UUID не один на самом деле
Vanya KhodorМы не будем вдаваться в детали того, какой он, этот самый идеальный primary key, но, думаю, все согласятся, что он должен быть уникальным. Иначе в чём смысол?

Когда мы говорим про создание уникальных идентификаторов в бд, первым делом можно подумать про использование SEQUENCE (или его аналог). Но с ним есть некоторые проблемы:
- получение новых значений через SEQUENCE приводит к записям на диск. Это с одной стороны хорошо, т.к. вы можете быть уверены, что если одно значение было выдано, то оно больше не повторится. С другой стороны это может просаживать перф.
- если результат SEQUENCE был получен, но не закоммичен (в рамках транзакции), то вы всё равно его больше не получите. Хотя иногда закладываются на отсутствие "дыр" в последовательностях значений id.
- SEQUENCE не реплицируется. Т.е. если вы получили значение и вставили с ним строку, после чего мастер переехал и вы начинаете вставлять данные уже с другого хоста, то он вполне может пойти повторять уже используемые значения.
- он локальный. В рамках разработки распределённых систем это, очевидно, может приводить к проблемам.
Однажды умные дядьки сели и подумали, как должен выглядеть "идеальный" способ генерации id:
- он должен уметь в децентрализованность, но при этом сохранять достаточный уровень уникальности.
- он должен быть небольшим по размеру.
- он должен быть удобным для различных операций вроде сортировки, хеширования и т.д. Multi purpose в общем.
Так-сяк пришли к UUID.
Далее будет вольный перевод стандарта UUID с моими комментариями.
UUIDv4 и UUIDv7
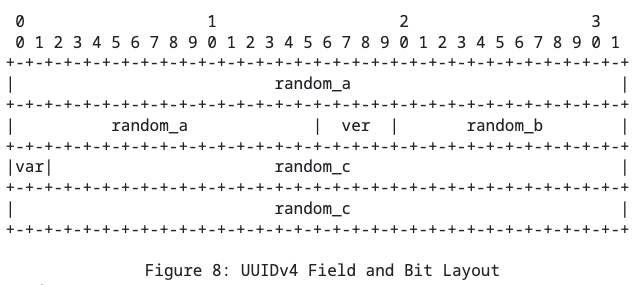
Де-факто стандартом индустрии сейчас является UUIDv4:
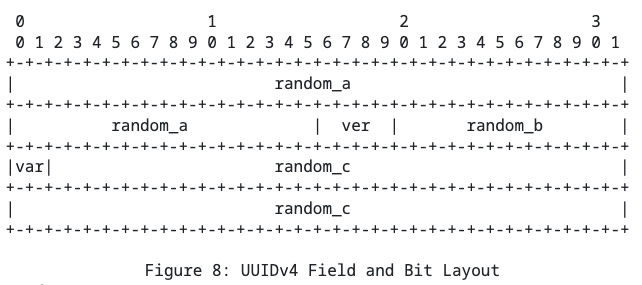
Сразу оговорим поля ver и var, которые встречаются во всех версиях UUID.
ver используется для обозначения используемой версии UUID. Сейчас их 9. Маппинг можно найти тут.
Если вы возьмёте из вашей бд выборку в 100 случайных UUID (одной версии), то при скролле можете заметить, что одна циферка не меняется (ver). Для UUIDv4 там будет 4. В полотне случайных данных это выглядит необычно.
var -- служебные биты, которые говорят, каким образом интерпретировать остальные биты в UUID. Маппинг тут.
UUIDv4 почти полностью забивается случайными числами. В целом выглядит как довольно рабочее решение, которое всё же имеет две проблемы:
- т.к. по факту UUIDv4 есть случайное число, то при вставке элементов с таким id в индексы, вы затрагиваете случайные страницы/блоки, что триггерит много записей на диск (и не только на main тачке, но и у реплик). Хотя возможно было бы логично, если бы значения, вставляемые подряд, могли лежать рядом (для лучшей локальности).
- рандом он на то и рандом, что может быть всё что угодно. Например, два UUID совпадут. И мы даже встречали такое в проде. Причём это была не ошибка уровня "такой id уже существует, так что поретраим и сгенерируем новый", а уровня "старые данные уже уехали в холодное хранилище, а новые туда выгрузить не можем, потому что спустя два года сгенерировался существующий id".
