Transformer
Вот как выглядит трансформер из статьи "Attention is all you need"
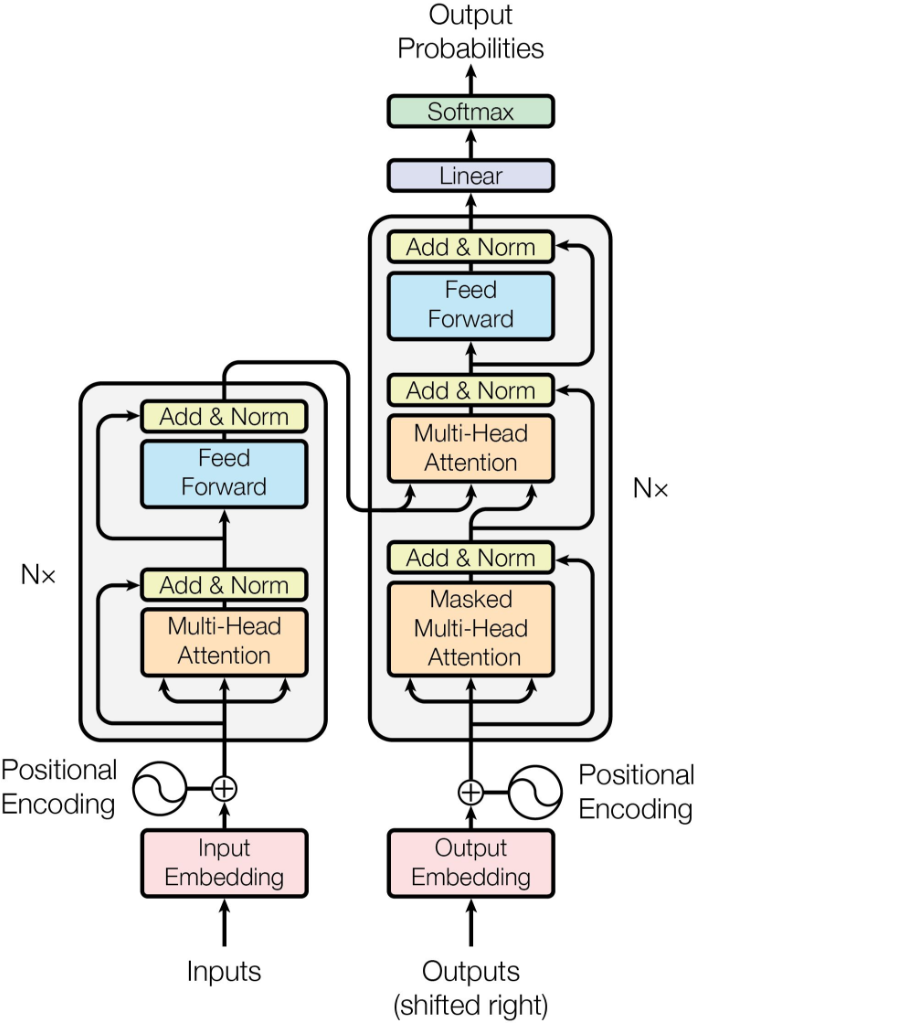
Его левая часть называется encoder (кодирует исходный текст), правая - decoder (декодирует в перевод).
Transformer Encoder
Рассмотрим устройство Transformer Encoder, слой за слоем.
