Технология параллельного программирования OpenCL
KOD
1. Введение
OpenCL (Open Computing Language ) это спецификация, описывающая технологию параллельного программирования, которая в первую очередь ориентирована на GPGPU. Изначально она была разработана компанией Apple, в последствии для развития спецификаций OpenCL был образована группа разработчиков Khronos Compute [2], в неё вошли Apple, nVidia, AMD, IBM, Intel, ARM, Motorola и др. Первая версия стандарта была опубликована в конце 2008 года.В отличии от nVidia CUDA, AMD Stream и т.п., в OpenCL изначально закладывалась мультиплатформенность, т.е. OpenCL программа должна без изменений в коде работать на GPU разных типов (разных производителей). Такая программа без изменений должна работать даже на CPU без GPU, хотя в этом случае она может выполняться существенно медленнее чем на GPU.
2. Схема работы с аппаратурой
Итак - хотим мультиплатформенность и желательно без существенных потерь в производительности. Достигается этот результат следующим образом [3,4].OpenCL-программа работает с т.н. платформами (platform). Платформа это программный пакет, который поставляется соответствующим разработчиком аппаратных средств. Например "AMD Accelerated Parallel Processing" или "Intel OpenCL". При этом несколько платформ могут работать одновременно на одной машине.
Каждая платформа включает в себя ICD (Installable Client Driver) -- программный интерфейс OpenCL для работы с устройствами, которые эта платформа поддерживает.
В среде Linux список ссылок на ICD, присутствующих в системе, обычно хранится в каталоге /etc/OpenCL/vendors/, а библиотека libOpenCL.so выполняет роль диспетчера (ICD loader), т.е. она направляет вызовы OpenCL функций на устройства, через соответствующие ICD.
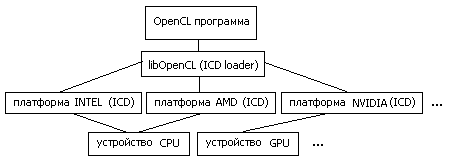
Рис.1: схема работы OpenCL программы с аппаратурой
На машине с процессором Intel Core2 CPU 6300 и графическим ускорителем nVidia Quadro FX1700, развернуты три платформы OpenCL: nVidia, AMD, Intel. При этом платформа nVidia поддерживает только GPU Quadro FX1700, а платформы AMD и Intel - только Intel Core2 CPU 6300 в качестве вычислительного устройства. Таким образом каждая платформа содержит одно вычислительное устройство.
Тут надо ещё сказать о версиях OpenCL SDK. При развёртывании платформы на компьютере необходимо уточнить версию пакета. Например, в процессе проведения экспериментов выяснилось, что Intel OpenCL SDK 2014 не поддерживает работу с процессором Intel Core2 CPU 6300, который был установлен на машине. Проблема решилась установкой более старого пакета Intel OpenCL SDK 2012.
3. Структура OpenCL-программы
В OpenCL (аналогично CUDA), программа разделяется на две части: первая часть - управляющая, вторая - вычислительная. В роли управляющего устройства ( host) выступает центральный процессор (CPU), вычислительное устройство ( device) выбираем из списка платформ и их устройств. Обычно используется GPU, но не обязательно, это может быть и тот же CPU.Код, который должен выполняться на device, оформляется специальным способом. Поскольку device могут быть от разных производителей и разных типов, то скомпилировать один бинарник для всех не получится. Решается эта проблема следующим образом.
Текст ядра (kernel), т.е. части программы выполняемой на device, включается в основную часть программы (выполняемой на host) в "чистом" виде т.е. в виде текстовой строки. Этот исходник компилируется средствами OpenCL непосредственно в процессе работы программы (runtime) для выбранного в данный момент вычислительного устройства, это происходит каждый раз при запуске OpenCL-программы.
Так же есть возможность, скомпилированный таким образом, код ядра сохранить и при инициализации вычислительной программы загружать готовый бинарник. Но в этом случае мы теряем универсальность, этот код будет работать только на одном (данном) типе устройств.
Далее рассмотрим общую структуру OpenCL-программы. Она выглядит более сложной чем аналогичная программой CUDA, поскольку необходимо выполнять дополнительные действия по конфигурированию среды выполнения и подготовке кода для device. Эта среда в терминах OpenCL именуется контекстом (context), она включает в себя платформу (platform), вычислительные устройства (device) и буферы памяти для них. Для device в рамках context создаётся очередь команд на исполнение (command queue). Операции с device, такие как чтение/запись данных и запуск ядра, помещаются в эту очередь и последовательно исполняются.
4. Пример OpenCL-программы
В качестве первого примера рассмотрим простую вычислительную задачу: С := d * A + B, где d - константа, А,В и С векторы заданного размера. __kernel
void kernel1(const float alpha, __global float *A, __global float *B, __global float *C) {
int idx = get_global_id(0);
C[idx] = alpha* A[idx] + B[idx];
}
Программа запускает много (по количеству элементов векторов) параллельных процессов (тредов) на device, каждый тред получает свой номер (get_global_id), исходя из него считывает свою часть данных из глобальной (__global) памяти device, выполняет вычисления и записывает свою часть результата обратно в память.