Потому умные ребята покумекали и придумали UUIDv7:
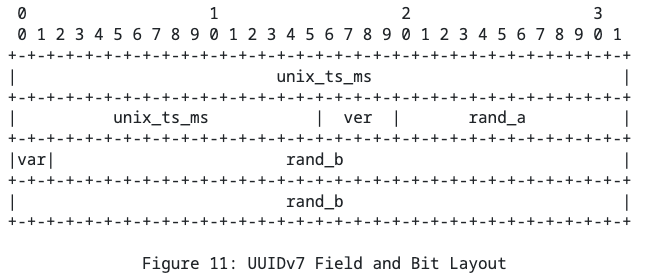
Тут в начале лежит таймстемп, а дальше рандомные значения. Почему это решает проблемы:
- теперь UUID'ы, сгенерированные рядом во времени, имеют близкие префиксы, что означает, что они близки друг другу по значениям. А это способствует локальности данных в индексах.
- спустя долгое время (хотя и спустя милисекунды) вы не можете сгенерировать существующий id по построению. Таймстемп уже изменился, а это значит, что значение точно будет другое.
При желании можно оторвать ещё некоторые биты от секции с рандомными значениями, чтобы заполнить их чем-то, чтобы гарантировать уникальность ещё больше (например класть туда каунтер/дробные значения милисекунд).
Юзайте UUIDv7, короче.
Точнее, юзайте UUIDv7, если вам неважно, что через него могут раскрыть время генерации.
Конечно, UUIDv7 тоже может давать дубли, если вы генерируете id параллельно на разных машинках. Тут предлагается учитывать некоторый node_id вашего сервера при генерации UUID (но не MAC адрес). Ни в коем случае не стоит делать глобальную точку синхронизации id:
- во-первых, это single point of failure в вашей системе;
- во-вторых, это противоречит требованию к UUID про корректность работы в децентрализованных системах.
Другие ребята
UUIDv1
Иногда от PK ожидают некоторую монотонность. UUID первой версии немного пытается во что-то подобное. Выглядит он примерно так:
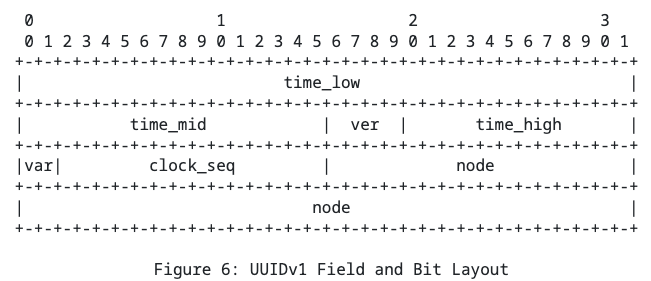
Проблемы с UUIDv1 пришли откуда не ждали (или ждали). Вот они слева направо:
- обычно сравнение UUID в базах данных это обычный memcmp. И в реализациях часто использовался не тот endian, который использовался базами данных. Потому с одной стороны монотонность есть. С другой стороны она не очень помогает быть монотонным.
- в поле node предлагается записывать MAC адрес хоста, на котором происходит генерация, что не очень безопасно. Злодей может определить, на какой машине был создан id и что-нибудь натворить. Поэтому иногда в младшие 6 битов кладут не MAC адрес, а просто случайные биты.
Из интересного тут можно ожидать проблем, которые связаны с дрифтом часов на машинке, генерирующей UUID. Т.е. вот у вас часы немного откатились назад, остальные биты заполняются детерминированно, потому вы спокойно можете получить уже существующий id. Для решения таких проблем есть поле clock_seq:
If the clock is set backwards, or might have been set backwards (e.g., while the system was powered off), and the UUID generator can not be sure that no UUIDs were generated with timestamps larger than the value to which the clock was set, then the clock sequence has to be changed. If the previous value of the clock sequence is known, it can just be incremented; otherwise it should be set to a random or high-quality pseudo-random value.
Короче подпёрли костылём. Изначально это значение должно быть инициализировано случайным числом. И в целом не должно иметь корреляции с node значением.
UUIDv2
Про UUIDv2 в спецификации по ссылке есть буквально пару слов. По факту это UUIDv1, который вместо случайного числа в clock_seq хранит какое-то значение, характерное текущей системе (возможно id пользователя).
UUIDv3
UUIDv3 -- аналог md5 хеша. У них обоих как раз по 128 бит (за тем исключением, что ver/var заменяют 6 битов в изначальном хеше).

Нужен для того, чтобы кодировать именные сущности (домен, сайт, текст, имя юзера). Есессна он стабилен для одних и тех же входных данных.
Обычно генерируется не только из данных, а с помощью некоторый соли (называется namespace; изначальный ключ просто с ним конкатенируется и только тогда хешируется). Понятно, что тогда UUID одинаковых ключей для разных неймспейсов будут разными (что и требуется стандартом), но зачем вся концепция неймспейсов существует, не очень понятно. Может чтобы была возможность разделять ключи по доменам.