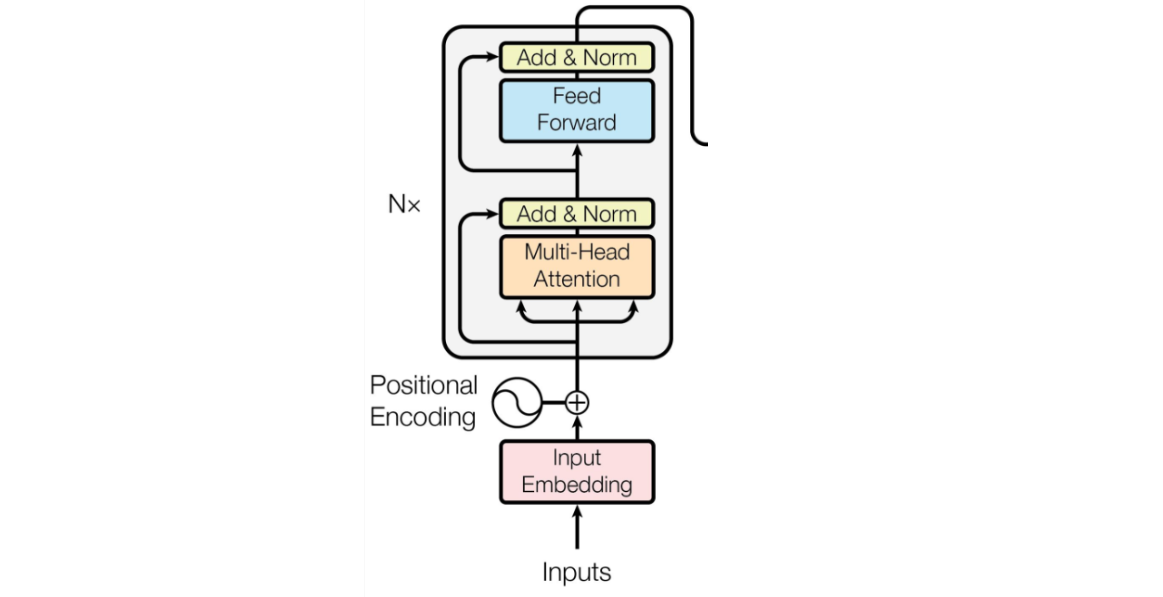
1. Input and Input Embedding
Input - это входной токен. Он преобразуется в Input Embedding - векторное представление. На канале есть пост о том как можно преобразовать текст в вектор.
2. Multi-head attention
Поднимаемся дальше и встречаем Multi-head attention.
2.1. Attention
Сначала вспомним суть простого attention слоя: по скрытым состояниям энкодера и декодера, декодер учился обращаться внимание на какие-то слова у энкодера. Например:

2.2. Self-attention
Self-attention работает только с вектором энкодера, то есть энкодер учится обращать внимание сам на себя (потому self). Его идея заключается в следующем: self-attention обновляет embedding-и каждого токена, добавляя в них полезную информацию на основе контекста (всех остальных токенов в предложении) в котором эти embedding-и находятся.
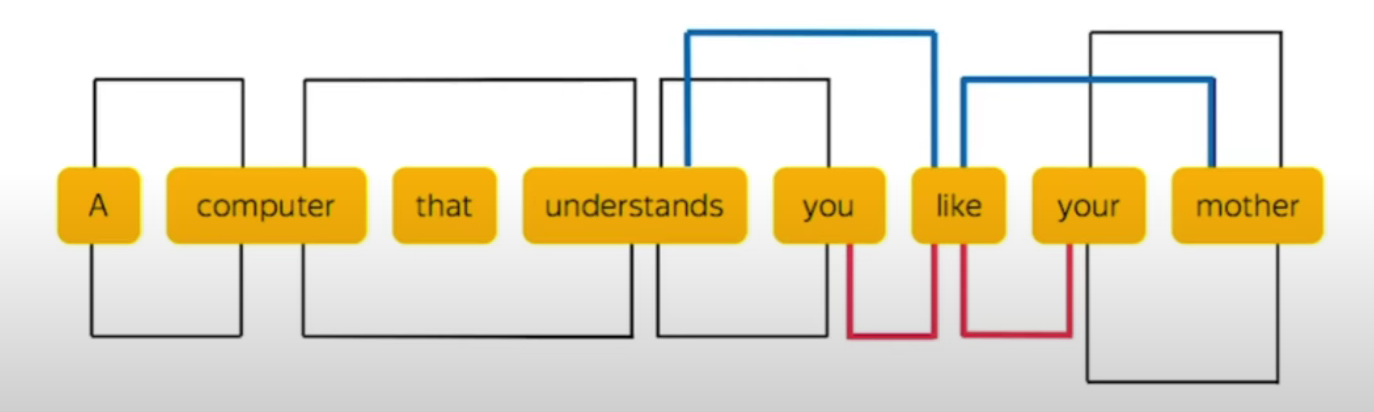
Например:

В первом случае предложение переводится как:
"Животное не переходило улицу, потому что оно было слишком уставшим."
