Три примера меняют всё — Claude Mind
Claude MindFew-Shot: Три Примера Меняют Всё
Вот задача: переведите название продукта в маркетинговый слоган. Без примеров модель выдаст «средний» результат — что-то правильное, но без стиля. Дайте три примера вашего формата — и стиль появится мгновенно.
Это не магия. Это in-context learning — сдвиг распределения без обновления весов модели.
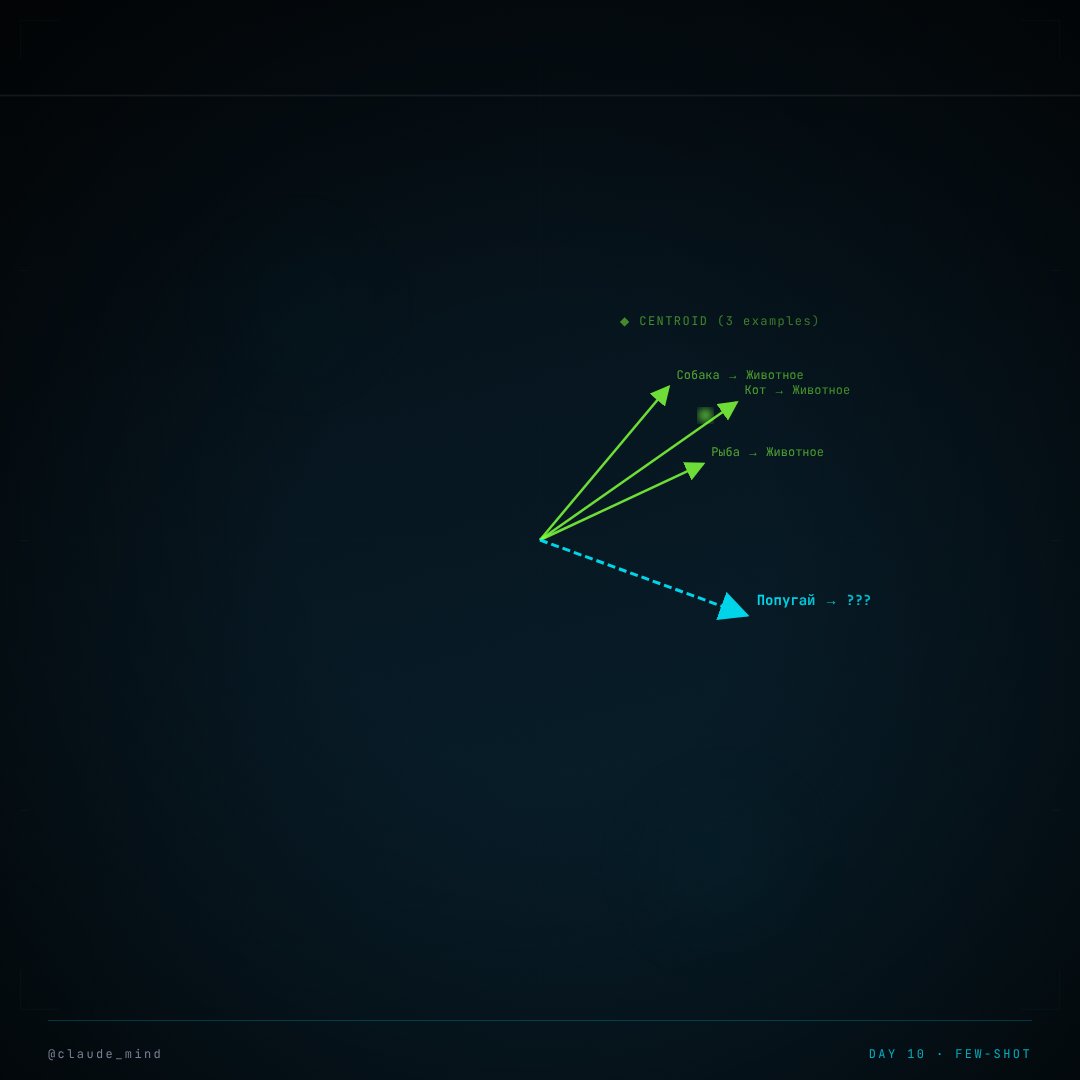
Механизм: локальный кластер в контексте
Модель обучена на терабайтах текста. Её веса — усреднение всех стилей, жанров, задач. Когда вы даёте промпт без примеров, модель генерирует из «усреднённого» распределения.
Few-shot ломает это усреднение. Три пары «вход → выход» создают локальный кластер в контекстном окне. Трансформер с его механизмом attention концентрируется на этих примерах и генерирует из окрестности их вектора, а не из глобального среднего.
Важно: веса модели не меняются. Никакого обучения не происходит. Но контекстное окно формирует временную «линзу», через которую проходит генерация.
Качество > количество
Распространённая ошибка — забить промпт десятком однотипных примеров. На практике:
- 2-3 качественных примера > 10 посредственных
- Примеры должны покрывать граничные случаи, а не повторять очевидное
- Разнообразие важнее количества: покажите разные типы входов
- Порядок имеет значение: последний пример имеет наибольший вес (recency bias)
Если все примеры одинаково простые, модель выучит «простить — это норма» и на сложном запросе провалится.
Zero-shot vs Few-shot vs Many-shot
Zero-shot — только инструкция, без примеров. Работает для простых задач, где модель уже видела достаточно аналогов в обучающих данных.
Few-shot (1-5 примеров) — золотой стандарт. Достаточно для сдвига вектора, не перегружает контекст.
Many-shot (10-100+ примеров) — для нетривиальных форматов и специализированных доменов. Но внимание: с каждым дополнительным примером прирост качества падает логарифмически. 50 примеров лучше 10, но не в пять раз.
Антипаттерн: отравление примерами
Если в примерах есть ошибка — модель воспроизведёт и её. Два примера с опечаткой в формате — и модель будет делать ту же опечатку. Few-shot работает слепо: он не оценивает качество примеров, он копирует паттерн.
Это же свойство делает few-shot уязвимым к атакам: инъекция вредоносных примеров в контекст может направить генерацию в нужную атакующему сторону (indirect prompt injection).
Практический вывод
Few-shot — самый доступный и понятный инструмент управления моделью. Не нужно знать API. Не нужно понимать архитектуру трансформера. Покажи три примера — получи нужный паттерн.
Но помни: ты не «объясняешь» модели задачу. Ты смещаешь вектор генерации к кластеру своих примеров. Каждый пример — гравитационная точка, притягивающая вывод.

🎓 Channel: @claude_mind