Для сравнения напишем ещё простую (последовательную) программу и сравним время затраченное на вычисления. Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
платформаустройствовремя(ms)NVIDIAQuadro FX 17003.2AMDIntel Core2 CPU 6300 19.1IntelIntel Core2 CPU 6300 11.0- Intel Core2 CPU 6300 9.3
Наилучший результат для CPU показала простая программа, что можно объяснить эффективной работой компилятора и отсутствием необходимости выполнять дополнительные процедуры OpenCL.
5. Группы процессов и их конфигурация
Каждое вычислительное устройство обладает своими ограничениями по количеству одновременно выполняемых тредов, и хотя их общее количество в программе может быть велико, выполняться они будут частями или группами, максимальный размер группы зависит от конкретного устройства.Иногда треды удобно формировать в виде решетки. Рассмотрим пример задачи умножения матриц.
// конвертер индексов матрицы в линейный адрес
#define IDX2LIN(i,j,l) (i+j*l)
__kernel void myGEMM1(const int M, const int N, const int K,
const __global float* A, const __global float* B, __global float* C)
{ // номер треда (2D решетка)
const int r = get_global_id(0); // строка 0..M
const int c = get_global_id(1); // столбец 0..N
// вычисляем элемент [r,c] результирующей матрицы C
float acc = 0.0f;
for (int i=0; i<K; i++) {
acc += A[ IDX2LIN(r,i,M) ] * B[ IDX2LIN(i,c,K) ];
}
C[ IDX2LIN(r,c,M) ] = acc; // сохраняем результат
}
Имеем на входе матрицы A[M*K], B[K*N] и соответственно буфер для результата C[M*N]. Программа создаёт M*N тредов в виде решетки MxN, каждый тред [r,c] отрабатывает одну ячейку в матрице результата.
Для сравнения напишем ещё простую (последовательную) программу и сравним время затраченное на вычисления. Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
Результаты несколько расстраивают, поскольку из таб.2 видно, что GPU показала наихудший результат. Проблема в крайне неэффективном использовании памяти GPU. Далее мы исправим это затруднение.
6. Модели памяти и синхронизация процессов
Модель памяти OpenCL имеет несколько типов. Рассмотрим их подробней : global, local, private.
- Память global - основная память уcтройства, самая большая по размеру (512MB для FX1700) и самая медленная, она является общей для всех тредов.
- Память local - общая память для одной группы тредов (shared в терминах CUDA), этот тип быстрее global но существенно меньше по размеру (16KB для FX1700)
- Память private - память треда, быстрая но маленькая (8KB для FX1700)
Вернёмся к предыдущему примеру с умножением матриц. В процессе работы ядро выполняет много повторных чтений из памяти global. Попробуем сократить количество чтений с помощью организации быстрого кэша.
// размер кэша тредов
#define TS 16
// конвертер индексов матрицы в линейный адрес
#define IDX2LIN(i,j,l) (i+j*l)
__kernel void myGEMM2(const int M, const int N, const int K,
const __global float* A, const __global float* B, __global float* C)
{
// 2D номер треда в группе
const int r = get_local_id(0);
const int c = get_local_id(1);
// номер ячейки в матрице результата
const int gr = get_group_id(0)*TS + r; // 0..M
const int gc = get_group_id(1)*TS + c; // 0..N
// общий кэш для тредов группы
__local float Asub[TS][TS];
__local float Bsub[TS][TS];
float acc = 0.0f; // результат работы треда
for (int t=0; t<K/TS; t++) { // цикл по всем блокам матриц
const int tr = t*TS + r;
const int tc = t*TS + c;
// загружаем блоки в кэш
Asub[c][r] = A[ IDX2LIN(gr,tc,M) ];
Bsub[c][r] = B[ IDX2LIN(tr,gc,K) ];
barrier(CLK_LOCAL_MEM_FENCE); // ждём пока треды группы заполнят общий кэш
// вычисляем
for (int k=0; k<TS; k++) { acc += Asub[k][r] * Bsub[c][k]; }
barrier(CLK_LOCAL_MEM_FENCE); // ждём пока треды группы завершат вычисления
}
C[ IDX2LIN(gr,gc,M) ] = acc; // сохраняем результат
}
Имеем на входе матрицы A[M*K], B[K*N] и соответственно результат C[M*N]. Программа создаёт M*N тредов в виде решетки MxN, группами размера TSxTS, каждый тред отрабатывает одну ячейку в матрице результата, группа тредов кэширует блоки исходных матриц и далее выполняет операции с этим кэшем.
Для того, что бы кэш корректно был заполнен необходима синхронизация группы тредов (barrier), достигая barrier программа ждет, пока все треды группы соберутся в этой точке и только после этого продолжает выполнение.
Из таблицы 3 видно, что модифицированная программа умножения матриц (gemm2) показывает вполне удовлетворительный результат производительности, работая гораздо быстрее первого варианта (gemm1).
7. Заключение
Хотя программы OpenCL могут выполняться с меньшей скоростью в сравнении с CUDA, но они обладает важным свойством - переносимость, этот стандарт имеет хорошие перспективы развития.