На английском "it" относится к "animal" (все равно что "оно" относится к слову "животное").
Перевод во втором случае:"Животное не стало переходить улицу, потому что она была слишком широкой."
"it" на этот раз относится к "street" ("она" относится к "дороге").
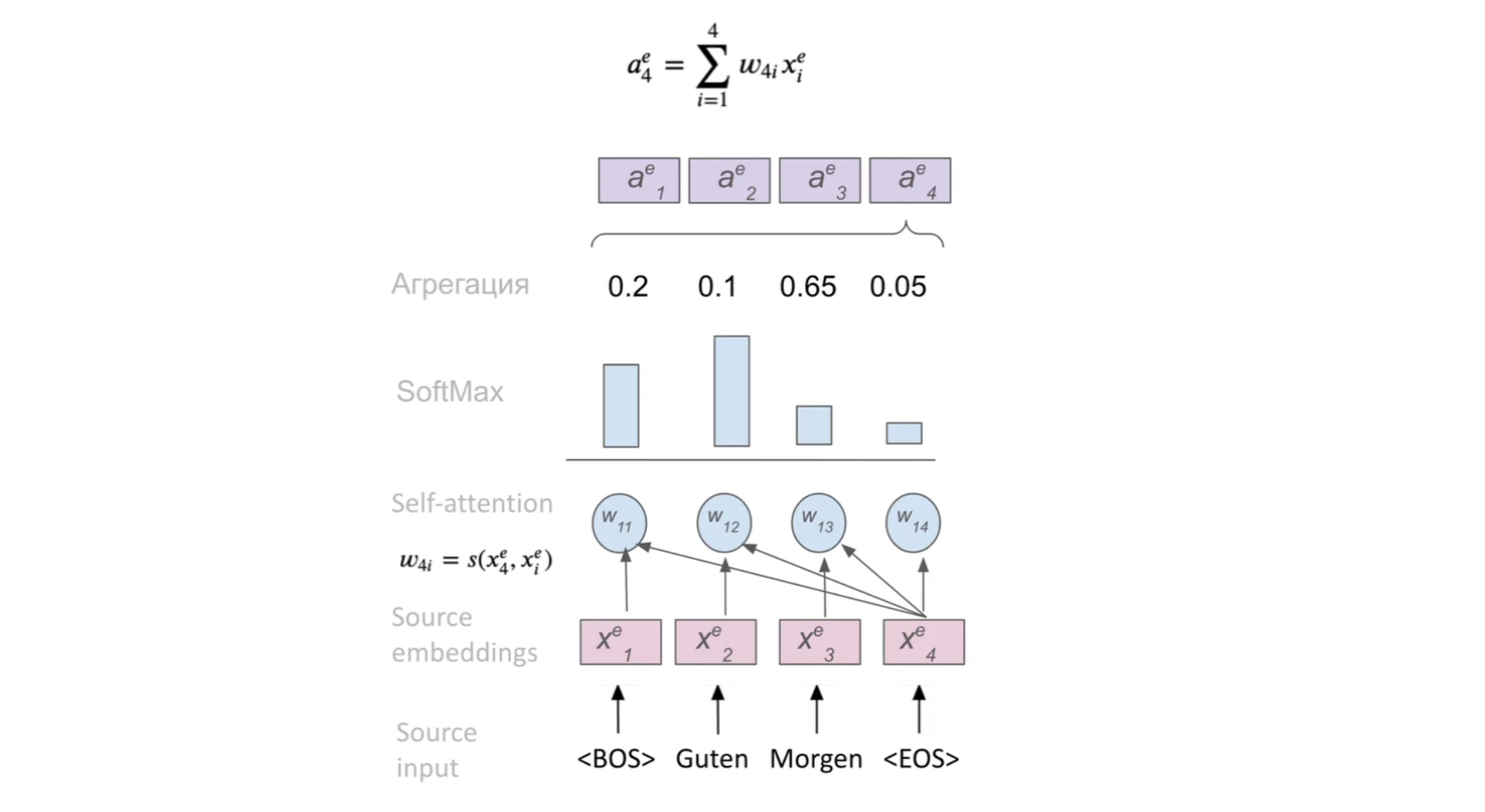
Разберем self-attention по шагам:
- Для каждого токена вычисляем вектор важности других токенов, используя функцию внимания:
w = s(xi, xj);s- функция внимания (например, скалярное произведение),w- вес (вектор важности)xjтокена дляxiтокена. - Прогоняем вектор важностей через
softmax, получаем распределение вероятностей наembedding-и - Агрегируем эмбеддинги, основываясь на их весах
aj = Σ wji * xi
2.3. Multi-head attention
Выше мы рассмотрели пример, когда между словами прослеживается лишь один тип связи (в примере это была связь между существительными "animal" и "street" и местоимением "it"). Однако, между словами в предложении могут быть разные типы связей.
