Страх и ненависть в рекомендациях: как затащить ALBERT4Rec в прод на 1080TI
Eugene IvanovЭта и другие статьи про рекомендации в Wildberries выходят в рамках телеграм канала @wildrecsys
Введение
Привет! Меня зовут Иванов Евгений и в этой статье я расскажу о том, как учил и выводил в прод первую и основную модель нашего пайплайна персональных рекомендаций - ALBERT4Rec.
Сейчас в WB есть несколько кластеров, в каждом из которых насчитывается несколько десятков A100 и A800, но так было не всегда. Летом 2022 в распоряжении команды персонализации карты было две - 1080TI для обучения и Tesla T4 для инференса на проде.
Задача стояла, для таких ресурсов, поистине амбициозная - завести текущую SOTA модель в задаче sequential recommendations на ~2 миллиардах интеракций.
Забегая вперед - получилось. Но обо всем по порядку.

У нас было две видеокарты, десятки миллионов товаров, десятки миллионов активных пользователей… Не то, чтобы всё это было категорически необходимо в поездке, но если уж начали делать персональные рекомендации, то к делу надо подходить серьёзно.
Из NLP в рекомендации
BERT (Bidirectional Encoder Representations from Transformers) - это двунаправленная трансформерная модель, которая была представлена еще в 2018 году и на долгое время стала SOTA в ряде NLP задач, а сейчас ее вариации часто используются в качестве предобученных текстовых энкодеров в различных задачах (transfer learning).
Если говорить простым языком, то это стэк Transformer Encoder блоков, в которых самая интересная часть - это механизм внимания, Self-Attention, который позволяет выучивать сильные контекстуальные эмбеддинги для токенов.
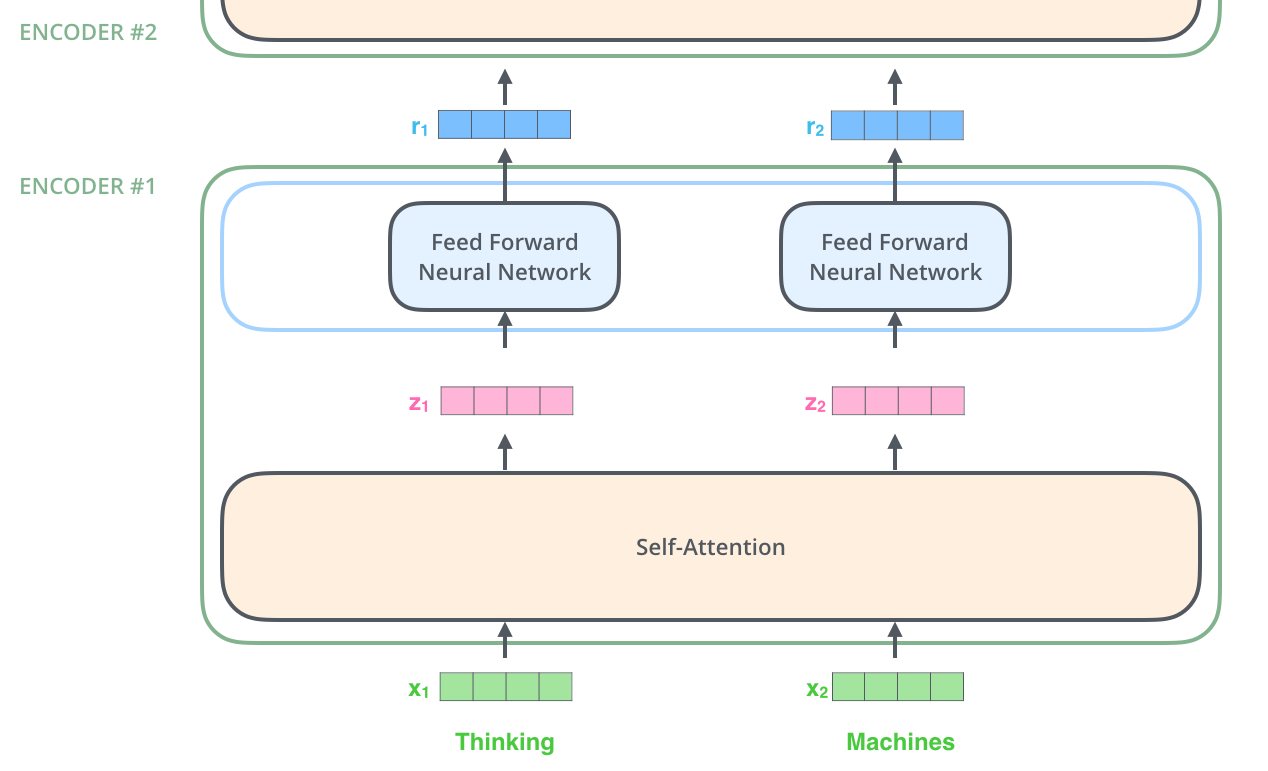
Ни для кого не секрет, что большое количество моделей в рекомендации приходят именно из NLP, что логично, ведь классическая задача language modeling очень схожа с постановкой задачи в рекомендациях - нужно по имеющейся последовательности токенов предсказать следующий.
