Темная сторона Снупи
the Matrix
Ранее предлагавшиеся методы фингерпринтинга не подходят для массового анализа трафика даже с использованием только HTTPS (без Tor/VPN). Практическое массовое наблюдение требует обобщенной модели, идентифицирующей страницы независимо от контекста просмотров (браузер, ОС, количество вкладок и т. д.) и параметров сети во время сеанса.
Создание обобщенной модели, которая учитывает все возможные контексты просмотра, достаточно сложная задача. Основным препятствием для обобщения является огромное количество данных, необходимых для каждой страницы, с учетом всех возможных вариаций контекста. Например, для построения обобщенной модели для трех операционных систем и браузеров потребуется в 9 раз больше выборок трафика по сравнению со сценарием «одна система — один браузер». Более того, для достижения точности, обещаемой алгоритмами DL/ML, важно собрать достаточное количество выборок трафика для каждого сценария. Кроме того, любые изменения на сайте также требуют свежего сбора образцов трафика. Таким образом, обобщение существующих методов требует особой модели запросов, позволяющей злоумышленнику множественные обращения к сайту в течение короткого промежутка времени без риска обнаружения. Однако на практике защита от атак обнаруживает и блокирует IP-адреса, предпринимающие такие попытки, пачками и без особого напряга. Идентифицируются и блокируются IP-адреса, вызывающие аномалии в аналитике, в том числе связанные с попытками многократной выборки.
Поэтому для обхода этого препятствия ранее предполагалось наличие следующей информации:
1) Интересы пользователя. В идеале предполагается, что пользователя интересует только подмножество страниц. Однако при массовом контроле необходимо учитывать весьма широкий спектр интересов пользователей.
2) Поведение пользователя. Большинство существующих методов предполагают ограниченное поведение пользователя (просмотр страниц в одной вкладке, просмотр ограниченного числа страниц за сеанс и др.). Однако, очевидно, что такие предположения неверны в большинстве практических сценариев. Учет просмотра нескольких вкладок требует сбора данных на основе последовательности страниц, что, в свою очередь, экспоненциально увеличивает выборки трафика.
3) Предпочтения пользователя. ОС, используемый браузер, настройки кэширования, cookie. Для массовых наблюдений необходимо учитывать самые различные комбинации этих предпочтений.
4) Условия сети. В существующих практических исследованиях модели прогнозирования приведены к конкретным состояниям сети (географическое положение, провайдеры и др.).
Упрощенные методики обобщения без добавления достаточного количества данных для охвата сложных сценариев приводят к низкой точности прогноза. Ограниченное количество обучающих выборок накладывает ограничения на использование методов DL/ML. Snoopy отвечает большинству требований обобщений с учетом конечной модели запросов.
Разнообразие сетевых условий с точки зрения технических данных (джиттера, полосы пропускания и скорости отбрасывания пакетов) также влияет на фингерпринтинг. Учет этих различий по стольким факторам затруднен из-за технических ограничений. Использование файлов cookie еще больше усложнило процесс фингерпринтинга, даже для целенаправленных атак. Трекинговые cookie, используемые на сайтах, и сессионные cookie, включенные в заголовки прикладного уровня, приводят к изменению размера ресурсов. Для учета этих вариаций в предыдущих исследованиях использовались либо сложные методы (комбинации алгоритмов кластеризации, распределение Гаусса, скрытая Марковская модель и алгоритм Витерби), дополненные большими наборами данных, или упрощающие предположения о поведении пользователя.
Упрощающие методы слишком ограничивают интересы пользователей, поскольку рассматривают небольшой набор страниц, либо предполагают непрактичное поведение пользователя, такое как просмотр одной вкладки без кэширования. Также эти методы ограничены целевыми атаками и не подходят для массового наблюдения по следующим причинам:
1. Целью массового наблюдения является понимание интересов множества пользователей сайта. Следовательно, ограничительные предположения об интересах пользователей неуместны в контексте массового наблюдения.
2. Ограничительные допущения относительно поведения при просмотре (например, количество используемых вкладок, используемая ОС/браузер и конфигурация браузера) различных групп пользователей сайта также неразумны. Поэтому эти методы нельзя использовать для анализа зашифрованного трафика в массовом масштабе.