Потому, логично использовать не один слой self-attention, а несколько. Разные слои self-attention могли бы обращать внимание на разные типы связей между словами. Это и есть multi-head attention или, по другому, self-attention с несколькими головами.
То есть теперь есть несколько (n) функций внимания s (по одной на каждую голову). Для каждого эмбеддинга выдается по n векторов внимания (a1, a2, ..., an). Для того чтобы превратить n векторов внимания в один просто применяют операцию конкатенации, а затем прогоняют через полносвязный слой: a = W(concat[a1, a2, ..., an] + b).
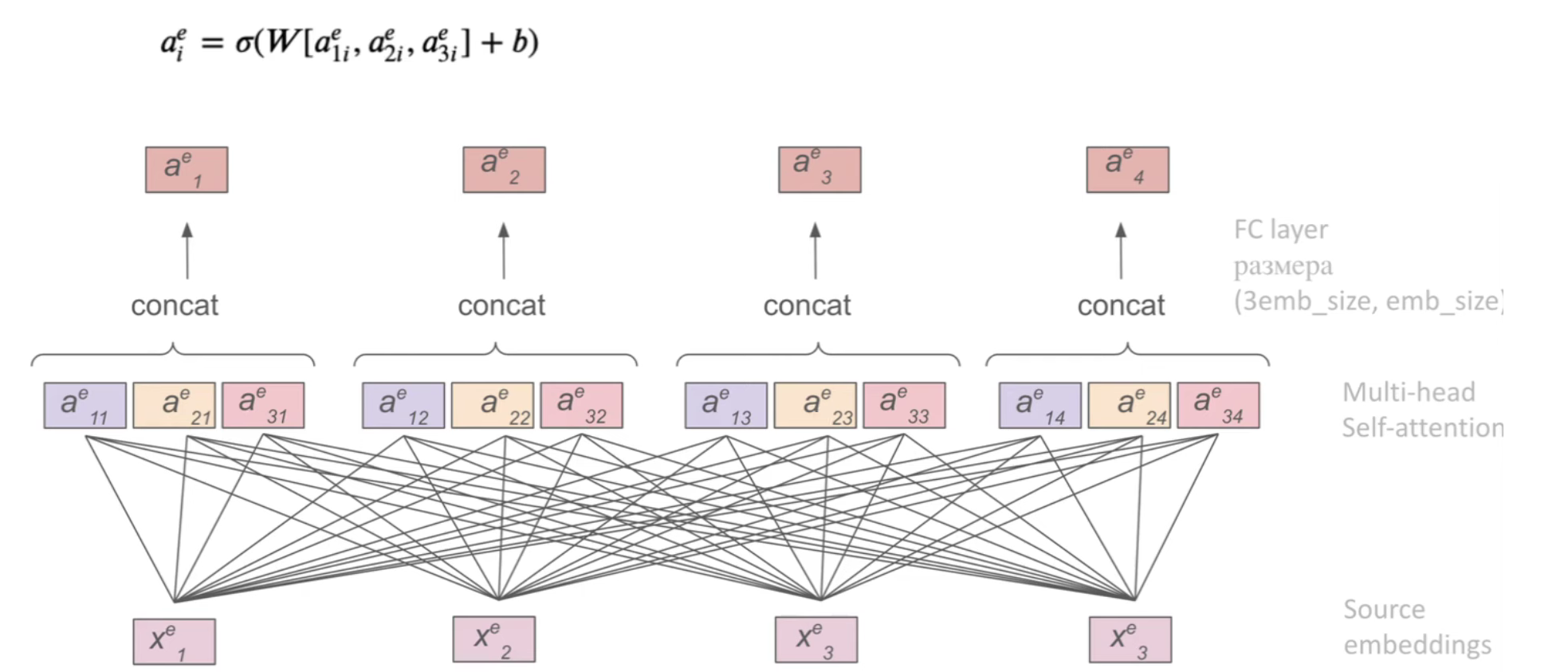
Визуализация multi-head attention:
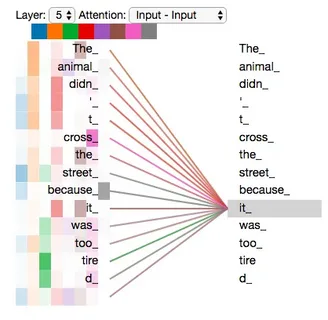
А дальше все как с обычным self-attention.
2.4. Другое объяснение (QKV-attention)
Понятия Q(query), K(key) и V(value) пришли из поиска.
Q - запрос, K - краткая сводка по документу и V - сам документ.
Задача - по Q и K понять насколько насколько документ релевантен (какой V выбирать).
Получим матрицы Q, K и V путем перемножения X (входных данных) на соответствующие матрицы весов Wq, Wk и Wv соответственно:
Q = Wq * X K = Wk * X V = Wv * X
Attention будем искать следующим образом:
Attention(Q,K,V) = softmax(QKᵀ/√dₖ)⋅V
Multi-head attention - конкатенация результатов нескольких отдельных attention операций, отображенная в заданную размерность.
Multi-head(X) = Concat(head₁, ..., headₙ)⋅W⁰
head = Attention(Qᵢ,Kᵢ,Vᵢ)
3. Слой Add & Norm
Add - просто прибавляет к embedding-ам self-attention слой.
Layer-norm - нормализует значения embedding-ов по слоям. Все так же, как и batch-норм, только по слоям:
- Для каждого embedding-а в отдельности считаем среднее и стандартное отклонение
- Пересчитываем для каждого embedding-а значение по формуле: xi = (xi - mu)/(std + e) * gamma + beta, где gamma и beta - обучаемые параметры.
Если интересно почему так, то вот пост на канале - Batch-Normalization.
Layer-norm помогает избежать проблемы взрывающихся градиентов и стабилизирует обучение модели.
4. Feed-forward network (FFN) или полносвязный слой (FC)
В оригинальной статье - это два полносвязных слоя, с функцией активацией ReLU между ними.
Однако, структура полносвязной части может быть любой.
5. Снова Add & Norm
Encoder заканчивается на применении слоя Add & Norm (который описан в 3 пункте).
6. Positional Encoding
Осталось разобрать только маленькую, но очень важную деталь, пропущенную с самом начале. Это Positional Encoding.
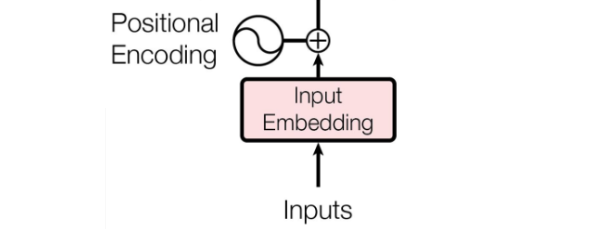
Вспомним, что главное преимущество RNN-ок - это то, что они сохраняют временную связь между словами, читая текст слово за словом.
