"Sun'iy intellekt bu judayam oddiy" - ChatGPT evolyutsiyasi haqida
Techno Ways 2024 g'olibi Jalilov ShamshodbekSo‘ngi kunlarda yangiliklarda sunʼiy intellektni yangi cho‘qqilarni zabt etgani va qaysidir odamlar guruhini ishsiz qolib ketishi haqida xabarlarga to‘qnash kelish odatiy holga aylanib qoldi. Bir vaqtni o‘zida, judayam kam sonli odamlar sunʼiy intellekt o‘zi nima va dong‘i ketgan ChatGPT neyrotarmog‘i qanday ishlashini tushunishadi.
Shunday ekan, qulayroq joylashib oling, bugun siz bilan ushbu maqolada maktab bolasi ham tushunadigan tilda sunʼiy intellekt qanday ishlashi haqida gaplashamiz.

T9: til modulining siri fosh bo'ldi:
Keling oddiy narsadan boshlaylik. ChatGPT o'zi nima ekanini bilish uchun oldin u nima "emas" ekanligini bilishimiz lozim. U "Tirik mashina", "Altron", "Jarvis" yoki "Temir xotin" ham emas. Qo'rqinchli haqiqatni eshitishga tayyor bo'ling: ChatGPT aslida sizning telefoningizdagi T9, ammo kuchli steroidlar qabul qilgan holati. Ha, bu rost, dasturchilar ushbu texnologiyani "Til modullari" (Language Models) deb atashadi. Ularni asosiy imkoniyati esa siz bergan matndagi ohirgi so'zdan keyin qanday so'z kelishini bashorat qilishdir.
Agarda aniqroq qilib aytsa, eski tugmali telefonlarni eslang (o'sha siz bilgan joni qattiq Nokia 3210 kabilar), ushbu telefonlarda T9 yozayotgan so'zingiz qanday so'zligini tushunib uni tezroq yozishga imkon berardi. Ammo texnologiya rivojlandi va 2010 yillarga smartfonlar rusumga kirishi bilan naqafat yozilayotgan so'zni balki oldingi so'z asosida keyingi so'zlarni va xatto tinish belgilarni taklif qila oladigan texnologiya kashf qilindi.
Shunday qilib, T9/ChatGPT ning asosiy vazifasi keyingi keladigan so'zni bashorat qilishdir. Ushbu texnologiya "Til moduli" deb ataladi va yagona maqsadi yozilgan gap mazmunidan kelib chiqib keyingi so'z nima bo'lishi mumkin ekanini taxmin qilishdir. Bunday bashoratni amalga oshirish uchun esa kapot ostida u yoki bu so'zni kelishi kerakligi ehtimolligini hisoblaydigan asos kerak. Chunki agarda T9 tasodifiy so'zlarni taklif qilganda haqiqiy atala chiqqan bo'lardi gapingizdan.
Keling misol uchun tasavur qilamiz, do'stingiz sizga "Do'stim bugun nima bilan bandsan?" degan savol berdi va unga javoban siz yozib boshlayabsiz "Bugun kasalman, shunga buguncha faqat uyda...", va mana shu yerda T9 o'yinga qo'shiladi. Agarda siz gapizni qandaydir taxminiy so'z bilan masalan "Panda" so'zi bilan to'ldirmoqchi bo'lsangiz bu uchun sizga hech qanday til moduli kerakmas. Bu holatda telefoning qandaydir mantiqliroq "yotaman", "qolaman", "uxlayman" kabi mantiqiy takliflarni bergan bo'lardi.
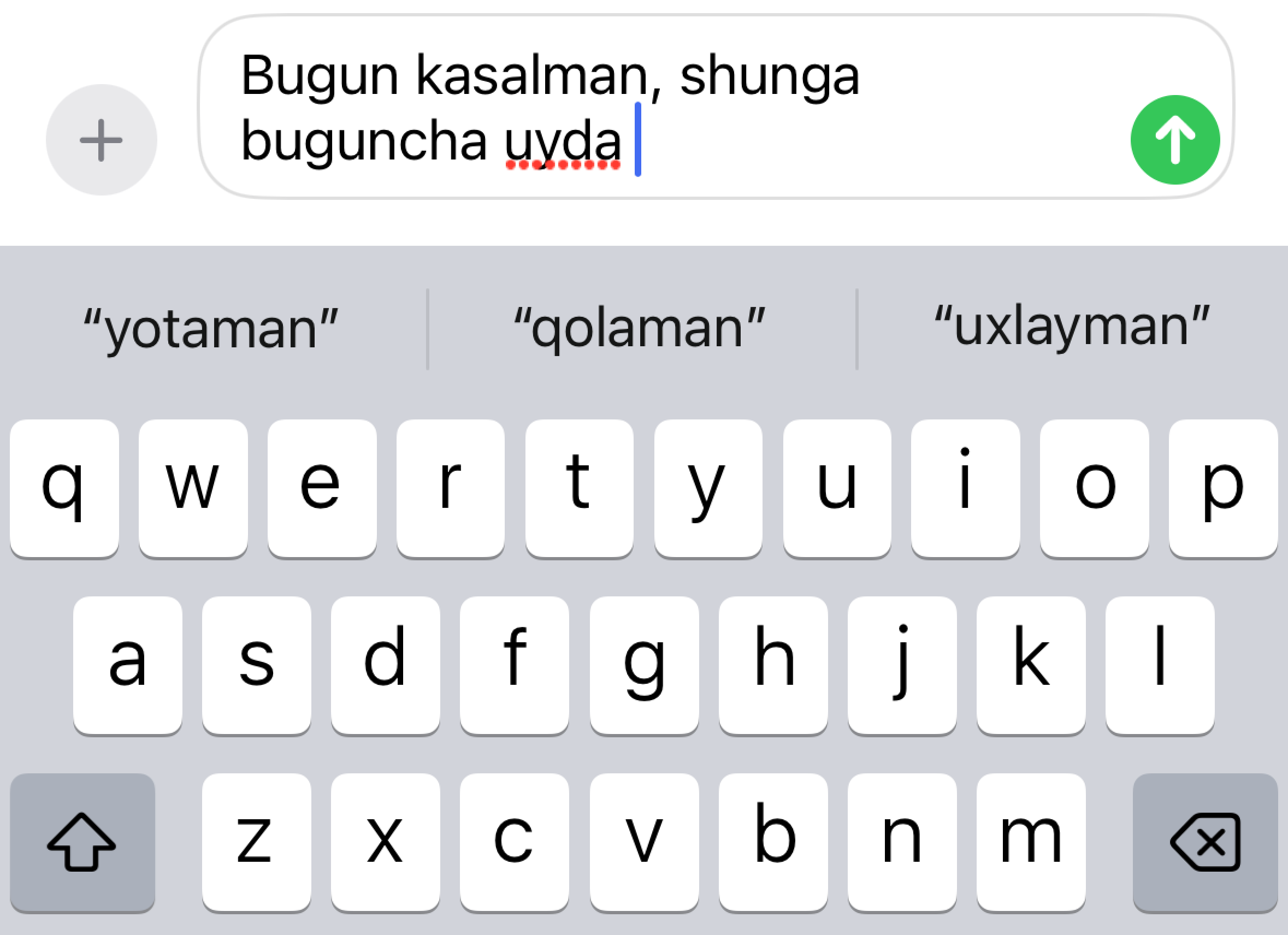
Hop endi T9 ma'lum gapdan so'ng qanday qilib aynan shu so'zlar kelishini bilib taklif qilayotgani va boshqa so'zlarni taklif qilish xato bo'lishini taxmin qilayotganini tushunish uchun eng sodda neyrot tizim ishlashini o'rganishimiz zarur.
