Строки и байты
Limera1n
Поговорим о строках и байтах. В Python есть такой тип, который называется bytes. Как я уже говорил, строки могут быть в разных кодировках, но информация в компьютере в конечном итоге представлена цифрами, нулями и единицами. Каждому символу присваивается определенное число.
Есть кодировочные таблицы, которые включают в себя некий набор чисел, которыми нумеруются символы.
Посмотрим, какая таблица у нас используется по дефолту:

Нам показывают, что по дефолту используется таблица кодировки utf-8.
Собственно, utf-8 это представление unicode в восьмибитном виде, то есть 1 байт.
Можем посмотреть, код любого символа:
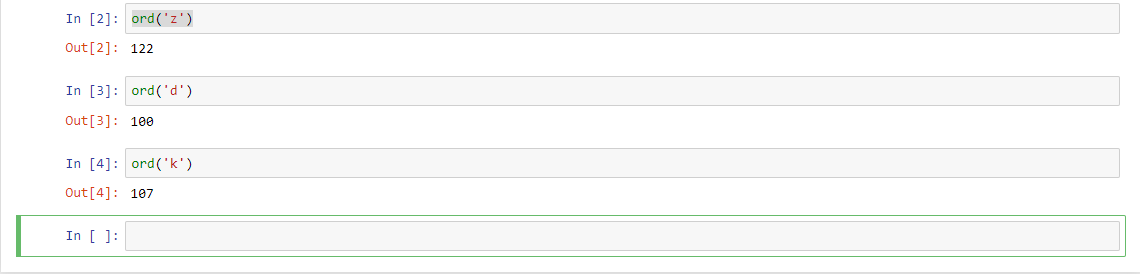
С помощью функции ord() мы можем это сделать.
Если мы хотим преобразовать символ по коду, то используем функцию chr():

Сейчас попробуем перевести целую строчку в байты:
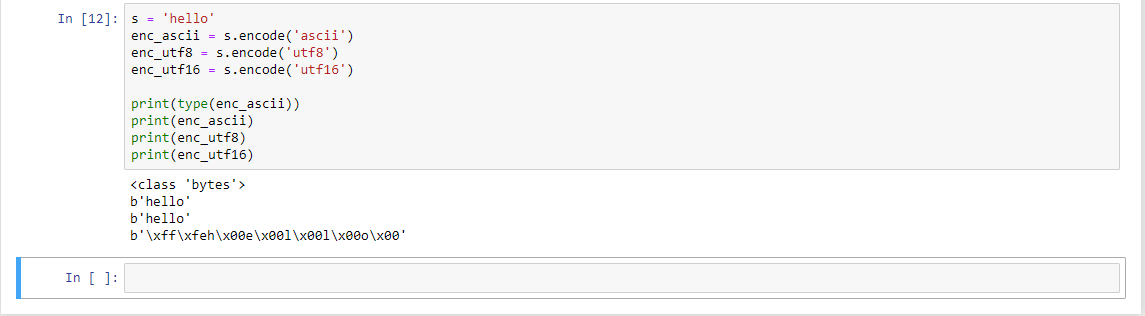
Функция encode возвращает тип bytes, то есть с помощью метода encode мы переводим символы с помощью определенной таблицы кодировок в байтовое представление. Префикс b перед строчкой означает, что представление у нас байтовое, просто функция print нам выводит все красиво.
Давайте посмотрим, какое количество байтов у нас используется для представления этих строк:

Можно увидеть, что в случае с ascii и utf8 у нас был выделен 1 байт на каждый символ, а с utf16 оказалось сложнее и вывод 12.
Чтобы сразу вывести строку в байты мы можем воспользоваться префиксом b:

Функцию encode мы можем вызвать "на живую":

Так же можем переводить и кириллицу, но уже красиво нам ничего не выведется.