Но вообще, когда речь идёт про подобную операцию (получение UUID из текстовых данных), то рекомендуется использовать 5-ю версию.
UUIDv5
Тут меняется только алгоритм хеширования: SHA-1.
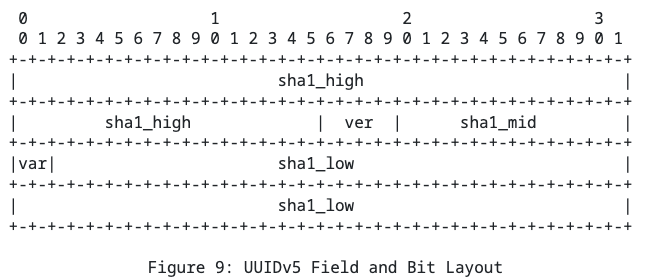
Вопрос выбора между UUIDv3 vs UUIDv5 это выбор между md5 vs SHA-1. Что вам важнее, скорость (md5) или безопасность (SHA-1)?
Вы можете заметить, что SHA-1 вообще-то генерирует 160 битов информации, а в UUID их только 128. Ну да. Лишние 32 отбрасываются.
Конечно, вы можете захотеть считать ваш UUID с помощью других хеш-функций SHA-семейства. Но для этого не рекомендуется использовать UUIDv5. Лучше возьмите восьмую версию (о которой чуть ниже).
UUIDv6
Примерно в этом месте вспомнили про проблемы с порядком битов в UUIDv1 и решили это дело поправить. UUIDv6 -- UUIDv1, в котором что-то переупорядочили, чтобы как раз исправить вот эту проблему с не подходящим порядком битов в UUID.
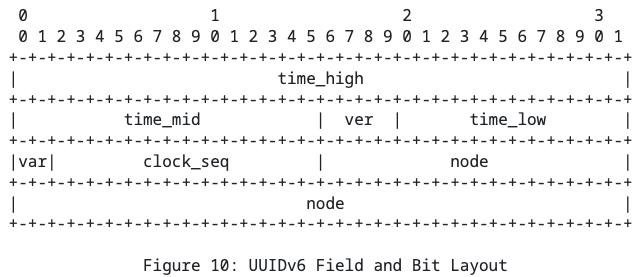
Его рекомендуется использовать только там, где уже используется UUIDv1 на замену последнему. Если вы хотите брать какое-то аналогичное решение для вашего нового сервиса/бдшки, то сразу идите за UUIDv7.
clock_seq и node теперь рекомендуется заполнять рандомно.
UUIDv8
Восьмая версия это пранк. Сейчас покажу:
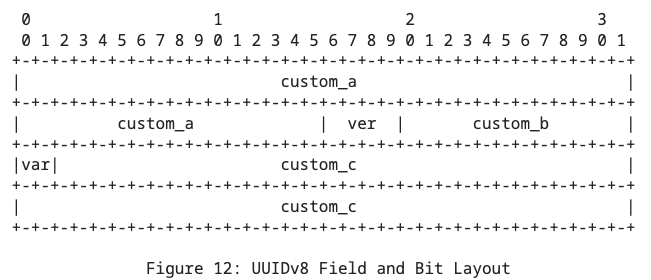
Да. Вы всё правильно поняли. Тут всё кастомное.
Этот формат существует для специфических юзкейсов, и единственное требование к нему -- корректно заполнить var/ver. Всё остальное up2u. Поэтому сюда можно пихать SHA-256 или любой другой алгоритм хеширования. Можете хоть все биты заполнить единицами: стандарт не требует поддерживать уникальность.
Про применимость стандарт говорит следующее:
- реализация хочет уметь поддерживать дополнительную информацию в UUID, которую не предполагается хранить в других версиях;
- использования других версий невозможно в силу специфических ограничений системы.
Nil UUID
Nil UUID -- UUID, у которого все биты равны нулю:
00000000-0000-0000-0000-000000000000
Может быть удобен для сообщения о том, что других подходящих UUID-значений нет. Своего рода std::nullopt.
Max UUID
Максимальный UUID наоборот: все биты равны 1:
FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF
Его предлагается использовать как сентинел для ситуаций, где подобное нужно, но при этом отсутствует другое подходящее значение.
Другие имплементации
Есть и нестандартные имплементации концепции UUID, которые появились от невозможности стандарта решить все проблемы в какой-то момент. Примеры можно найти также в стандарте.
Там же можно найти много других моментов про реализацию. Например, про best practice работы с таймстемпами, генерацией случайных данных, счётчиками, хеширование и прочее. Можно упороться и почитать.