Neyron tizim qayerdan so'zlar ehtimolligini olyabdi?
Bu savolga javob berish uchun keling oldin o'zi u yoki bu narsa bir biri bilan qanday bog'lanishi mumkinligini tushunib olaylik. Keling oldimizga bir vazifani qo'yamiz, aynan esa odamni bo'yidan kelib chiqib uni vaznini taxmin qilamiz.
Mantiqiy jihatdan hayolizga bo'y va vaznlarni o'zida saqlagan statistik ma'lumotlar jadvalini to'plash kelishi kerak(iloji boricha 1000 dan oshiq bo'lgan va soddalik uchun bir jinsdagi). Undan so'ng ular orasidagi bog'liqlikni aniqlash uchun matematik modulni topib olishimiz zarur bo'ladi.
Tasvirlash uchun keling bizdagi ma'lumotlarni grafikka tushirib X - o'qqa bo'yni, Y - o'qqa esa vaznni qo'yaylik.
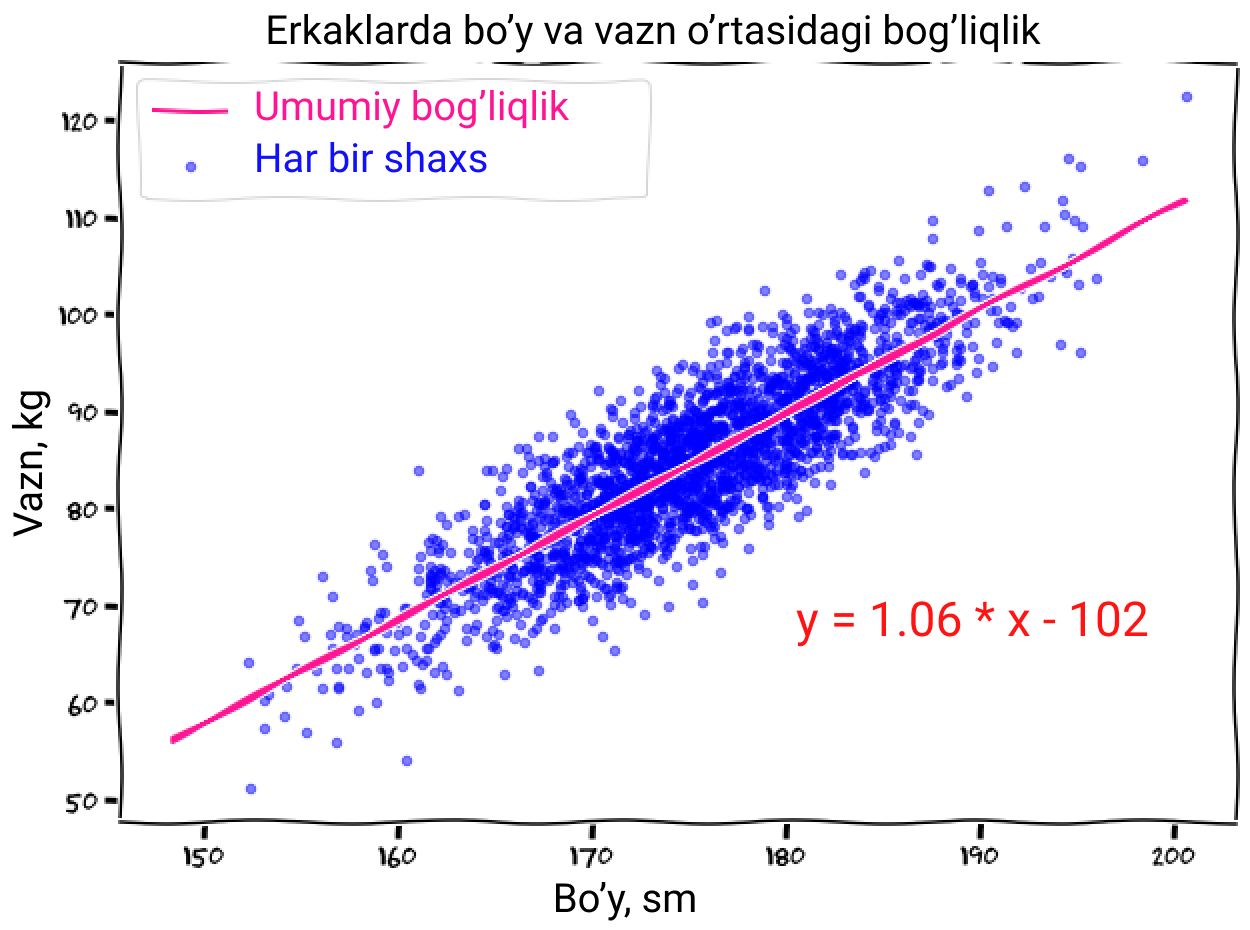
Qurollanmagan ko'z bilan qarashdan ham ma'lumki qancha odamni bo'yi baland bo'lsa shuncha uni vazni ko'p bo'ladi (rahmat Bilmasvoy). Uni topish uchun esa oddiy chiziqli regressiya formulasi, y = k * x - b dan foydalanish mumkin (grafikka e'tibor qilmaganlar uchun k= 1.06 va b = 102). Shunday qilib vazning(y) ni topish uchun bo'yingizni x o'rniga qo'yib ko'ring.
Taxminan hayolingizdan o'tgan narsa: "Ha bu oddiyku, buni til modullariga nima aloqasi bor?". Gap shundaki til moduli ham shu kabi formulalar jamlanmasi hisoblanadi.