Когда в текстовом домене зажигали сетки на свертках - рекомендации получили Caser, рекуррентные сети - GRU4Rec. Тенденция не обошла стороной и трансформерные архитектуры - так появился BERT4Rec.
Проблема словаря
Конечно, смена домена привнесла некоторые отличия.
Во-первых, текстовый BERT обучается на двух задачах - MLM (Masked Language Modelling) и NSP (Next Sentence Prediction). В рекомендации перекочевала только первая, которую еще называют Cloze task.
Во-вторых, размер словаря. При работе с текстом BERT обрабатывает не слова, а набор “подслов”, полученных путем WordPiece токенизации. Это значительно снижает общий словарь и позволяет не учить эмбеддинг для каждого слова в языке.
Также токенизация позволяет обучаться на задаче Masked Language Modelling, ведь по-сути, MLM голова это полносвязный слой по размеру словаря + softmax + категориальная кросс энтропия. Такая конструкция генерирует огромное количество весов в последних слоях (чем больше словарь - тем это более явная проблема) и ограничивает размерность выходного слоя.

В рекомендациях же, где мы оперируем набором идентификаторов товаров, такая токенизация невозможна, а значит мы неизбежно сталкиваемся с вышеописанной проблемой large vocabulary bottleneck, которая не позволит обучить модель на десятках миллионов товаров.
Хорошая новость заключается в том, что мы делаем рекомендации для главной, на которой хотим видеть только приемлемые для витрины сайта карточки, а значит можно различным набором эвристических правил - продаваемость, просматриваемость, рейтинги и т.п. - отобрать из нашего каталога первоначальных кандидатов.
Плохая - даже после такого отбора мы переходим от словаря в десятки миллионов товаров к словарю в миллионы, что все еще очень много.
Negative sampling
В качестве решения при обучении BERT4Rec я использовал негативное семплирование. Идея достаточно проста - вместо того, чтобы оптимизироваться по всему словарю давайте для каждого позитивного примера отбирать негативные - и будем работать с этим.
В нашем случае используется in-batch negative sampling, когда внутри батча для каждого маскированного токена семплируются негативы, но только из таких же маскированных токенов. Т.е. в качестве анкора выступает входный эмбеддинг, в качестве позитива - выход с трансофрмера по этому эмбеддингу, в качестве негативов - выход с трансофрмера по остальным маскированным эмбеддингам. Для обучения используется softmax loss.
Важно отметить, что при такой схеме обучения в качестве негативов у нас пропорционально чаще будут выступать популярные по выборке айтемы. Подробнее про проблему можно прочитать тут. Для нас этот скорее плюс - итоговый pop bias модели составляет тысячные процента.
Впоследствии мы пробовали различные варианты logQ correction (частотности по всей выборке, по батчу), которые не привели к улучшению метрик на наших данных.
Happy end
Череда оффлайн экспериментов привела к финальной версии модели. ALBERT4Rec показал себя на ~20% лучше по ранжирующим метрикам, чем BERT4Rec. Итоговый размер эмбеддинга составил 256.
В последнем квартале 2022 года модель успешно прошла АБ, показав прирост в десятки процентов по основным метрикам с главной (GMV, конверсии) относительно прошлого решения - ALS + Caser.
После АБ ALBERT4Rec был поставлен на регулярный пересчет и выступал основной моделью выдачи персональных рекомендаций вплоть до выкатки реранкера.
Заключение
Спасибо что дочитали! В следующей статье я расскажу о том, как мы тюнили это решение - меняли positional embedding, комбинировали фидбек, увеличивали словарь и переиспользовали эмбеддинги в item2item задачах.