Тревога в мире LLM
Evgeniy NikitinНедавно наткнулся на твит от авторов свежей опенсорсной LLM MiniMax M2.
Уже первые абзацы заставили меня почувствовать сильную внутреннюю тревогу. Окей, я хотя бы смог прочитать и понять, что написано, уже хорошо, бывает, что прям совсем не выкупаю. Но если задуматься, сколько всего кроется за этими словами - всего того, что в идеале хотелось бы прочитать, изучить, разобраться. Мысль скачет за мыслью, и в итоге можно набрать огромный список и огромный ком тревоги:
- Linear/sparse attention - в последнее время опять вспыхнули дебаты о том, можно ли уйти от квадратичности этеншна без потери качества. Недавно появилась статья Kimi Delta Attention про гибридный этеншн, который используется в Kimi K2 и якобы показывает лучшие результаты, чем полный этеншн. Само собой, это не единственная свежая статья на тему.
- Multimodality - недавно тестил ряд VL-моделей и специализированных OCR-моделей, захотелось получше разобраться, как они работают внутри, чем отличаются от предыдущих поколений. А ещё и время от времени появляются специализированные медицинские мультимодальные модели. Кстати, на днях обсуждали применение таких моделей в хирургии, надо бы про это почитать...
- RL - давно пора разобраться во всех этих DPO, PPO, GRPO. Когда нужны reward-модель и value-модель, когда не нужны? А GEPA правда бьёт RL на реальных задачах? Надо хотя бы обзор Рашки почитать... Хотя он уже успел устареть, наверное. Кстати, а чем там завершилась сага про BF16/FP16?
- Low-precision compute - окей, примерно понятно, что такое FP16, Q8_0 Q6_K_M. А чем по факту отличаются AWQ, bnb, EXL2, GPTQ, GGUF? Что и когда лучше использовать? Господи, да сколько там этих способов и форматов??? Какие на лету могут работать без калибровки? Ну хотя бы можно нагуглить всякие блог-посты или старьё с реддита, добавляем в список на чтение.
- Interleaved thinking - ага, слышал, слышал, это когда модель может ещё "подумать" после вызова инструмента и по итогу решить, что делать - например, вызвать следующий инструмент. Из-за того, что не все провайдеры поддерживают такой паттерн, у китайских моделей были просадки по метрикам. Всё же правильно я помню? На всякий случай ещё раз почитаю...
- Caching - вот бы разобраться наконец, как правильно vLLM настраивать, чтоб оптимально работал на моей 3090... Почему-то для мультимодальных моделей нельзя устанавливать слишком высокий gpu_memory_utilization? vLLM неточно оценивает потребление для мультимодальных моделей? А размер картинки и количество визуальных токенов влияет? Может, я вообще что-то напутал - вроде бы, ничего не гуглится...
- Speculative decoding - это я помню, недавно, кстати, видел интересный вопрос с собеседования - почему при повышении температуры LLM может расти latency? По идее, один из вариантов - как раз из-за speculative decoding. А этот механизм поддерживается из коробки в vLLM? О, да, поддерживается, нужно попробовать...
Можно ли так жить?

Думаю, это чувство падения в кроличью нору знакомо многим. Раньше меня спасала чёткая система ведения задач. Всё что встречаю и хочу прочитать - добавляю в отдельный раздел to-do, по мере возможности беру оттуда задачки и читаю. Но сейчас область развивается так быстро, что список нарастает быстрее, чем успеваешь читать, хоть в лепёшку расшибись.
Не будем забывать ещё о паре мелочей:
- Рутинные рабочие обязанности никто не отменял, как, собственно, и важные нерутинные менеджерские штуки, о которых нельзя забывать - стратегия, ранняя диагностика проблем, финансы. Ещё и надо правильно балансировать между работой и самообразованием, а грань - очень тонкая.
- Кроме ML и LLM есть ещё много чего интересного и важного для работы - медицина, менеджмент, software engineering и многое другое.
- Хочется делать пет-проекты - нет смысла набивать голову только теоретическими знаниями, всё важное надо пробовать и на практике. Даже с ИИ-инструментами это занимает значительное время.
- Кстати, ещё есть такие вещи как семья, друзья, отдых, хобби, сон...
В общем, надо признать - в современном мире невозможно изучать всё интересное. Это ещё с учётом того, что не всё интересное даже до нас доходит. В эпоху до LLM машинное обучение тоже развивалось очень быстро, но количество информации реально выросло на порядок. Получается, тревога - естественный сигнал организма на априори невыполнимую задачу.
