Udemy: Spark Starter Kit, part 1
How to DWH with Python, @bryzgaloffSpark vs Hadoop: who wins?
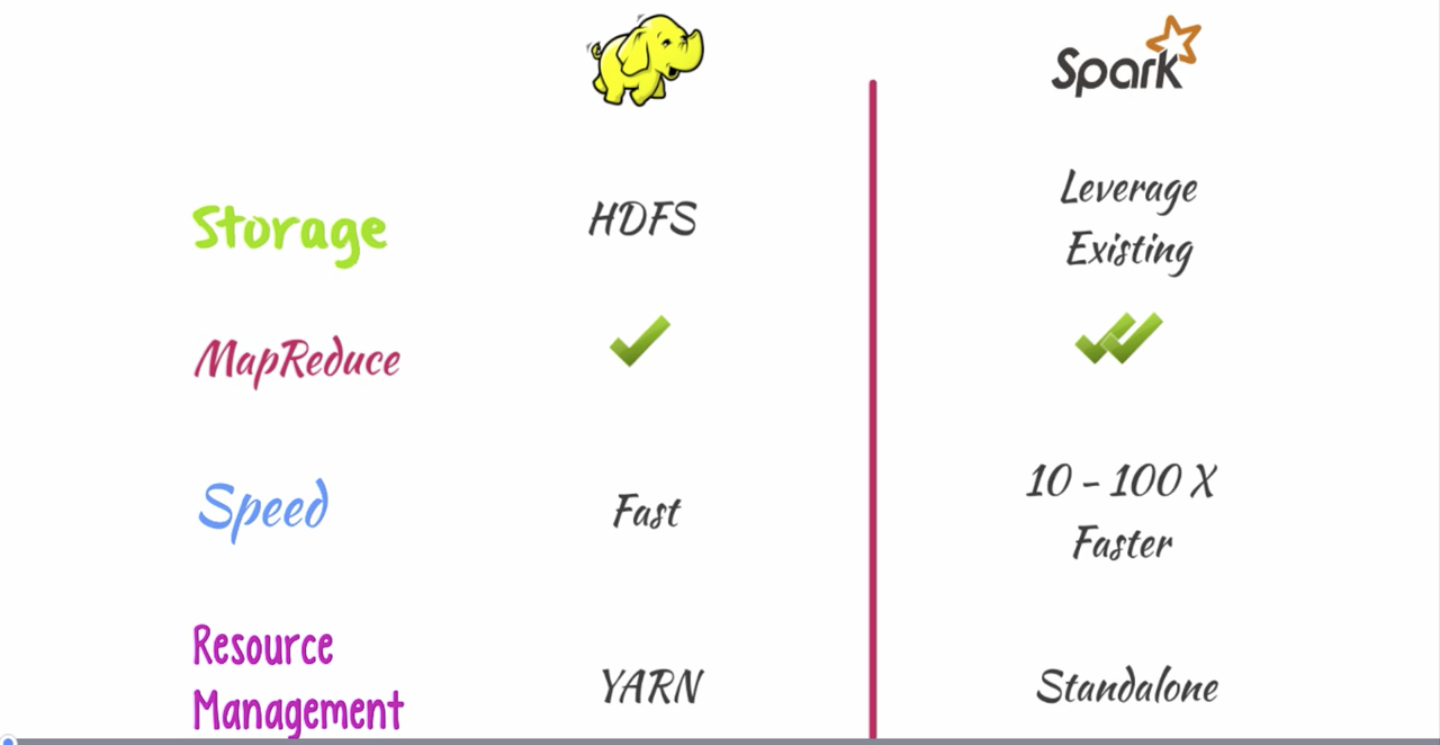
Hadoop = HDFS + MapReduce. Spark is not a replacement for Hadoop.
In particular, Spark does not come with its own storage: it leverages existing one like HDFS, S3, etc. Distributed filesystem are preferred to accelerate data distribution.
Spark is based on MapReduce programming model but advances Hadoop's implementation with a faster one.
Acceleration compared to Hadoop is 10–100 times. Spark shines when used for iterative processing, e.g. logistic regression, graph algorithms, page ranking. Spark is an ideal choice for machine learning.
Spark provides its own resources manager but can lean on Hadoop's YARN.
Spark and Hadoop clusters can be separate ones. But data will have to be copied from HDFS when a job is executed. This disables data locality advantage. While running Spark on Hadoop cluster reduces costs and allows leveraging HDFS and YARN.
Challenges Spark tries to address
Spark solves inefficiencies in two areas: iterative machine learning and interactive data mining.
Reason of Hadoop's weakness with iterative processing is a need to dump intermediate results to a disk. The more intermediate data is read and iterations are run, the slower the execution is. Spark keeps intermediate results in memory. (However, simple solution is complex to implement. Read about RDDs below.)
Requirements for interactive data mining:
— Rich set of available functions to perform on a dataset. Bare Hadoop forces user to fit all logic into map and reduce steps while Spark provides higher level of abstraction.
— Caching intermediate results in memory to perform operations on them later. User may tell Spark to keep a particular set of data in memory. Hadoop has to load data on every data mining attempt.