Структура Snoopy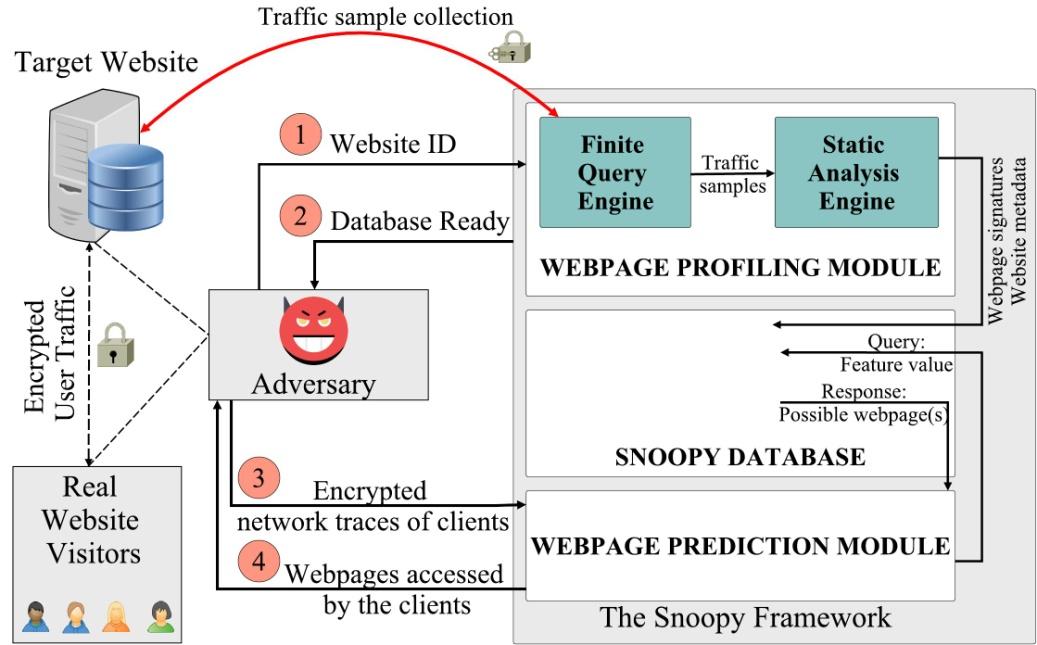
Наш антагонист — это скомпрометированное сетевое устройство на пути клиент-сервер, которое может (1) получить доступ к незашифрованным полям заголовков как пакетов управления, так и пакетов данных; и (2) наблюдать за характеристиками трафика, такими как размер зашифрованных пакетов.
Допущения и область применения
Предположения о контексте, в котором злоумышленники могут использовать Snoopy:
— не рассматриваются сайты, на которых размещается динамический или высоко персонализированный контент, например, сайты социальных сетей и поисковые системы, в качестве целей для предполагаемой атаки;
— злоумышленник не имеет возможности расшифровать трафик реальных пользователей сайта. Такая возможность гипотетически имеется у госучреждений и специалистов, имеющих полный доступ к авторизованным промежуточным узлам;
— Snoopy должен скомпрометировать сетевое устройство, имеющее доступ ко всем зашифрованным пакетам прикладного уровня, которыми обмениваются клиент и сервер в течение всего сеанса (не берем случаи динамического изменения маршрута, например, из-за ненадежности соединений).
Общий обзор
Фреймворк состоит из базы данных (Snoopy Database), предназначенной для хранения информации (фингерпринтов и дополнительных метаданных), и двух функциональных модулей: модуля профилирования (Webpage Profiling Module) и модуля прогнозирования (Webpage Prediction Module). На рис. 2 обобщенно показаны различные компоненты фреймворка и их работа.
Первичный запуск фреймворка инициирует заполнение базы данных, для чего служит модуль профилирования, запускаемый с идентификатором сайта (IP/URL), как показано на первом шаге. Функция этого модуля — сбор информации о сайте. Входными данными для него являются идентификатор сайта и набор функций, которые будут использоваться для фингерпринтинга. Изначально механизм конечных запросов в этом модуле обеспечивает целенаправленный сбор образцов трафика с целевого сайта. Впоследствии этот трафик расшифровывается, и как зашифрованная, так и расшифрованная версии образцов трафика передаются механизму статического анализа. Хотя Snoopy не требует ключей дешифрования пользователей во время атаки, ему все же необходимо расшифровывать образцы трафика, которые он генерирует самостоятельно на этапе профилирования. Это необходимо для отличия открытых ресурсов (например, HTML, JavaScript, изображений) каждой страницы от их зашифрованных аналогов.
Окончательный вывод модуля профилирования включает информацию, относящуюся:
(1) к структуре сайта;
(2) последовательности загрузки ресурсов для каждой страницы;
(3) подписи этих ресурсов;
(4) и другим соответствующим метаданным сайта, таким как возможность кэширования и информация о кукисах.