В последние месяцы моя тревожность достигла такого уровня, что стала мешать жить и радоваться мелочам. Конечно, я решил на всякий случай сходить и к психологу, но всё-таки спасение утопающих - дело, в первую очередь, рук самих утопающих.
Разделение интересов на несколько зон
Все входящие ссылки и материалы сейчас очень стараюсь (старые привычки умирают долго) класть не в один большой список, а в одну из четырёх зон. Сразу скажу, идея - не новая, можно вспомнить Inbox Zero, матрицу Эйзенхауэра или чего-нибудь ещё такое зонально-корзинное. Основная мысль - если сейчас энергии, сил, времени не хватает, то достаточно держать чистой только самую приоритетную зону, это уже сильно уменьшает тревогу.
Сначала принимать решения может быть тяжело, но по ходу дела эмпирически начнут появляться понятные паттерны. Их можно оформлять в более явные критерии - за этим слежу, за этим не слежу. Оформленное "официально" признание, что я осознанно не слежу за этой конкретной областью, сильно снижает уровень тревожности. Всё-таки на бумаге написано.
Решение о том, в какой список должен попасть тот или иной материал, я принимаю очень быстро, и информации/времени в этот момент может быть недостаточно. Поэтому важно регулярно прореживать списки в более спокойной обстановке. Например, сесть с утра, прочитать абстракты/ИИ-саммери недавно добавленных материалов и решить, нужно ли переместить его в другой список. Альтернатива - валить всё в один лист, но каждый день утром распределять по категориям.
Must-have
Сюда попадают штуки, которые либо очень важны и релевантны для работы в целом, либо важные и актуальные в конкретном моменте (скоро созвон по теме или хочу написать пост). Например, для меня это могут быть:
- Материалы по ML в рентгенологии по нашим модальностям - новые архитектуры, подходы, открытые модели
- Материалы по LLM, прямо связанные с нашими текущими или вероятными будущими проектами
- Инженерные или менеджерские материалы, которые могут помочь решить актуальную в данный момент или в ближайшем будущем проблему
- Любые другие материалы, которые мне по какой-то причине очень важно прочитать (это опасный пункт, так как он размытый, но абсолютно полный список критериев всё равно не составить)
Я не берусь за другие списки, если этот список - не пустой. Поэтому в интересах моего внутреннего любопытника держать его небольшим.
Nice-to-have
Менее важные, но всё ещё релевантные для работы штуки. Например, сюда попал недавний плейбук по обучению и пост-обучению LLM. Прямо сейчас я не собираюсь сам обучать никакие LLMки, но в целом такие знания могут быть полезны - как косвенно, так и прямо, ведь одна из наших команд прямо сейчас этим и занимается.
Из этого списка я стараюсь читать регулярно, если я сейчас в ресурсном состоянии, хотя бы по 2-3 материала в неделю. Если времени или менталочки мало, то он может разрастись, ничего страшного, что-то со временем может и выпасть из этого списка, не пройдя проверку временем.
No-need-but-interesting
Штуки, которые лично мне по какой-то причине интересны, но, положа руку на сердце, в работе в обозримом будущем они мне не пригодятся. Ну вряд ли я умру, если не разберусь в разных современных способах аппроксимации этеншна или не прочитаю про очередной RAG-фреймворк, который должен заменить все остальные. Но интересно.
Такие материалы можно качать в поездку или читать, когда хочется отвлечься от основной работы.
Put-and-forget
Иногда появляется порыв что-то сохранить на всякий пожарный - например, какое-нибудь глубокое погружение в причины training-inference mismatch в RL. Хрен когда я это прочитаю, но закину - пусть валяется. И мне спокойнее, и вреда нет. Если вдруг прям понадобится и вспомнится через год - можно будет найти в архиве.
Оптимизация потребления информации
Вдумчиво читать все новые интересные статьи физически невозможно. Поэтому нужны инструменты более оптимального изучения контента.
Саммери-статьи, surveys
Чаще всего нет никакой необходимости читать статью прям сейчас, в моменте. Если подождать пару месяцев, то по актуальной теме обязательно появится какое-нибудь хорошее саммери или крутой блог-пост. Я очень люблю посты Себастьяна Рашки, они понятные и классно иллюстрированные.
Кстати, его недавняя статья про различия архитектур современных LLM отлично иллюстрирует, почему нет особого смысла читать каждый техрепорт и вообще почему чаще всего выгодно подождать, пока тема настоится.
