TryOnDiffusion: A Tale of Two UNets
https://t.me/reading_ai, @AfeliaN🗂️ Project Page
📄 Paper
🗓 Date: 14 Jun 2022
Main idea

- Motivation: the main challenge is to preserve both effective pose and shave variation and garment details.
- Solution: TryOnDiffusion - a diffusion-based architecture that unifies two UNets . As an input TryOnDiffusion takes two images - a target person image and an image of a garment worn by another person. As output the target person wearing the garment is obtained. It works in high resolution (1024 x 1024) that can work for diverse body shapes while preserving garment details.
Pipeline
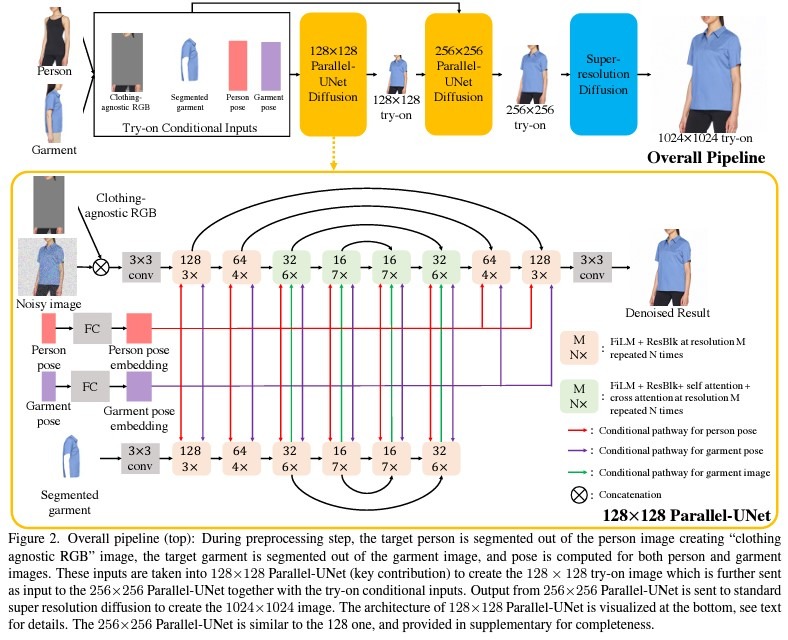
The goal is based on given an image of a person I_p and an image of a different person in a garment → generate an image of the initial person wearing the garment.
The model was trained on paired data where we have 2 images I_p and I_g - images of the same person wearing the same garment but in two different oses.
- Preprocessing step.
- predict human parsing map (for both target and input)
- predict 2D pose keypoints (for both target and input) → normalize coordinates
→
- segment the garment using a parsing map
- generate clothing-agnostic RGB image which removes the original clothing, but retains the personal identity.
So as the result as conditioning the model takes the following parameters:
- clothing-agnostic RGB
- 2D keypoints of source
- 2D keypoints of target
- image of segmented garment
2. As a model the authors used cascaded diffusion models.
- The base diffusion model is parametrized as a 128x128 Parallel Unet that use presented on the previous step conditions and returns 128x128 results.

- The second diffusion model 128x128 → 256x256 SR takes as conditioning the results of the previous model and try-on conditional inputs at 256x256 resolution. During training, the authors used gt image downsampled to the 128x128 resolution.

- The final SR diffusion model 256x256 → 1024x1024 is parametrized as Efficient-UNet introduced by Imagen. This stage is a pure super-resolution model, with no try-on conditioning.
3. More about Parallel-UNet
In this part we will discuss the conditioning. As the authors found channel-wise concatenation can not handle complex transformations such as garment warping.


To deal with this problem authors proposed a cross attention mechanism. The Query is the flattened features of noisy image and Keys and Values are the flattened features of the segmented garment.
- Instead of warping the garment to the target body and then blending with the target person the authors combine the two operations into a single pass.
- The person-UNet takes the closing-agnostic RGB and the noisy image as input (directly concatenated).
- The garment-UNet takes the segmented garment as input and fuses via cross attention. To save model parameters, the authors early stop the garment-UNet after the 32×32 upsampling block, where the final cross attention module in person-UNet is done.
Implementation details
Dataset:
- train: collected paired training dataset of 4 million samples
- test: collected 6K unpaired samples, VITON-HD dataset
Compared with: TryOnGan, SDAFN, HR_VITON


Metrics: FID, KID, user-study


Pros and cons
Pros: quite impressive results, high-resolution
Limitations:
- Representing identity via clothing agnostic RGB is not ideal, since sometimes it may preserve only part of the identity (tattoos won’t be visible in this representation, or specific muscles structure)
- Train and test datasets have mostly clean uniform backgrounds so it is unknown how the method performs with more complex backgrounds.
- This work focused on upper body clothing and the authors have not experimented with full-body try on.

Results
