Типы Consistency
https://t.me/faangmasterЧто такое Consistency?
Распределенные системы состоят из множества нод (серверов), которые взаимодействуют друг с другом. Данные распределены между этими нодами при помощи партиционирования/шардирования, т.к. они могут не помещаться на один сервер или для более быстрого доступа они могут быть размещены в разных географических зонах. Кроме того данные дублируются и реплики (копии) данных размещаются на разных нодах репликах. Это необходимо на случай отказа сервера для предотвращения потери данных, а также если нагрузка на систему большая, чтобы все клиенты не читали одни и те же данные с одного сервера, а делали это с разных нод реплик для распределения нагрузки. Т.к. чтение данных может производиться из любой из нод реплик, нам нужно понять, какие гарантии мы можем предоставить клиентам о том, какое значение они прочитают. Будет ли это последнее из записанных значений, устаревшее значение или какое либо еще. Эти гарантии описываются при помощи модели Consistency, которую поддерживает наша распределенная система.
В распределенных системах Consistency может означать множество разных концепций. Это и то, что все ноды реплики должны возвращать одно и то же значение в один и тот же момент времени. Так и то, что чтение данных из распределенной системы, которая содержит множество нод реплик, должно возвращать значение самой последней операции записи данных. Это не единственные определения Consistency, т.к. существует множество ее видов. В целом, Consistency позволяет рассуждать о корректности параллельных операций чтения, записи и изменения данных в распределенной системе.
Если мы хотим использовать распределенные системы типа S3, Dynamo DB, Cassandra в своих проектах, нам необходимо знать какие гарантии Consistency они предоставляют.
Необходимо различать Consistency из ACID и Consistency из CAP Theorem.
Consistency из ACID гарантирует, что транзакции переводят базу данных из одного консистентного состояния в другое консистентное состояние, сохраняя некие инварианты (правила, заданные разработчиками модели данных). Например, это primary key- foreign key связь (Referential integrity). Если строка удалена из базы, то также должны быть удалены все ссылки на эту запись из других таблиц.
В CAP Theorem Consistency гарантирует, что в распределенной системе, каждая нода реплика возвращает одно и тоже значение в одно и то же время. Если мы выполняем операцию чтения из распределенной системы, то мы должны получить значение самой последней операции записи.
Остановимся более подробно на Consistency из CAP Theorem. Существует целый спектр Consistency от сильной до слабой консистентности. Виды Consistency от самой сильной до самой слабой:
Strict consistency (linearizability)
Sequential consistency
Causal consistency
Eventual consistency
Strict consistency (linearizability)
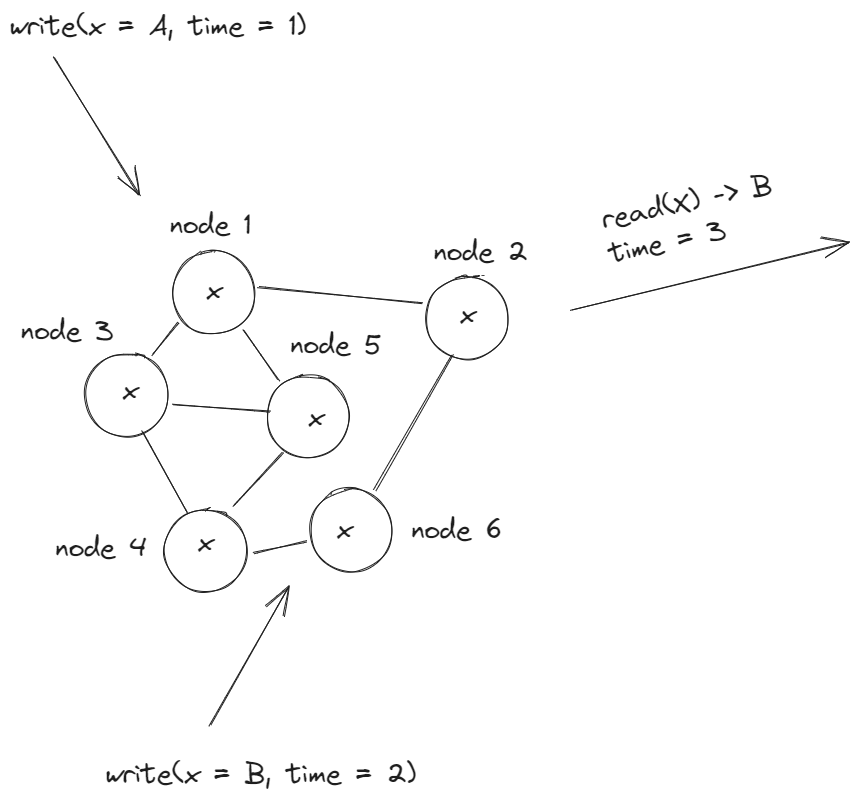
Это самый сильный вид Consistency. Он гарантирует, что запрос на чтение из любой реплики вернет самое последнее записанное значение. Как только клиент, который производил запись, получит подтверждение операции (acknowledgment), все клиенты, которые будут производить чтение данных, увидят это записанное значение независимого от того, из какой ноды реплики будут произведено чтение.