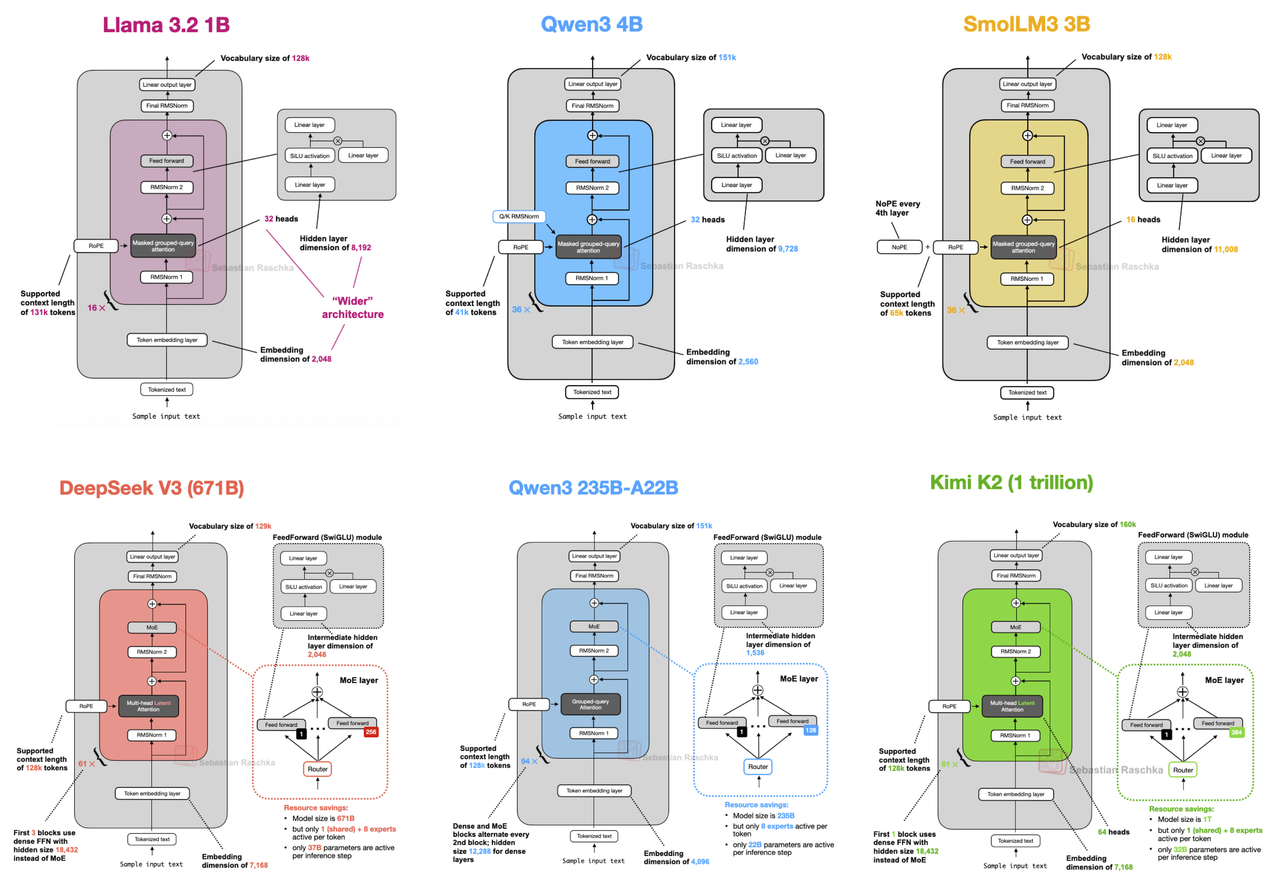
По большому счёту 90% новых концепций - это маленький твик старой, их комбинация или вообще то же самое с другим названием. Бывает и такое - новая статья наделала хайпа, а в итоге в реализации нашли ошибку или результаты оказались сильно преувеличены.
ИИ-саммеризация
На мой взгляд, читать только LLM-саммери - дело гиблое. Теряется много деталей, утрачивается навык внимательного чтения. Но для грубой оценки, нужно ли вообще это читать, для быстрого впитывания не самых важных материалов - это очень хороший инструмент. Можно кидать в ChatGPT, можно установить плагин или вообще пользоваться одним из новых ИИ-браузеров (Atlas, Comet, Dia). Я пока предпочитаю по старинке.