Oddiyroq qilib aytsa T9/ChatGPT oldingi kelgan so'zlar(x) yordamida keyingi keladigan so'z (y) ni topadi. Endi asosiy masala aynan o'sha koeffesiyentlar(k,b) ni aniqlashimiz kerak. Ammo ChatGPT da bunday parametrlar soni judayam ko'p. Bunday semiz modullarni biz "Katta til modullari" (LLM) deb ataymiz.
Agarda hali keyingi so'zni bashorat qilishni ChatGPT dagi kattakon matnlar yozish bilan qanday aloqasi borligini tushuna olmagan bo'lsaz, miyyazni qizdirmang. Unda ham o'xshash jarayon oldin bir so'zni keyin undan keyin keluvchi so'zni bashorat qilish yotibdi. Yani u biror gapni tuzib olganidan so'ng uni yana o'ziga berib undan keyingi so'zni topib olyabdi. Natijada bog'langan manoli gap kelib chiqyabdi.
Barak paradoksi yoki sunʼiy intellektga ijodkorlik nega kerak?
Gap shundaki til moduli nafaqat bir so'zdan keyin kelishi kerak bo'lgan aniq bir so'zni, balki uni o'rnida ishlatish mumkin bo'lgan boshqa so'zlar variantlarini ham topadi. Bu narsa nega kerak? Nega faqat bitta yagona to'g'ri so'z bo'lishi bu xato? Keling bu narsani tushunish uchun bir o'yin o'ynaymiz.
Qoida quyidagicha: siz o'zizni til moduli sifatida tutasiz va men sizga gapni to'ldirish vazifa sifatida beraman - "44-AQSh prezidenti(birinchi Afro-amerikalik) bu - Barak ...", nuqtalar o'rniga hayolizga kelgan birinchi so'zni qo'ying va aynan shu so'z bo'lish ehtimolligi haqida o'ylab ko'ring.

Agarda siz nuqtalar o'rnida 100% ehtimollikda "Obama" deb javob bergan bo'lsaz tabriklayman - siz xato qildingiz! Gap shundaki rasmiy hujjatlarda Barak ismidan so'ng uning familiyasi - "Husayn"(Hussein) keladi. Shunday ekan bizning sun'iy intellekt 90% ehtimollikda "Obama" va 10% holatda "Husayn" variantnini saqlash kerak ("Husayn" dan so'ng 100% ehtimollikda "Obama" keladi).
Endi qiziq joyiga yetdik, demak sun'iy intellekt huddi narda toshini tashagan kabi turli so'zlarni tanlab ijodkorlik qilish imkoniyati bor ekan. Ammo bu degani har bir so'zni tanlanish ehtimolligi teng degani emas. Ularni foizlari sun'iy intellektni o'qitish vaqtida olgan ma'lumotlaridagi hisob kitob parametrlariga bog'liqdir (huddi yuqorida chiziqli regressiyada turli koeffitsiyent olganimiz kabi).

Shunday ekan bitta sun'iy intellekt bitta so'rovga turli javoblar berish imkoniyatiga ega - huddi odam kabi. Umuman ob aytganda olimlar neyron tizimni 100% ehtimollikda faqat eng to'g'ri bitta so'zni tanlashga majbur qilib ko'rishgan. Ha, mantiqan to'g'ri qaror bo'lishi mumkin, ammo amalda judayam bunday sun'iy intellektlar judayam sifatsiz ishlagan. Lekin yuqoridagi taxminlarga asoslangan ishlashi esa undagi ijodkorlik xususiyatini uyg'otib javoblar variatsiyasini boyitish imkonini bergan.
Umuman olganda til masalasi juda ham murakkab narsa, bazi hollarda qandaydir qoidalarga ega bo'lsa bazi hollarda esa o'zi shu qoidani buzadi. Bu narsalar odam ulg'ayish ta'lim olish va muhitga qarab sayqallanib boradi. Masalan quyosh bu nima degan savolga maktab o'quvchisi, fizik va savodsiz inson har xil jumlalar va ton bilan javob berishadi.
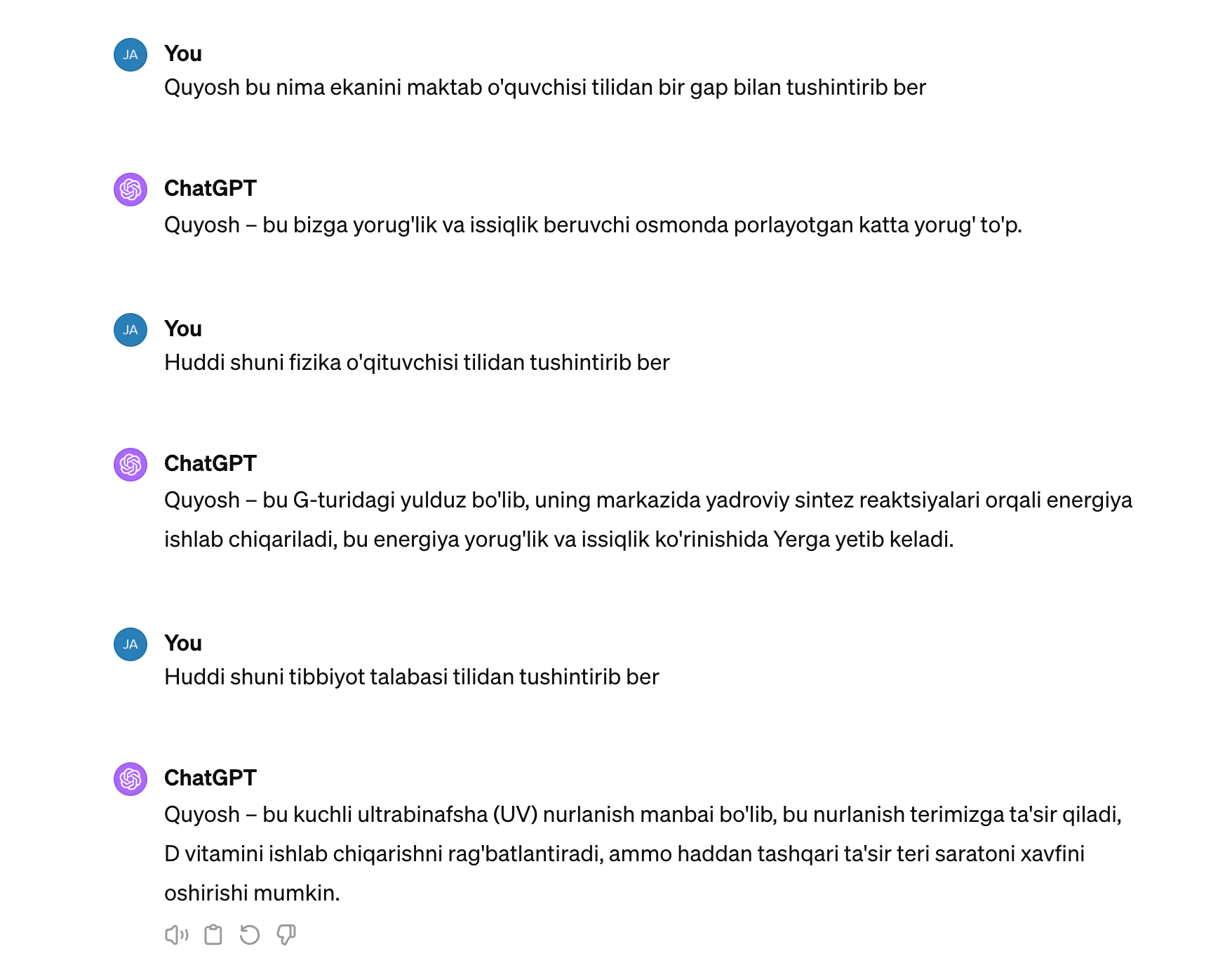
Shunday ekan, yaxshi til moduli shu barcha variantlarni o'zida saqlashi lozim. Shunda u holatdan kelib chiqib har biriga javob bera oladi.