How Spark is faster than Hadoop?
Spark's in-memory computing approach is not revolutionary. All software always tries to cache data in memory. What Spark does is it offers in-memory computing at a distributed scale. However, great challenge here is fault-tolerance.
Spark translates user's code into a logical plan that is compiled into physical plan and then translated into a set of tasks to be executed. In contrast, Hadoop does not inspect a MapReduce job written by a user and does not optimise it as Spark engine does.
The execution engine of Spark operates a job as a direct acyclic graph, DAG. Important features here are absence of cyclic relations and exactly once execution of every task.
Spark keeps track of all operations and transformations performed on a dataset using a revolutionary concept of RDDs (resilient distributed datasets).
Summary of Spark's advantages:
— Distributed in-memory computing.
— Optimisations of execution engine.
— RDDs.
The need for RDD
RDD is important for Spark because it is how Spark achieves fault tolerance.
Fault-tolerance is complex when computations are in-memory. In case of Hadoop if a node fails when executing a single step of a multistep MapReduce job then a new node is spun up. The intermediate output used as input by the failed node could be read from HDFS so that the new worker can perform the last failed transformation only.
Spark nodes read data directly from memory of a node that was executing the previous step. If the upstream source node goes down, produced data becomes unavailable.
To keep produced datasets resilient to nodes failures, Spark keeps track of all the transformations applied to a dataset. This way Spark preserves data lineage that allows it to know how to recover in case of a node failure. Simple schema for an example:
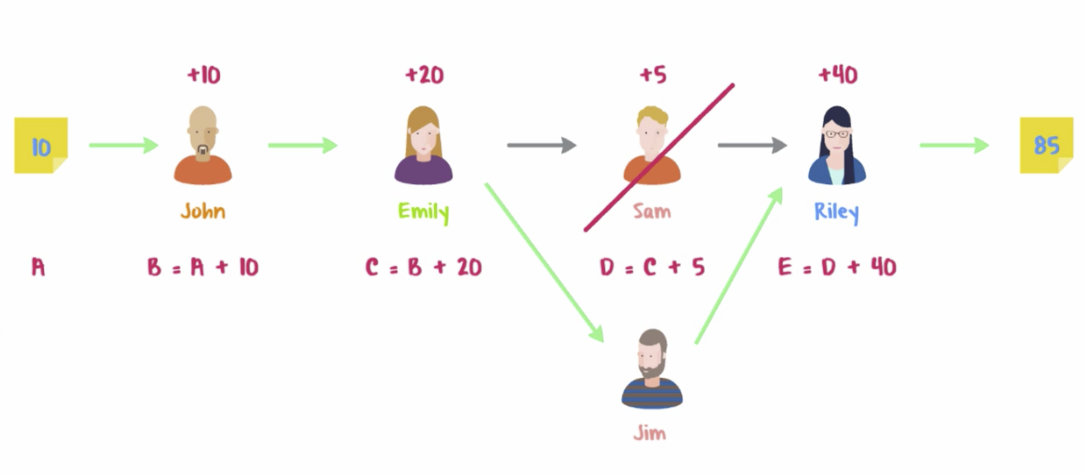
You cannot operate on data in Spark without relying on RDDs. Every operation on a dataset in Spark produces a new RDD.
What is RDD?
Simple Spark Scala code example to find HDFS error:
# run in Spark Shell: spark-shell --master spark://node1:7077
val logfile = sc.textFile("hdfs://node1:8020/user/osboxes/log-dataset")
val errors = logfile.filter(_.startsWith("ERROR"))
val hdfs = errors.filter(_.contains("HDFS"))
hdfs.count()
The code defines an obvious lineage:

When Spark reads data, it groups input elements into partitions. If a single partition fails, Spark knows how to recover it reproducing its lineage. This makes dataset resilient. Different partitions of a single dataset may be processed on separate nodes. This makes dataset distributed.
Spark tracks lineage by creating an RDD on every operation.
RDD represents an immutable collection of elements that can be operated in parallel. Parallelisation is achieved through partitioning. Immutability means: once RDD is created, its elements cannot be changed. The only way to change elements is to apply another function on an RDD. This will result in a new RDD.
Internal RDD properties:
— List of partitions.
— Function that produced an RDD (e.g. filter). Important note: function is applied to all elements. Spark does not allow fine-grained operation.
— List of dependencies.
What RDD is not
Firstly, RDD is not constantly stored in memory. Once Spark job is rerun, Spark will read the source data and apply all the operations once again. The main function of RDD is to keep track of all operations and not keep the produced data itself in memory.
Due to implementation some of the RDDs may be stored in memory. And also Spark allows to explicitly mark RDDs as cached to be kept in memory.
Secondly, actual execution plan is not the same as logical plan. Spark does not physically create every single RDD produced by its flow. Spark may pipeline multiple operations (e.g. filter + map) to a single source RDD and produce a single resulting RDD without explicitly calculating intermediate ones.
Extras
Highly recommended: read through official Glossary to get basic understanding of Spark cluster components.
Stay tuned for the next part of Spark Starter Kit course summary! Subscribe: @pydwh