Как только база данных заполняется, фреймворк сообщает о готовности к прогнозированию, как показано на втором шаге. Модуль прогнозирования принимает в качестве входных параметров зашифрованную трассировку трафика T пользователя (третий шаг на рис. 2), и прогнозирует страницы, к которым осуществляется доступ в T, используя информацию, хранящуюся в базе данных. Предсказание выполняется в два этапа. В первую очередь извлекаются значения функций из входной трассировки T, и выполняется поиск в базе данных, чтобы получить последовательность ресурсов-кандидатов, присутствующих в T. Затем эта последовательность и метаданные используются для прогнозирования окончательного набора страниц (шаг 4 на рис. 2).
Наиболее уникальной и важной особенностью Snoopy является его способность соответствовать конечной модели запросов, сохраняя при этом возможности обобщения. Достижение такого баланса между обобщением и конечным числом запросов чрезвычайно сложно. Эта проблема решается использованием:
— функции предсказания (позволяют идентифицировать страницы в различных контекстах просмотра даже с конечным числом выборок трафика, что соответствует конечной модели запросов),
— целенаправленного сбора данных и оценки ценности функций для сбора образцов трафика с целевого сайта.
Snoopy оценивает вариации значений признаков в различных контекстах просмотра с использованием статического анализа заголовков HTTP и полезной нагрузки.
Предсказуемость фингерпринтов
Использование Snoopy требует стабильности зашифрованного трафика в различных контекстах просмотра, чтобы свести к минимуму количество выборок, необходимых при профилировании страницы. При нестабильных шаблонах, меняющихся в зависимости от состояния сети и количества открытых вкладок браузера, предсказуемость значительно падает. Snoopy использует последовательность размеров зашифрованных ресурсов в качестве отпечатка страницы. Размер зашифрованного ресурса вычисляется как сумма размеров сегментов TLS всех пакетов. Поскольку контекст просмотра у каждого пользователя индивидуален, Snoopy сначала фокусируется на понимании влияния различных контекстов просмотра на отпечаток.
В то время как некоторые факторы контекста влияют на размер зашифрованного ресурса, некоторые другие влияют на последовательность загрузки ресурсов. Анализ этих факторов помогает Snoopy статически оценивать изменения, вызванные каждым из этих факторов, тем самым устраняя необходимость сбора образцов трафика для всех возможных контекстов. Размер зашифрованных ресурсов и последовательность их загрузки изменяются в зависимости от следующих параметров:
1. Операционная система. Используемая система влияет на размер сегмента пакетов TLS несколькими способами. Во-первых, размер сегмента TLS ресурса зависит от реализации TLS в соответствующей ОС. Разные системы начинают с одной и той же записи TLS, но разбивают ее на сегменты разного размера. Хотя не ожидалось, что это повлияет на размер сегмента TLS, заметны небольшие различия при вычислении суммы размеров сегментов TLS. Более глубокий анализ показал, что количество и размер сегментов влияет на метаданные, связанные с каждым сегментом TLS, несколькими способами, которые, к счастью, предсказуемы. Во-вторых, в каждый сегмент TLS добавляются заголовки. Поэтому, если запись разбита на несколько небольших сегментов TLS, общее количество байтов заголовка TLS для всех сегментов будет больше, чем общее количество байтов заголовка TLS, добавленных в случае, если запись была разбита на меньшее количество больших сегментов. В-третьих, переменное поле в заголовке HTTP, а именно строка UA, содержащая имя ОС, также влияет на размер записи TLS.
2. Браузер. Имя браузера косвенно влияет на размер сегмента TLS, поскольку оно также является частью строки пользовательского агента. Поскольку разные имена браузеров имеют разную длину, они влияют на длину строки UA, что, в свою очередь, приводит к изменению размеров записей TLS.
3. Последовательность просмотра, с которой пользователь просматривает страницы, влияет как на размер записи TLS, так и на последовательность загрузки ресурсов (кэширование, cookie).
— Кэширование: когда пользователь посещает страницу, содержащую ранее загруженный ресурс, ресурс не загружается, если включено кэширование, что приводит к изменению последовательности загрузки ресурсов. Например, если пользователь посещает страницу WX (состоящую из ресурсов r1 и r2), за которой следует страница WY (состоящая из ресурсов r1 и r3), общая последовательность загрузки ресурсов будет следующей: r1-r2-r3. С другой стороны, если бы кэширование было отключено, это привело бы к следующей последовательности: r1-r2-r1-r3.