Positional Encoding добавляет к изначальным эмбеддингам информацию о позиции эмбеддинга в предложении (позициональный вектор такого же размера, что и сам эмбеддинг):
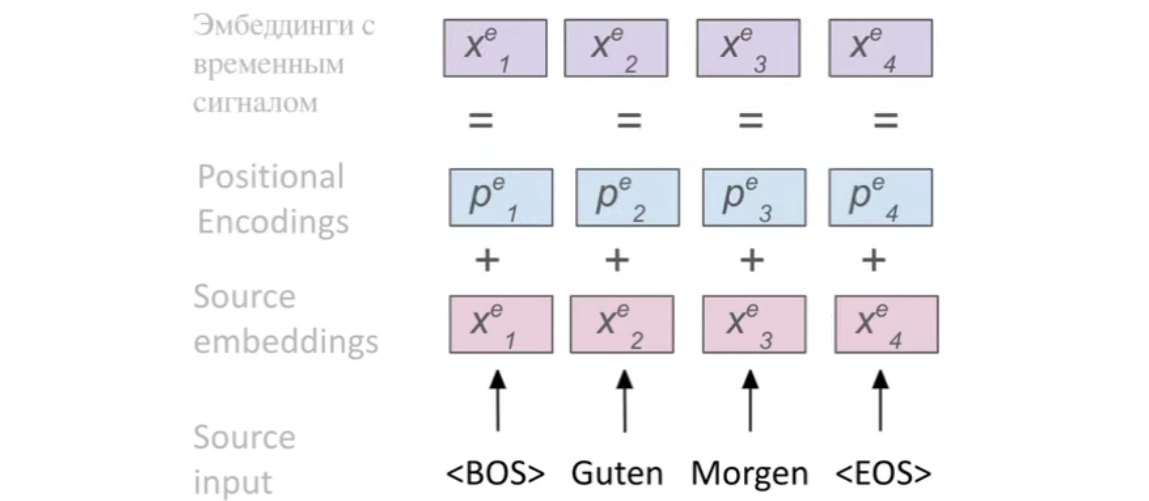
Существуют разные подходы получения позициональных векторов.
Один из самых распространенных - через тригонометрические функции (он и был предложен в статье "Attention is all you need").

где emb_dim - размер каждого эмбеддинга, i - номер элемента позиционального вектора, t - позиция токена
Почему функция positional encoding именно такая:

Transformer Decoder
Пройдя через энкодер, текст преобразовывается в какое-то удобное представление. Теперь декодер должен преобразовать это представление в текст.

Output Embedding - это весь текст, преобразованный с помощью энкодера (весь output энкодера).
Вновь нам встречается уже знакомый Positional Encoding, который добавляет позиционную информацию уже относительно сформированных выходов.
Далее встречаем Masked Multi-Head Attention.
1. Masked Multi-Head Attention
По-идее, выходы должны генерироваться авторегрессионно, слово за словом.
Однако, Masked Multi-Head Attention реализует более хитрый вариант: к attention (матрице, которая отвечает "кто на кого смотрит") применяется авторегрессивная маска, бращаюя в −∞ веса до softmax для токенов из будущего, чтобы после softmax их вероятности стали нулевыми. Эта маска имеет нижнетреугольный вид (левый нижний треугольник).
Таким образом, каждый элемент смотрит только на те элементы, которые были в прошлом и не заглядывает в будущее. Значит данные можно подавать не авторегрессионно, а все сразу.
При этом, на инференсе Masked Multi-Head Attention работает как обычный Multi-Head Attention.