Такую Consistency трудно достичь на практике в распределенных системах. Т.к. нам надо, по-сути, записать одно и тоже значение во все реплики "одновременно", чтобы клиенты, которые читают из разных нод реплик не прочитали разное значение. Это осложняется тем, что всегда могут быть проблемы с сетью, разного рода отказами и т.д.
Для достижения такой Consistency используют синхронную репликацию данных (synchronous replication), а также консенсусные алгоритмы типа Paxos или Raft.
Sequential consistency
Это более слабый вид Consistency, чем Strict Сonsistency. Он гарантирует сохранение порядка операций в рамках одной клиентской программы. Например, у нас есть социальная сеть. И мы хотим гарантировать, чтобы посты от одного и того же пользователя появлялись в порядке их размещения. Но нам не важно, чтобы эти посты были в правильном порядке по времени по отношению к постам от других пользователей. Т.е. нет гарантий глобального порядка всех операций записи и их доступностью для чтения, а только в рамках одного клиента.
Causal consistency
Такой вид Consistency гарантирует порядок только для зависимых друг от друга операций. Например, у нас есть несколько операций типа:
x = 5,
b = x + 5,
y = b
Т.е. чтобы записать в y нам надо сначала прочитать из x, потом вычислить b, а потом записать в y. Операции чтения из x и запись в y зависят друг от друга, поэтому в случае Casual consistency мы гарантируем такой порядок выполнения операций и доступности их результатов для чтения. Но мы не гарантируем, что независимые друг от друга операции будут выполнены в их глобальном порядке по времени.
Например, у нас есть социальная сеть и мы добавили возможность комментировать посты, а также комментировать другие комментарии. В таком случае нам важно только то, что ответы на комментарии появлялись позже самих комментариев, но нам не важно, чтобы все комментарии появлялись в строгом глобальном порядке по глобальному времени.