Qisqa xulosa: hozirgacha biz 2010-yildan beri smartfonlardagi T9 avto to'ldirish til moduli bilan tanishdik, uning asosida esa bir so'zdan keyin qaysi so'zni kelishni hisoblay oluvchi ehtimollik formulalari mavjud ekan.
2018-yil: GPT-1 til modullarini transformatsiyasi
Nixoyat zerikarli T9 bilan bog'liq mavzuni yopib ChatGPT oilasining eng dastlabki a'zosi haqida gaplashamiz.
GPT - so'zini kengaytmasi bu "Generative Pre‑trained Transformer" bo'lib manosi "Matn yaratishga o'rgatilgan transformer"ga to'g'ri keladi. Transformerlar 2017-yilda Google tomonidan kashf qilingan neyron tizimi arxitekturasi bo'lib, aynan u tufayli video, musiqa va rasmlarga ishlov berish imkoniyati paydo bo'ldi.

Transformer - bu universal hisoblash moduli bo'lib, ma'lum kiruvchi ma'lumotlarni qabul qiladi va ichki algoritmlar asosida qayta ishlab mutloq boshqa chiquvchi ma'lumotlarni generatsiya qila oladi.
Aynan transformerlardagi modullarni bloklash orqali judayam katta miqdordagi ma'lumotlarni sun'iy intellektga o'rgatish imkoniyati paydo bo'ldi. Shuningdek shu vaqtgacha bo'lgan til modullari undan oldingi so'zga asoslanib xulosa qila olardi natijada gapni boshidagi so'zlar bilan ohiridagi so'zlar orasida bog'lanishni saqlab qolish imkoniyati bo'lmasdi, ammo transformerlar bu muammoni ham hal qilib gapni har bir bo'lagi orasida bog'liqlikni saqlab qolish imkoniyatini berdi.
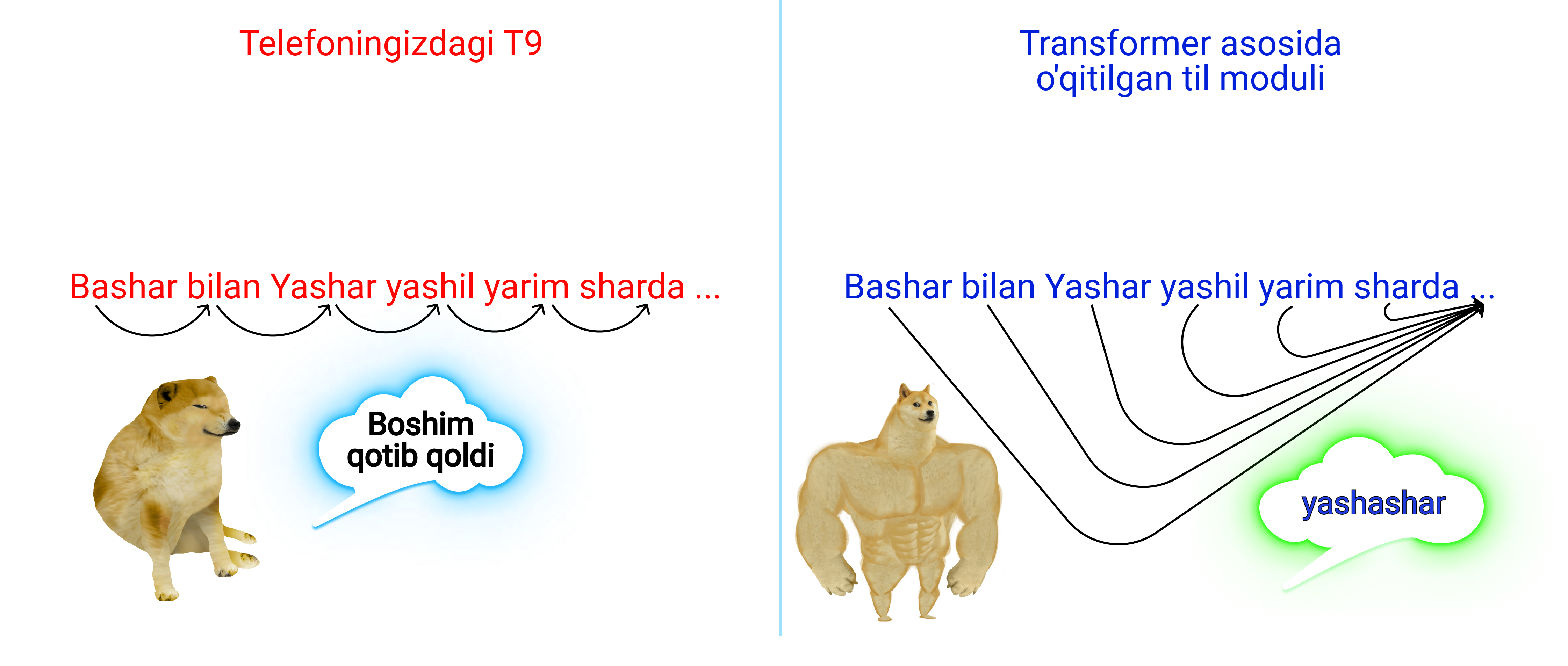
2019-yil: GPT-2, yoki qanday qilib til moduliga 700 000 Sheksperni yodlatish mumkin
Agarda siz sun'iy intellektga chixuaxua va keksni rasm orqali farqlashni o'rgatmoqchi bo'lsangiz buning uchun, "mana senga 100500 kuchuk va pishiriqni rasmi, o'zing o'rganvol" deb bo'lmaydi. Siz uni bunga o'rgatish uchun har bir rasmizni bu "paxmoq" bu esa "shirin" deb belgilab berishiz zarur bo'ladi.