2. Multi-Head Attention
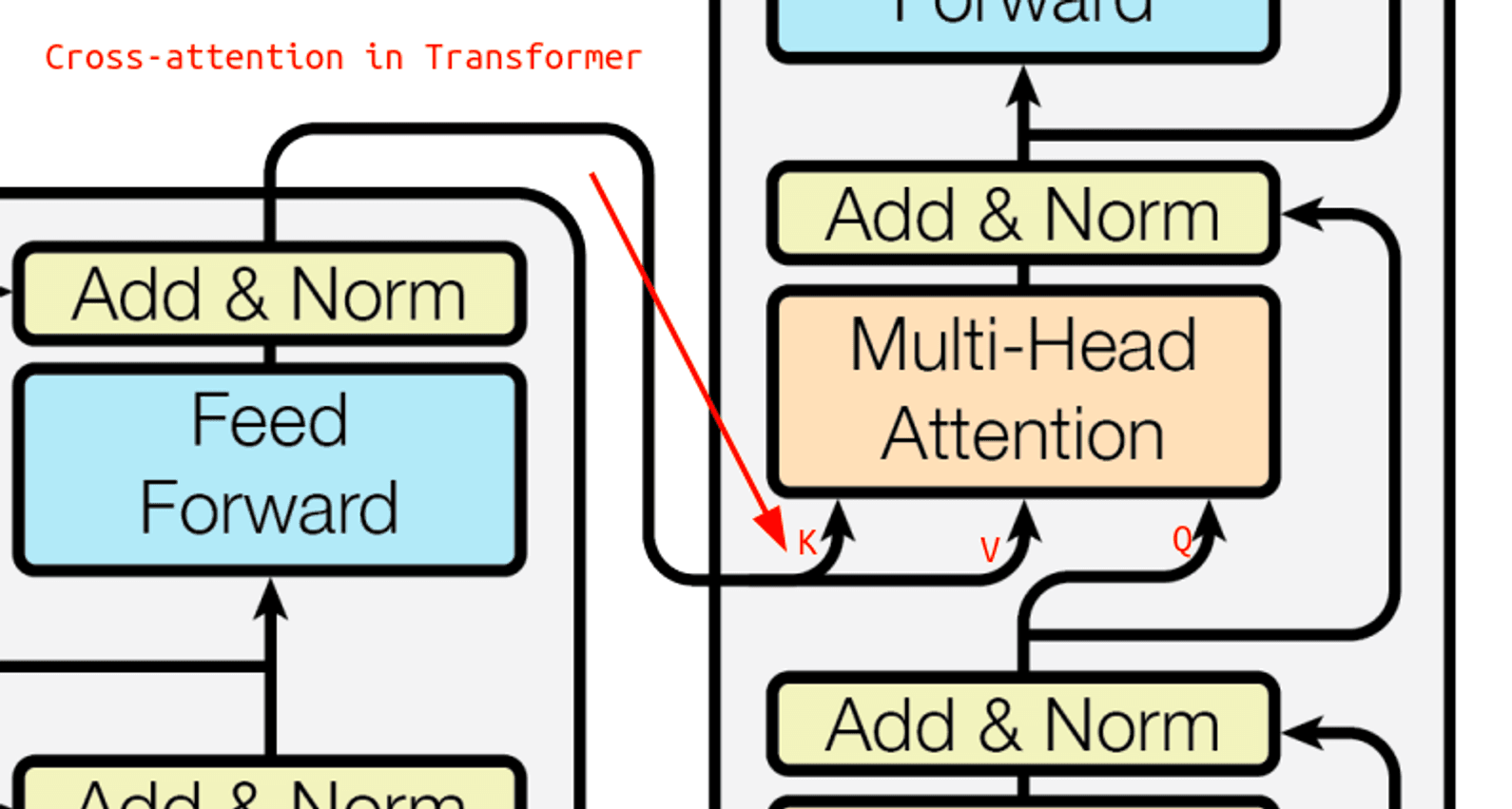
Второй Multi-Head Attention декодера является слоем кросс-внимания (cross-attention), в котором запросы берутся из выходной последовательности, а ключи и значения — из входной (то есть из результатов работы энкодера). То есть Multi-Head Attention получает K и V из энкодера, а Q берет из прошлого слоя декодера.
Его идея заключается в следующем: есть attention только для энкодера и attention только для декодера. Последний Multi-Head Attention должен смешать информацию из декодера и энкодера. Причем этот слой можно повторять несколько раз.
Все остальные слои не имеет смысла расписывать, поскольку они уже знакомы.
Суммаризируя:
Трансформер - архитектура построенная на механизме внимания.
Каждый слой обрабатывает эмбеддинги слов параллельно, а значит куда быстрее чем RNN-ки.
Вход и выход каждого слоя имеют одинаковый размер, а значит можно подавать последовательности любой длины.
Слои можно менять местами.
Полезные ссылки:
- https://arxiv.org/pdf/1706.03762.pdf
- https://education.yandex.ru/handbook/ml/article/transformery
- https://towardsdatascience.com/build-your-own-transformer-from-scratch-using-pytorch-84c850470dcb