нужно добавить ещё одно правило:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
sudo ip netns exec netns_0 ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=61 time=11.5 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=61 time=12.5 ms
Обратите внимание, что правила Iptables хоста должны быть хорошо настроены, потому что плохая конфигурация может привести к плохим последствиям. Кроме того, без MASQUERADE пакеты покидали бы хост с его внутренним IP-адресом, который известен только этому хосту. Шлюз в локальной сети хоста не имеет понятия, как присоединиться к локальной сети созданного ранее моста.
Пространство имён MNT: Пространства имен монтирования являются мощным инструментом для создания древовидных файловых систем для каждого процесса. Linux поддерживает структуру данных для всех различных файловых систем, смонтированных в ней. Эта структура является атрибутом для каждого процесса, а также для каждого пространства имен. Она включает в себя информацию о том, какие разделы диска смонтированы, где они были смонтированы, а также сообщает о типе монтирования (RO/RW):
cat /proc/$$/mounts
sysfs /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0 proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0 ...
Пространства имен Linux позволяют копировать эту структуру данных и передавать её копию различным процессам. Таким образом эти процессы могут изменять структуру (монтировать и размонтировать), не влияя на точки монтирования друг друга. Предоставляя различные копии файловой системы, ядро изолирует список точек монтирования, которые видны процессам в рамках указанного пространства имен. Пространство имен монтирования, которое было определено, также может позволить процессу изменить свой корень – поведение, похожее на системный вызов chroot. Разница в том, что chroot привязан к текущей структуре файловой системы, и все изменения (монтирование, размонтирование) в среде с корнем, который был переопределен, повлияют на всю файловую систему. С пространствами имен монтирования это невозможно, поскольку вся структура виртуализирована, тем самым обеспечивая полную изоляцию исходной файловой системы с точки зрения событий монтирования и размонтирования:
readlink /proc/$$/ns/mnt
mnt:[4026531840]
Ниже представлен общий концепт пространства имен монтирования:

Попробуем организовать своё пространство имен монитрования:
# Создание пространства имен монтирования:
sudo unshare -m /bin/bash
root@cryptonite:/home/cryptonite# mount -t tmpfs tmpfs /mnt
root@cryptonite:/home/cryptonite# touch /mnt/hello
# Во втором терминале или в отдельном пространстве имен:
ls -al /mnt
total 8 drwxr-xr-x 2 root root 4096 Feb 9 19:47 . drwxr-xr-x 20 root root 4096 Jun 8 23:24 .
Из примера выше видно, что процессы в изолированном пространстве имен монтирования могут создавать различные точки монтирования, а также файлы в них, не влияя при этом на родительское пространство имен монтирования. Каталоги монтирования и размонтирования отражают файловую систему ОС. В классической ОС Linux эта система представлена в виде дерева. Как показано на рисунке выше, создание различных пространств имен монтирования технически приводит к созданию виртуальных древовидных структур для каждого процесса. Эти структуры могут быть общими. Согласно документации Linux:
Главное преимущество поддревовидных структур общего назначения заключается в возможности автоматического контролируемого распространения событий монтирования и размонтирования между пространствами имен. Это означает, например, что монтирование оптического диска в одном пространстве имен может вызвать монтирование этого диска во всех других пространствах имен.
Древовидные структуры общего назначения в основном, состоят из маркировки каждой точки монтирования тегом, сообщающим, что произойдет, если мы добавим или удалим точку монтирования, которая присутствует в разных пространствах имен монтирования. Добавление или удаление точек монтирования запускает событие, которое распространяется в так называемых одноранговых группах (дочерние пространства имен монтирования). Одноранговая группа представляет собой набор vfsmounts (точек монтирования виртуальной файловой системы), которые распространяют события монтирования и размонтирования друг на друга. Существует четыре типа монтирования. Давай рассмотрим их поподробнее:
MS_SHARED: Данная точка монтирования разделяет между собой события монтирования и размонтирования с иными точками монтирования, которые являются членами группы одноранговых узлов. Когда точка монтирования добавляется или удаляется, это изменение распространяется на всех, так что монтирование или размонтирование также будет иметь место в каждой из точек монтирования. Распространение также происходит в обратном направлении, поэтому события монтирования и размонтирования также будут распространяться на эту точку монтирования.
MS_PRIVATE: Данный тип является обратной стороной общей точки монтирования. Точка монтирования не распространяет события ни на какие одноранговые узлы и не получает события распространения от каких-либо одноранговых узлов.
MS_SLAVE: Данный тип находится на полпути между двумя представленными выше типами монтирования. У данного типа монтирования есть главное – общая группа одноранговых узлов, члены которой распространяют события монтирования и размонтирования на этот тип монтирования. Однако данный тип не распространяет события на главную группу одноранговых узлов.
MS_UNBINDABLE: Данный тип не получает и не пересылает никаких событий и этот же тип не может быть примонтирован.
Теперь разберем несколько примеров по монтированию:
# Создаём точку монтирования и отмечаем её как общую для группы одноранговых узлов (дочерними пространствами имен):
mkdir X
sudo mount --make-shared -t tmpfs tmpfs X/
# Вводим новое пространство имен:
sudo unshare --mount /bin/bash
root@cryptonite:/home/cryptonite#
# Создаем ещё одну точку монтирования в родительском пространстве имен монтирования:
mkdir Y
mount --make-shared -t tmpfs tmpfs Y/
root@cryptonite:/home/cryptonite/X# mount | grep Y
tmpfs on /home/cryptonite/X/Y type tmpfs (rw,relatime)
# Снова возвращаемся в корневое пространство имен:
mkdir Z
sudo mount --make-private -t tmpfs tmpfs Z
mount | grep Z
tmpfs on /home/cryptonite/test/Z type tmpfs (rw,relatime)
# Возвращаемся в дочернее пространство имен:
root@cryptonite:/home/cryptonite/test# mount | grep Z
И здесь мы ничего не увидим, поскольку точка монтирования, помеченная как частная из родительского пространства имен, отсутствует в дочернем пространстве имен монтирования. Информацию о различных типах монтирования в текущем пространстве имен конкретного процесса можно найти по пути /proc/self/mountinfo:
╭─cryptonite@cryptonite ~ ╰─$ cat /proc/self/mountinfo | head -n 3 24 31 0:22 / /sys rw,nosuid,nodev,noexec,relatime shared:7 - sysfs sysfs rw 25 31 0:23 / /proc rw,nosuid,nodev,noexec,relatime shared:15 - proc proc rw 26 31 0:5 / /dev rw,nosuid,noexec,relatime shared:2 - devtmpfs udev rw,size=8031108k,nr_inodes=2007777,mode=755
Послесловие: Это первая из двух подчастей по работе пространств имен в Linux. В следующей подчасти мы рассмотрим оставшиеся пространства имен, а также то, как это должно работать воедино.