— Cookie: когда пользователь разрешает сайту использовать cookie, сервер отправляет файл cookie в заголовке HTTP вместе с первым ресурсом, доставленным во время сеанса. Добавление файла cookie увеличивает размер записи TLS для первого ресурса. Следовательно, ресурс будет иметь больший размер записи TLS, если он загружается в начале сеанса. Кроме того, отслеживающий cookie влияет на размер полезной нагрузки передаваемого ресурса. Такие cookie содержат информацию о поведении пользователя при просмотре, такую как URL ранее просматриваемых страниц в сеансе. Поскольку URL разной длины, изменение размера записи TLS из-за cookie зависит от страницы, посещенной пользователем в последний раз. Кроме того, трекинговые cookie содержат нулевое значение для первого ресурса, доставленного во время сеанса просмотра.
Опять же, это приводит к изменению размера записи TLS в зависимости от последовательности просмотра пользователем. Например, если размер ресурса r1 равен s1, а размер cookie — sc, то размер записи TLS для r1 будет (s1 + sc), если r1 — первый загружаемый ресурс. С другой стороны, если r1 загружается после того, как пользователь посетил страницу с длиной URL tc (а также размером отслеживающего cookie) в сеансе просмотра, размер записи TLS для r1 будет (s1 + tc).
4. Протокол прикладного уровня. Группа пакетов, составляющих ресурс, имеет решающее значение для вычисления размера зашифрованного ресурса. Для HTTP/1.x пакеты, принадлежащие ресурсу, имеют один и тот же номер TCP ACK, что упрощает процесс. Однако для сайтов HTTP/2 и HTTP/3 это не одно и то же из-за конвейерной обработки и многопоточных операций сервера.
При многопоточности пакеты, принадлежащие двум разным ресурсам, могут чередоваться в одном и том же потоке TCP (в HTTP/2) или потоке QUIC (в HTTP/3). Чтобы справиться с такими сложными сценариями, фреймворк вычисляет размеры зашифрованных ресурсов на сайтах HTTP/2. Для сайтов HTTP/3 он отбрасывает пакеты установления соединения QUIC, чтобы протокол связи возвращался к HTTP/1.1 или HTTP/2.
5. Параллельные вкладки. Просмотр параллельных вкладок влияет на последовательность загружаемых ресурсов. Например, когда пользователь просматривает две страницы, скажем, WX и WY одну за другой в одной вкладке, сначала загружаются ресурсы WX, а затем ресурсы WY. С другой стороны, если пользователь открывает две страницы в двух параллельных вкладках браузера, ресурсы WX и WY будут загружаться чередующимся образом. В таких случаях злоумышленник сталкивается с дополнительной проблемой определения последовательности загрузки ресурсов, соответствующей каждой странице, из чередующейся последовательности зашифрованных ресурсов, что усложняет процесс прогнозирования.
6. Сетевые условия. Перегруженность канала приводит к задержкам передачи пакетов, отбрасыванию пакетов и блокировке новых подключений. Отбрасывание пакетов значительно влияет на зашифрованный размер ресурсов. Отброшенные пакеты могут передаваться или не передаваться повторно в зависимости от характера ресурса. В случае повторной передачи пакеты можно легко собрать с помощью диссекторов сетевых протоколов.
Следовательно, вычисление размера зашифрованного ресурса в этом случае не затрагивается. Однако в редких случаях, когда большое количество отброшенных пакетов не передается повторно или приводит к разрыву соединения, Snoopy не может правильно вычислить или предсказать размер ресурса. Серьезная перегрузка сети также может привести к колебаниям маршрута. В этом случае получить доступ к полной сетевой трассировке невозможно без контроля нового маршрута. Snoopy не сможет справиться с такими обстоятельствами.
В этом топике мы кратко рассмотрели фреймворк, пригодный для массового фингерпринтинга, существующие проблемы и ограничения массового наблюдения с помощью фреймворка Snoopy, потенциально способного к раскрытию детальной конфиденциальной информации большого числа пользователей на основе их действий в сети.
Основной задачей написания этой статьи, я считаю, освещение того факта, что средства отслеживания действий пользователей в сети не стоят на месте, при учете того, что право на конфиденциальность еще никто не отменял. В следующей статье немного подробней рассмотрим работу фреймворка Snoopy, а пока пусть пребудет с вами приватность и конфиденциальность)))!
P.S. «Если ты не параноик, это еще не значит, что за тобой не следят»!

НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Источник
 Наши проекты:
Наши проекты:
- Кибер новости: the Matrix
- Хакинг: /me Hacker
- Кодинг: Minor Code
👁 Пробить человека? Легко через нашего бота: Мистер Пробиватор