Делегирование
Часто материал может быть интересным, но значительно более релевантным для другой команды или человека. Тогда можно не читать его внимательно самому, а поделиться им. В этом случае крайне важно не кидать полный мусор - надо пробежаться по материалу или хотя бы его саммери и убедиться, что он релевантен и достойного качества. Иначе на ваши "пересылки" скоро перестанут обращать внимание.

Важную часть этой "делегированной" информации часто легко получить обратно - к примеру, через всякие общие мероприятия. Она ещё и будет обогащена практическим опытом - попробовали это, получилось, а это - фигня полная.
Можно даже попросить человека - слушай, а удели 20 минут, расскажи или напиши мне, что знаешь по этой теме, у меня скоро созвон/стратсессия/доклад, хочу вникнуть. Вряд ли вам откажут (если вы не козёл).
Рефлексия
Пока ещё не пробовал, но хочу в конце года затестить такую тему - пройтись по всем материалам из разных списков важности и оценить, что из этого реально прямо или косвенно помогло в работе за последние полгода. Должно помочь более чётко сформировать критерии по разделению, но, может быть, сложно реально оценить эффект.
Ограничение триггеров
Я специально в этом году перенастроил свою ленту в Твиттере (отписками, подписками, лайками, хотя скоро, вроде бы, можно будет напрямую попросить Грок), чтоб в ней было больше ML. Идея состояла в том, чтоб даже когда я думскроллю поток новостей о карусельных арестах молодых ребят по всей стране, в нём попадались бы твиты об ML. В целом сработало, но обратный эффект тоже получился мощный - кратное увеличение новых материалов в списке и, соответственно, уровня тревоги. Так что даже такие "полезные" источники информации нужно ограничивать - желательно явно, например, только определёнными часами или ситуациями (еду в транспорте).
Понимание себя
И, наверное, самое важное.
Я по бэкграунду, по духу MLщик и совсем немножечко учёный. Хочется всё знать, всё понимать и даже что-то придумывать самому. Но жизнь меня не сама сделал техдиром в ML-стартапе, это было (почти) осознанное решение. Были у меня развилки, где можно было пойти другим путём. И я почему-то выбрал именно этот.
Раз так, то нужно понимать свою роль и её требования:
- Сильный и актуальный технический бэкграунд - важно
- Широкий кругозор и знание трендов - важно
- Умение задавать правильные (пусть иногда глупые) вопросы - очень важно
- Способность быстро понять суть конкретной статьи без вникания в технические детали - важно
- Скилл не тушеваться и быстро сообразить, что делать, если на встрече задают вопрос на не особо знакомую тему - очень важно
- Глубокое понимание каждой конкретной технической темы и каждого проекта - не так уж и важно
Осознавать это может быть грустно, а принимать - тяжело. Но в каждой работе есть свои плюсы и минусы, и главное - найти свою работу мечты и принять все её стороны, хорошие и плохие.
Конечно же, программа-максимум - понять, что конкретно вызывает тревогу. Я полагаю, что это страх возникновения какой-то плохой ситуации, например, в моём случае это могут быть:
- Страх показаться тупым на важном собрании или перед своими сотрудниками
- Страх, что нечего будет рассказать в канале или на конференции, и про меня все забудут
- Страх, что перестану приносить пользу компании и буду сидеть просто отбывать номер или, хуже того, мешать всем
- Страх, что карьера пойдёт под откос и я потеряю доход и привычный уровень жизни, подведу семью
У каждого из этих страхов есть какая-то причина и какие-то защитные реакции. Психолог мне сейчас дала задание вести дневник СМЭР: Ситуация (факт, что произошло), Мысль (которая автоматически возникла в голове), Эмоция (чувство, вызванное этой мыслью), Реакция (действие или телесная реакция). Стараюсь вести дисциплинировано, хотя бывает и тяжело, конечно. Посмотрим, поможет ли.
И в заключение
Решил ли я проблему повышенной тревожности? Абсолютно точно нет.
Стало ли мне уже чуть полегче по итогу принятых мер? Пока немного, но точно да.

Полагаю, что у кого-то такой проблемы нет вообще. Кому-то пофиг, кто-то всё успевает, кто-то осознанный, кто-то - гений, у кого-то узкая область. Но всё-таки думаю, что я не одинок, так что я решил написать этот пост. Может, вам станет чуточку полегче от самого факта, что есть такие же тревожные люди.