Lekin sun'iy intellektni o'qitishda qulay tomoni shunda mana senga Alisher Navoiy kutubxonasi kirib mustaqil o'rgan ham deyish mumkin. Shunda u huddi maktab o'quvchisi kabi qandaydir ketma ketlikda ma'lumotlarni o'zlashtira boshlaydi. Mantiqan qarasak, biz shunchaki bir so'zdan keyin keladigan boshqa so'zni taxmin qilishinigina hohlayabmiz. Bizda odam tomonidan yozilgan har qanday gap bu ma'lum so'zlar ketma ketligidan iborat suniy intelektga o'qitish mumkin bo'lgan jumladir. Demak biz bir dunyo ma'lumot tiqsak unda ham bir dunyo so'zlar ketma ketligi bo'ladi.
Endi GPT-1 ga qaytamiz, biz transformerlarni yaratib olgandik, u esa judayam katta ma'lumotlarni o'zlashtira olayotgandi. Endi nima qilamiz? Aynan "Endi bildim, yeyish kerak" naqliga ham 2019 yilda Open AI kompaniyasidagilar amal qildi.
Umuman ob aytganda Open AI qilgan asosiy ishi: 1. Shug'ullanish uchun ma'lumotlar bazasini(dataset) va 2. Modul hajmini(parametrlar) oshirdi.
Lekin hech qayerdan bunchalik ko'p, ochiq, tartiblangan, elektron shakldagi matnlar bazasi mavjud emasdi. Shunda Open AI dagilar biroz ayyorlik qilishadi va "Reddit" deb nomlangan ingliz tilidagi online forumdagi barcha 3 tadan oshiq "like" yiqqan barcha giperhavolalar(matnlar) ni yuklab olishdi. (Ha bu hazil emas, zo'rku axir). Bunday havolalar soni 8 mln undagi matnlar hajmi esa 40 GB ni tashkil etadi.
Bu kammi yoki ko'p? Agarda Uilyam Shekspirning barcha asar drama, sonet va poemalarini yig'sak 850000 so'zdan iborat bo'ladi. O'rtacha har bir betga ingliz tilida 150 ta so'z sig'ishi mumkin va muallifning 2800 varoqli kitobi kompyuterda taxminan 5,5 mb hajmni egallashi mumkin. Bu esa GPT-2 ning olgan bazasidan deyarli 8000 barobar kichkina degani. Unchalik yaxshi tasavur qila olmayotgan bo'lsaz keling bunday tushintiraman: odam odatda bir betni 1 daqiqada o'qiydi, va xatto siz 24 soat uxlamasdan, ovqatlanmasdan o'qisangiz ham GPT-2 ga yetib olish uchun sizga 40 yil zarur bo'ladi.

Lekin shuni o'zi yetarlimi? Afsus yo'q! 5 yoshli bolaga ham Eynshteynning nisbiylik nazariyasi haqidagi kitobini tutib qo'ysak undagi biror narsani tushunishiga umid qilish qiyin. Demak ma'lumotlar bazasi miqdoridan tashqari yana bir masala bor, bu esa uning murakkabligidadir(hajmi). Ho'sh murakkablik nima bilan o'lchanadi?
Nega til modullari orasida "Velikan" hajmlar qadrlanadi?
Yuqorida siz bilan eng sodda til modulini y = k * x+b formulasi yordamida ishlatgandik. Unda biz X kiruvchiga asosan Y ni bashorat qilishga harakat qilgandik. Bu ikki parametrli modul edi (ya'ni k va b).
Endi bir Vangalik qilib taxmin qilib ko'ringchi 2019-yilgi GPT-2 da bunday parametrlar miqdori qancha? Yuz ming? Bir necha million? Ko'proq qo'shavering. Ular ishlatgan formuladagi parametrlar miqdori bir yarim milliard(15000000000) edi. Agarda shunchaki formulalarni o'zini kompyuterga yozganimizda ham uni hajmi 6 GB bo'lgan bo'lardi. Bir tomondan bu unga kiritilgan matnlar hajmidan(Redditdan yig'ilgan 40 GB matnlar) dan ancha kam, ammo o'ylab ko'ring, modul uni so'zma so'z yodlashi shart emas, balki so'zlar orasidagi bog'liqlikni tushunib olishi zarur edi.
Ushbu bog'liqliklarni(parametrlarni) olimlar "vazn" yoki "koeffisiyent" deb ham atashadi. Ularni til modulini o'qitish vaqtida olishadi va ular o'zgarmas bo'ladi. Ya'ni siz bir matnni kiritsangiz, ya'ni siz X ni kiritasiz, unga biriktirilgan koeffisiyent (k) o'zgarmagan holda avtomatik formulaga joylashadi. Hovotir olmang, buni modulni o'zi qiladi.

Qanchalik shunday parametrlar ko'p bo'lsa shuncha mantiqiy va yaxshi o'ylangan javob olasiz. Shu darajaga bordiku Open AI olgan natijasidan o'zlari qo'rqib ketadi, chunki GPT-2 generatsiya qilgan matnlar shunchaki sifatli ediku butun internet feyk ma'lumot bilan to'ldirishga yetardi.
Bu hazil emas, bu sifatdagi inqilob edi, eslaysizmi, GPT-1 da harakat qilib bugun kasalligimiz uchun bugun uyda nima qilmoqchi ekanimizni taxmin qilishga uringandi, lekin GPT-2 mustaqil institut talabasi uchun berilgan "Iqlim o'zgarishiga samarali javob berish uchun qanday fundamental iqtisodiy va siyosiy o'zgarishlar kerak?" mavzusida insho yozib bera olgan. Bunday mavzuga katta yoshli shaxs ham javob berishga qiynalgan bo'lardi.
Ammo ushbu inshoni shaxsini yashirib hakamlarga berilganda quyidagi javob olingan: "Insho yaxshi shakllantirilgan, misollar bilan mustahkamlangan, ammo g'oyalar original emas".
Miqdor sifatga tengdir, yoki mustaqil evolutsiya mumkinmi
Umuman ob aytganda biz parametrlar miqdorini qanchalik oshirsak sifat shuncha yaxshilanishi mumkin. Umuman mustaqil insho yoza olish ham hayratlanarli voqea. Lekin ikki manoli gaplarchi? Ularni bilan sun'iy intellekt qanday ishlay oladi. Keling buni misolda ko'ramiz:
- Daraxt tagida kitob o'qidim. U tarixiy edi.
- Daraxt tagida kitob o'qidim. U tarixiy edi.

Ushbu gaplardagi "tarixiy" so'zi nimaga yuzlanyabdi? Odamlar 95% hollarda birinchi holatda so'z kitob ikkinchi holatda esa daraxt haqida ketayotganini tushuna olishadi. Ammo sun'iy intellektchi? Dastlabki sun'iy intellekt bu masalani 50% holatdagina tushuna olgan. Hop endi bu masalani qanday yechamiz?
Sizni hayolizga "shunchaki ko'proq ma'lumot tiqamiz, natijada tushunib boshlaydi" degan variant kelishi mumkin. Eng qizig'i dastlab bu masalani rostan shunday yechishga harakat qilishgan va natijani 60% gacha ko'tara olishgan.
Ammo mo'jiza shundaki GPT-2 ni bunga hech kim o'qitmagan. Gap shundaki parametrlar miqdori 150 mlndan 350 mlnga chiqarilganda hech qanday o'zgarish bo'lmagan, ammo shu parametrlar miqdorini 700 mlnga chiqarilganidan so'ng birdan sakrash effekti bo'lib sun'iy intellekt ushbu masalani 70% holatda to'g'ri tushuna boshlagan.
E'tibor qiling aynan mana shu effekt sun'iy intellekt birdan rivojlanishiga sabab bo'lgan narsadir. Evolutsiya chiziqli yuz bermayabdi, masalan parametrlar soni 150 mlndan 350 mlnga chiqarilganda bunday natija yo'q edi, ammo uni 700 mlnga chiqarganimizdan birdan oldindan unga o'rgatilmagan masalalarni yechib boshlagan.
Qisqa xulosa: GPT-2 2019-yilda chiqdi va o'zini o'tmishdoshi nisbatan 10 barobar ko'p parametrlarga ega edi. Bu esa o'z navbati uni sifatli insholar yozishdan tortib bir qancha murakkab masalalar yechish qobiliyatini berdi.
2020-yil: GPT-3, yoki qanday qilib til modulidan Enshteynni yaratish mumkin
Parametrlar miqdorini oshirish tufayli GPT-2 ni qanchalik aqilli bo'lganini ko'rgan Open AI hodimlari uni yanada ko'paytirsakchi hayolga kelishdi va 2020-yilda chiqqan GPT-3 moduli 116 barobar ko'p, ya'ni 175 milliard parametrga ega edi. Uni hajmida esa endi 700 GB ni tashkil etardi.
Uning ma'lumotlar bazasi esa 1o barobar, ya'ni 420 GB ni tashkil etayotgandi. Bu asosan Vikipediani o'zlashtirish orqali edi. Ma'lumot uchun odam buncha ma'lumotni hech qachon o'zlashtira olmaydi.
E'tibor qiling ma'lumotlar hajmi 420 GB ammo uning parametrlari 700 GB. Aynan shundan so'ng sun'iy intellektga shunchaki matn ko'rinishdagi so'rovni kiritib kutilgan natijani olish imkoniyati paydo bo'ldi. Shuningdek Open AI hodimlari til modulini o'z o'zidan tarjimonlikdan tortib matematikani o'rganib olganini ko'rishdi.
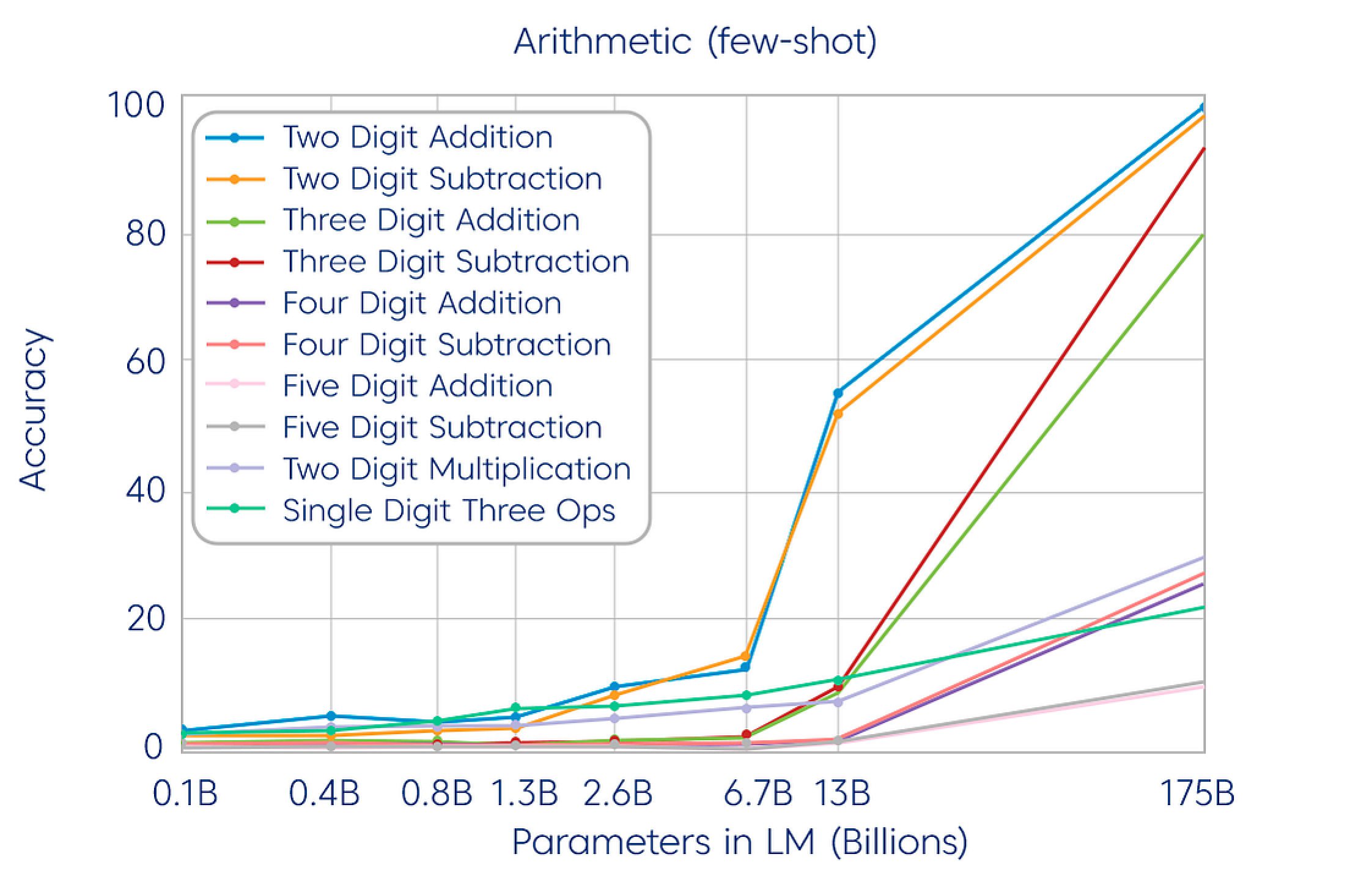
Takrorlayman, bu aslida bir til moduli edi, ammo unga «378 + 789 =» degan so'rovni bersaz qayerdandir aynan «1167» degan javobni bera boshladi. Lekin unga buni hech kim o'rgatmagandi. Mo'jiza bu do'stlar! Shu yerda kimdir aytishi mumkin "Yog'e shunchaki u qayerdadir shunday ma'lumotni ko'rganda to'tiqushdek takrorlayabdi deb", mayli davom etamiz.
Gap shundaki bu hali matematika edi xolos, parametrlar miqdorini yanada oshirish unda yana bir qancha qobiliyatlar paydo bo'lishiga sabab bo'lgan, quyidagi animatsiyada buni ko'rishiz mumkin.
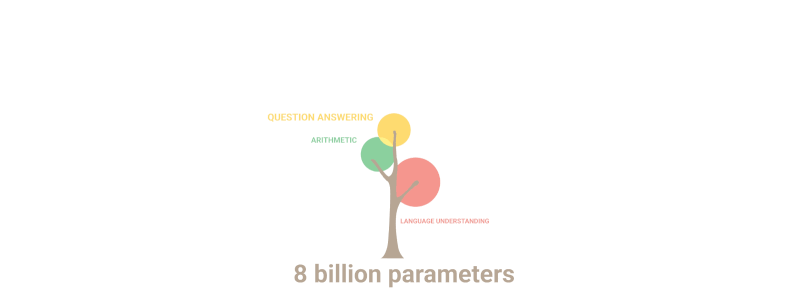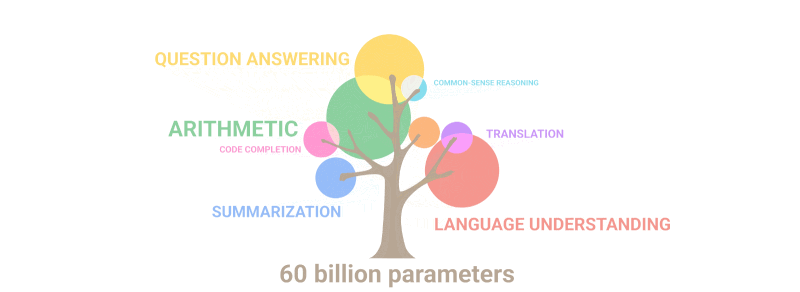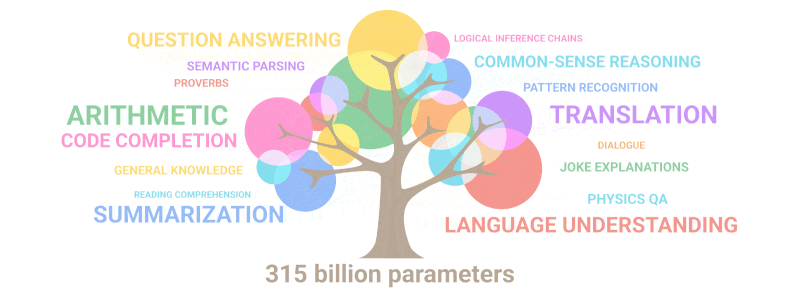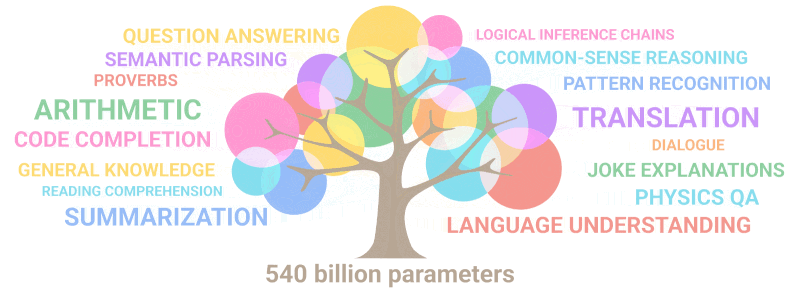
Aytgancha, yuqoridagi daraxt va kitob misolini endi til moduli 90% ehtimollikda yecha boshladi, bu esa jiddiy o'ylanishga sababchi bo'lishi kerak.
Qisqa xulosa: GPT-3 2020-yilda chiqdi va o'zini o'tmishdoshi nisbatan 100 barobar ko'p parametrlarga va 10 barobar ko'p ma'lumotlar bazasiga ega edi. Bu esa unga o'rgatilmagan tarjimonlik, matematika, dasturchilik, mantiq va boshqa qobiliyatlarni ochib berdi.
2022-yil yanvar, InstructGPT (GPT-3.5), yoki til modulini qanday qilib o'tlab ketmaslikni o'rgatish mumkin
Til modulimiz ko'p masalani yecha oladi degani, u hamma narsani biz hohlagandek tusha oladi degani emas. Masalan sizga oyingiz "Musorni tashlab kel" desalar, siz aniq nima qilishni bilasiz, va bu yerda oyingiz "faqat oynadan otma" degan jumla siz uchun shart emas.

Ammo sun'iy intellekt uchun bu narsa talab etiladi. Undan tashqari uni xaqorat qilmaslikka, diniy va etnik, javob berayotgan insonni ruhiy holati, taqiqlangan masalalarni hisobga olishi zarur edi. Gap nima haqida ketyotganini bilmaganlar uchun "Men rak kasaliga chalinganman, tuzalib ketamanmi" degan savolga "Yo'q, rak davosiz, sen baribir o'lib ketasan" degani kabilar. Bunga sabab esa uni bazasi qayerdan olganini eslaylik, u internetdan olingan va u yaxshi ham, yomon ham bo'lishi mumkin.
Bu holatda Open AI kelgan yagona yechim har bir yozilgan matnga sharh berib "Bu mumkin emas", "Buni qilma", "Bunday deyish mumkin emas" deb o'rgatib chiqish qolgan. Bu mantiqiy yechim, yosh bola ham nima to'g'ri va nima noto'g'ri ekanini atrofidagi insonlarni u yoki bu ishga nisbatan javobi orqali o'rganishadi. Bu narsa "SI to'g'irlash" deb nomlanadi va Open AI ohirgi yillarda bu bo'yicha ancha yutuqqa erishdi. Aks holda tasavur qilishiz mumkin undan zararli maslahat olgan qancha odamlar sudga berish hollarini.
Qisqa xulosa, InstructGPT (GPT-3,5) bu o'sha GPT-3 bo'lib ammo tirik insonlar sharhlari va baholari orqali nima yaxshi va nima yomonligini o'rgangan holatidir. Oddiy qilib aytganda tarbiyadan o'tgan versiyasi.
2022-yil noyabr, katta portlashni kichik sirlari
ChatGPT 2022-yil noyabrida chiqdi va butun olamga mashhur bo'la oldi. Lekin bir narsaga e'tibor qilaylik, InstructGPT 10 oy oldin ham mavjud edi, ammo deyarli hech kim u haqida bilmasdi. Open AI direktori Samuel H. Altman ham qanaqasiga 10 oy davomida saytda turgan narsa birdan aynan noyabr oyida mashhur bo'lib ketganiga hayrat bildirgan.
Ammo katta shon shuhrat asosida shunda ediku, Open AI suhbat uchun qulay interfeys ya'ni chatni yaratib berganidir. Ha, oddiy API intefeys orqali barcha messendjerlarda mavjud bo'lgan dialog oynasi uni shu darajada mashhur qila oldi. Ya'na uni tekin bo'lgani va barcha uchun ochiq bo'lgani odamlar daryo bo'lib kirishiga sababchi bo'la oldi.

Tushunayabsizlarmi? Til moduli boshqa kompaniyalarda ham bor edi, ammo aynan Open AI uni chat ko'rinishiga keltirgani "nafaqat texnologiyani o'zi balki uni ko'rinishi ham ahamiyatli" ekanini isbotlab bera oldi. Qarabsizku 1 mln foydalanuvchiga 5 kunda erishib yangi jahon rekordini ham o'rnatdi.
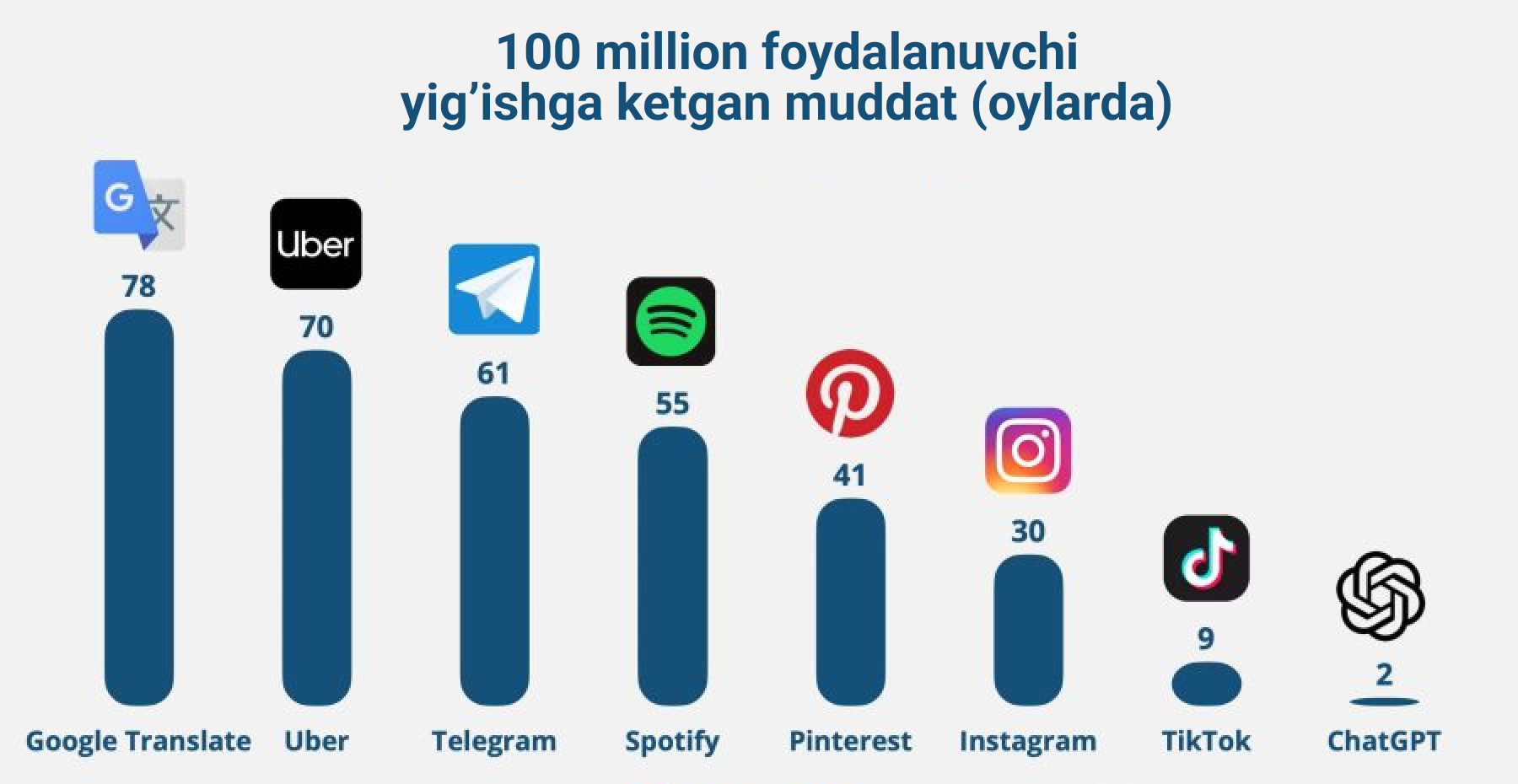
Odamlar oqimi bo'lgan joyda pul ham bo'ladi, va tezgina "Microsoft" Open AI bilan shartnoma qilib oldi. Qarabsizki bu portlashdan so'ng Google injenerlari tezroq o'zini sun'iy intellektini yaratishga harakat qilib "Bard" (Hozirda Gemini), xitoyliklar esa o'zini "Ernie" botini yaratishga kirishib ketishdi. Ammo bularni mutloq tarixi boshqa.

Qisqa xulosa: ChatGPT bu o'sha InstructGPT (GPT-3,5) bo'lib, ammo chiroyli chat ko'rinishga keltirilgan holatidir.
Xulosa
Maqola qisqa bo'lmadi, ammo sizga qiziqarli bo'ldi degan umiddaman. Dastlabki rejalarda uni yanada kattaroq qilib qanday o'z sun'iy intellektizni yaratish mumkinligini va GPT-4 haqida ma'lumotlarni ham qo'shmoqchi edim, agarda ushbu ko'plab ijobiy sharhlar to'plasa albatta ular haqida ham gaplashamiz.