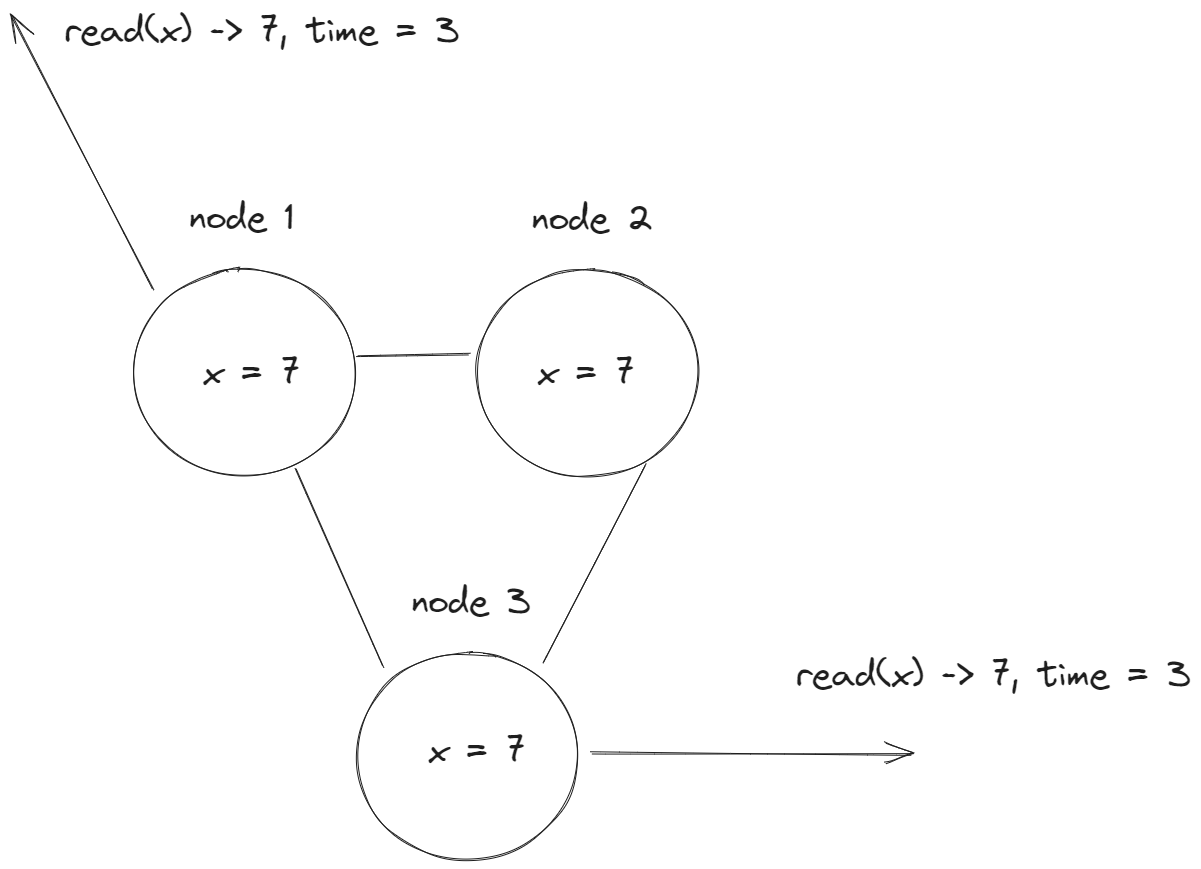
Eventual consistency
Это самая слабая из видов Consistency. Она гарантирует, что все реплики "в конечном счете" вернут одно и тоже значение на запросы на чтение, но это значение не будет последним из записанных. Но самое значение достигнет своего последнего значения в "в конечном счете".
Например, у нас есть некая распределенная система с 3 нодами репликами:
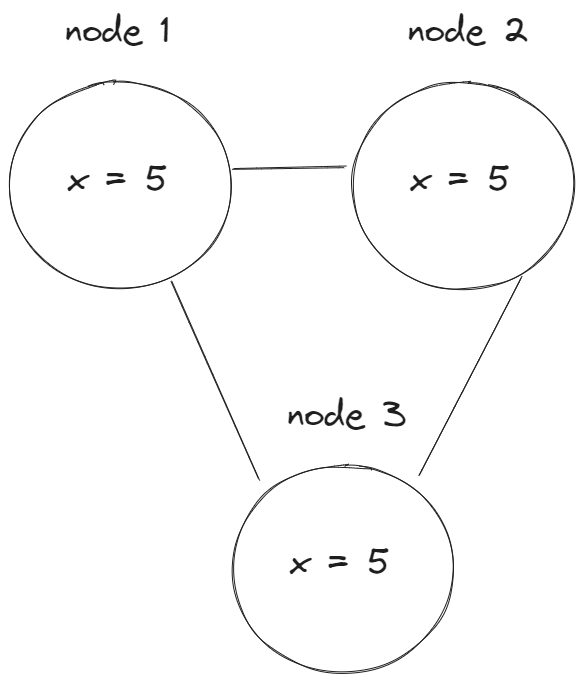
Начальное состояние данных x = 5
Далее приходит запрос на запись x = 7 в момент времени t = 1:
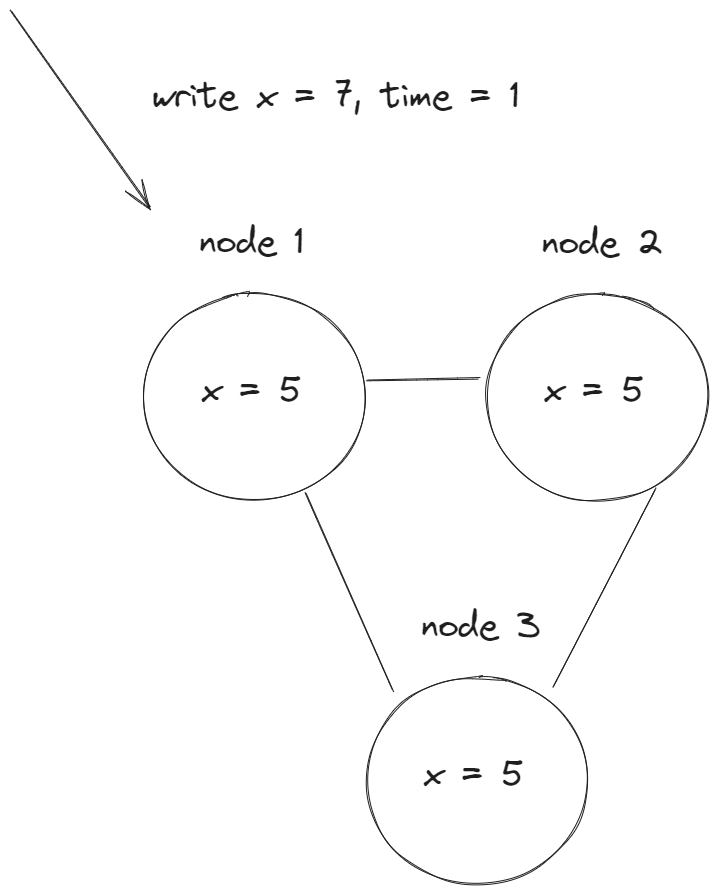
Это значение начинает постепенно обновлятся во всех репликах, но оно еще не доступно для чтения. И в этот момент времени приходят запросы на чтение, которые читают из разных реплик. В таком случае будет возвращено устаревшее значение x = 5:
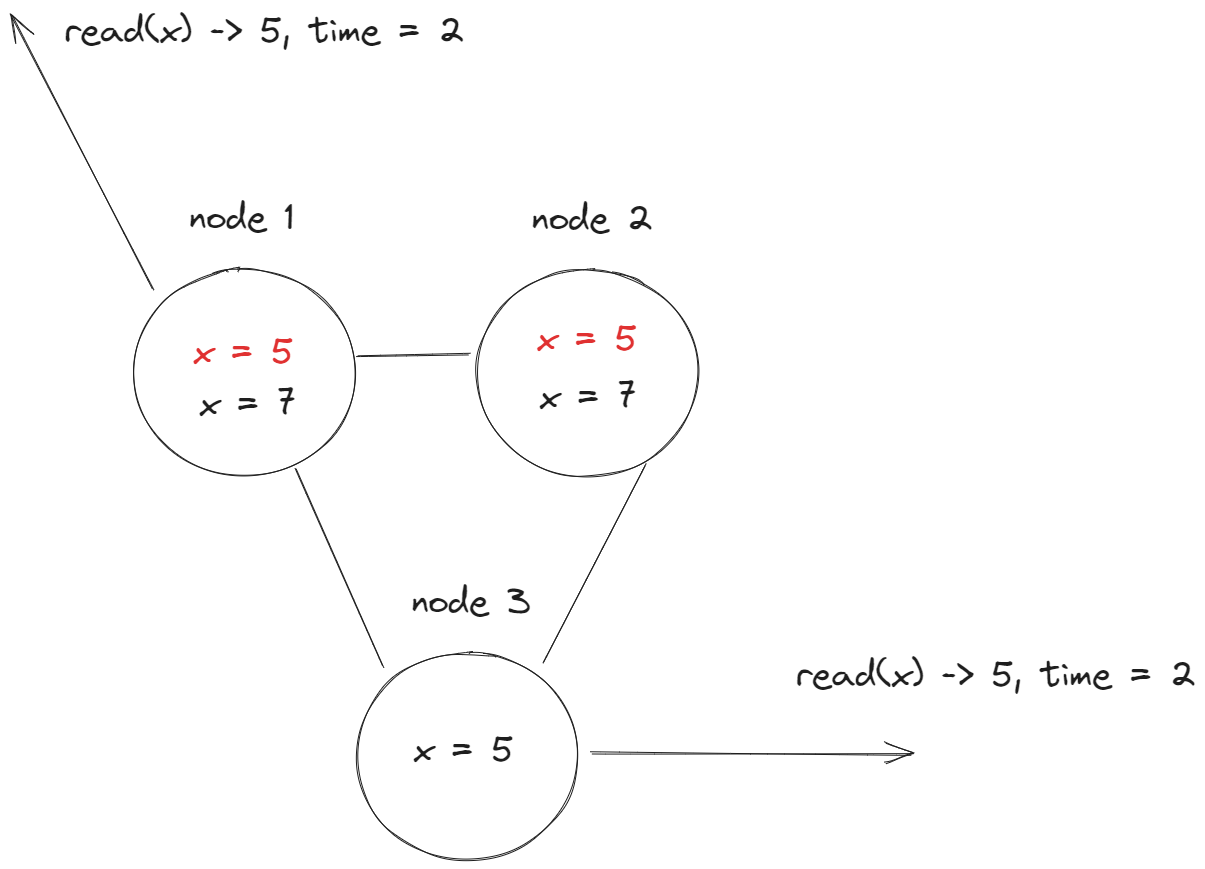
Но "в конце концов" (eventually) это значение установится в x = 7 и будет доступно для чтения: