Статический анализ PHP-кода на примере PHPStan, Phan и Psalm. PART 2
https://habr.com/ru/company/badoo/blog/426605/PHPStan
Разработка некоего Ondřej Mirtes из Чехии. Активно разрабатывается с конца 2016 года.
Чтобы начать использовать PHPStan, нужно:
- Установить его (проще всего это сделать через Composer).
- (опционально) Сконфигурировать.
- В простейшем случае достаточно запустить:
vendor/bin/phpstan analyse ./src
(вместо src может быть список конкретных файлов, которые вы хотите проверить).
PHPStan прочитает PHP-код из переданных файлов. Если ему встретятся неизвестные классы, он попробует подгрузить их автолоадом и через reflection понять их интерфейс. Вы можете также передать путь к Bootstrap-файлу, через который вы настроите автолоад, и подключить какие-то дополнительные файлы, чтобы упростить PHPStan анализ.
Ключевые особенности:
- Можно анализировать не всю кодовую базу, а только часть — неизвестные классы PHPStan попытается подгрузить автолоадом.
- Если по какой-то причине какие-то ваши классы не в автолоаде, PHPStan не сможет их найти и выдаст ошибку.
- Если у вас активно используется магические методы через
__call / __get / __set, то вы можете написать плагин для PHPStan. Уже существуют плагины для Symfony, Doctrine, Laravel, Mockery и др. - На самом деле, PHPStan выполняет автолоад не только для неизвестных классов, а вообще для всех. У нас много старого кода, написанного до появления анонимных классов, когда мы в одном файле создаём некий класс, а потом сразу его инстанцируем и, возможно, даже вызываем какие-то методы. Автолоад (
include) таких файлов приводит к ошибкам, потому что код выполняется не в обычном окружении. - Конфиги в формате neon (никогда не слышал, чтобы где-нибудь ещё использовался такой формат).
- Нет поддержки своих PHPDoc-тегов типа
@phpstan-var, @phpstan-returnи т. п.
Ещё одной особенностью является то, что у ошибок есть текст, но нет никакого типа. То есть вам возвращается текст ошибки, например:
Method \SomeClass::getAge() should return int but returns int|nullMethod \SomeOtherClass::getName() should return string but returns string|null
В этом примере обе ошибки, в общем-то, об одном и том же: метод должен вернуть один тип, а в реальности возвращает другой. Но тексты у ошибок разные, хотя и похожие. Поэтому, если вы хотите отфильтровать какие-то ошибки в PHPStan, делайте это только через регулярные выражения.
Для сравнения, в других анализаторах у ошибок есть тип. Например, в Phan такая ошибка имеет тип PhanPossiblyNullTypeReturn, и можно в конфиге указать, что не требуется проверка на такие ошибки. Также, имея тип ошибки, можно, например легко собрать статистику по ошибкам.
Поскольку мы не используем Laravel, Symfony, Doctrine и подобные решения и у нас в коде довольно редко используются магические методы, основная фича PHPStan у нас оказалась невостребованной. ;( К тому же из-за того, что PHPStan include-ит все проверяемые классы, иногда его анализ просто не работает на нашей кодовой базе.
Тем не менее для нас PHPStan остаётся полезным:
- Если надо проверить несколько файлов, PHPStan заметно быстрее Phan и немного (на 20—50%) быстрее Psalm.
- Отчёты PHPStan позволяют нам проще находить
false-positiveв других анализаторах. Обычно, если в коде есть какой-то явныйfatal, он показывается всеми анализаторами (или как минимум двумя из трёх).
Update:
Автор PHPStan Ondřej Mirtes тоже прочитал нашу статью и подсказал нам, что PhpStan, также как и Psalm, имеет сайт с «песочницей»: https://phpstan.org/. Это очень удобно для баг-репортов: воспроизводишь ошибку в и даёшь ссылку в GitHub.
Phan
Разработка компании Etsy. Первые коммиты от Расмуса Лердорфа.
Из рассматриваемой тройки Phan — единственный настоящий статический анализатор (в том плане, что он не исполняет никакие ваши файлы — он парсит всю вашу кодовую базу, а затем анализирует то, что вы скажете). Даже для анализа нескольких файлов в нашей кодовой базе ему требуется порядка 6 Гб оперативной памяти, и занимает этот процесс четыре—пять минут. Но зато полный анализ всей кодовой базы занимает примерно шесть—семь минут. Для сравнения, Psalm анализирует её за несколько десятков минут. А от PHPStan мы вообще не смогли добиться полного анализа всей кодовой базы из-за того, что он include-ит классы.
Впечатление от Phan двоякое. С одной стороны, это наиболее качественный и стабильный анализатор, он многое находит и с ним меньше всего проблем, когда надо проанализировать всю кодовую базу. С другой стороны, у него есть две неприятные особенности.
Под капотом Phan использует расширение php-ast. По-видимому, это одна из причин того, что анализ всей кодовой базы проходит относительно быстро. Но php-ast показывает внутреннее представление AST-дерева так, как оно отображается в самом PHP. А в самом PHP AST-дерево не содержит информации о комментариях, которые расположены внутри функции. То есть, если вы написали что-то вроде:
/**
* @param int $type
*/
function doSomething($type) {
/** @var \My\Object $obj **/
$obj = MyFactory::createObjectByType($type);
…
}
то внутри AST-дерева есть информация о внешнем PHPDoc для функции doSomething(), но нет информации PHPDoc-подсказки, которая внутри функции. И, соответственно, Phan тоже о ней ничего не знает. Это наиболее частая причина false-positive в Phan. Есть некие рекомендации по тому, как вставлять подсказки (через строки или assert-ы), но, к сожалению, они сильно отличаются от того, к чему привыкли наши программисты. Частично мы решили эту проблемы написанием плагина для Phan. Но о плагинах речь пойдёт ниже.
Вторая неприятная особенность состоит в том, что Phan плохо анализирует свойства объектов. Вот пример:
class A {
/**
* @var string|null
*/
private $a;
public function __construct(string $a = null)
{
$this->a = $a;
}
public function doSomething()
{
if ($this->a && strpos($this->a, 'a') === 0) {
var_dump("test1");
}
}
}
В этом примере Phan скажет вам, что в strpos вы можете передать null. Подробнее об этой проблеме можно узнать здесь: https://github.com/phan/phan/issues/204.
Резюме. Несмотря на некоторые сложности, Phan — очень крутая и полезная разработка. Кроме этих двух типов false-positive, он почти не ошибается, либо ошибается, но на каком-то действительно сложном коде. Нам также понравилось, что конфиг находится в PHP-файле — это даёт определённую гибкость. Ещё Phan умеет работать как language server, но мы не использовали эту возможность, так как нам хватает PHPStorm.
Плагины
У Phan хорошо проработанный API для разработки плагинов. Можно добавлять свои проверки, улучшать выведение типов для вашего кода. У этого API есть документация, но особенно классно, что внутри уже есть готовые рабочие плагины, которые можно использовать как примеры.
Мы успели написать два плагина. Первый был предназначен для разовой проверки. Мы захотели оценить, насколько наш код готов к PHP 7.3 (в частности, узнать, нет ли в нём case-insensitive-констант). Мы практически были уверены в том, что таких констант нет, но за 12 лет могло произойти всякое — следовало проверить. И мы написали плагин для Phan, который бы ругался, если бы в define() использовался третий параметр.
Плагин получился очень простым
В Phan разные плагины можно повесить на разные события. В частности, плагины с интерфейсом AnalyzeFunctionCallCapability срабатывают, когда анализируется вызов функции. В этом плагине мы сделали так, чтобы при вызове функции define() вызывалась наша анонимная функция, которая проверяет, что у define() не более двух аргументов. Потом мы просто запустили Phan, нашли все места, где define() вызывалась с тремя аргументами, и убедились, что у нас нет case-insensitive-констант.
С помощью плагина мы также частично решили проблему false-positive, когда Phan не видит PHPDoc-подсказок внутри кода.
У нас часто используются фабричные методы, которые на вход принимают константу и по ней создают некоторый объект. Зачастую код выглядит примерно так:
/** @var \Objects\Controllers\My $Object */ $Object = \Objects\Factory::create(\Objects\Config::MY_CONTROLLER);
Phan не понимает такие PHPDoc-подсказки, но в этом коде класс объекта можно получить из названия константы, переданной в метод create(). Phan позволяет написать плагин, который срабатывает в момент анализа возвращаемого значения функции. И с помощью этого плагина можно подсказать анализатору, какой конкретно тип возвращает функция в данном вызове.
Пример этого плагина более сложный. Но в коде Phan есть хороший пример в vendor/phan/phan/src/Phan/Plugin/Internal/DependentReturnTypeOverridePlugin.php.
В целом, мы очень довольны анализатором Phan. Перечисленные выше false-positive мы частично (в простых случаях, с простым кодом) научились фильтровать. После этого Phan стал почти эталонным анализатором. Однако необходимость сразу парсить всю кодовую базу (время и очень много памяти) по-прежнему усложняет процесс его внедрения.
Psalm
Psalm — разработка компании Vimeo. Честно говоря, я даже не знал, что в Vimeo используется PHP, пока не увидел Psalm.
Этот анализатор — самый молодой из нашей тройки. Когда я прочитал новость о том, что Vimeo выпустила Psalm, был в недоумении: «Зачем вкладывать ресурсы в Psalm, если уже есть Phan и PHPStan?» Но выяснилось, что у Psalm есть свои полезные особенности.
Psalm пошёл по стопам PHPStan: ему тоже можно дать список файлов для анализа, и он проанализирует их, а ненайденные классы подключит автолоадом. При этом он подключает только ненайденные классы, а файлы, которые мы попросили проанализировать, не будут include-иться (в этом отличие от PHPStan). Конфиг хранится в XML-файле (для нас это скорее минус, но не очень критично).
У Psalm есть сайт с «песочницей», где можно написать код на PHP и проанализировать его. Это очень удобно для баг-репортов: воспроизводишь ошибку на сайте и даёшь ссылку в GitHub. И, кстати, на сайте описаны все возможные типы ошибок. Для сравнения: в PHPStan у ошибок нет типов, а в Phan они есть, но нет единого списка, с которым можно было бы ознакомиться.
Ещё нам понравилось, что при выводе ошибок Psalm сразу показывает строки кода, где они были найдены. Это сильно упрощает чтение отчётов.
Но, пожалуй, самой интересной особенностью Psalm являются его кастомные PHPDoc-теги, которые позволяют улучшить анализ (особенно определение типов). Перечислим наиболее интересные из них.
@psalm-ignore-nullable-return
Бывает так, что формально метод может возвращать null, но код уже организован таким образом, что этого никогда не происходит. В этом случае очень удобно, что можно добавить вот такую PHPDoc-подсказку к методу/функции — и Psalm будет считать, что null не возвращается.
Аналогичная подсказка существует и для false: @psalm-ignore-falsable-return.
Типы для closure
Если вы когда-нибудь интересовались функциональным программированием, то могли заметить, что там часто функция может вернуть другую функцию или принять в качестве параметра какую-то функцию. В PHP подобный стиль может сильно запутать ваших коллег, и одна из причин заключается в том, что в PHP нет стандартов документирования таких функций. Например:
function my_filter(array $ar, \Closure $func) { … }
Как программисту понять, какой интерфейс у функции во втором параметре? Какие параметры она должна принимать? Что она должна возвращать?
В Psalm поддерживается синтаксис для описания функций в PHPDoc:
/**
* @param array $ar
* @psalm-param Closure(int):bool $func
*/
function my_filter(array $ar, \Closure $func) { … }
С таким описанием уже понятно, что в my_filter нужно передать анонимную функцию, которая на вход примет int и вернёт bool. И, конечно же, Psalm будет проверять, что у вас в коде сюда передаётся именно такая функция.
Enums
Допустим, у вас есть функция, принимающая строковый параметр, и туда можно передавать только определённые строки:
function isYes(string $yes_or_no) : bool
{
$yes_or_no = strtolower($yes_or_no)
switch($yes_or_no) {
case ‘yes’:
return true;
case ‘no’:
return false;
default:
throw new \InvalidArgumentException(…);
}
}
Psalm позволяет описать параметр этой функции вот так:
/** @psalm-param ‘Yes’|’No’ $yes_or_no **/
function isYes(string $yes_or_no) : bool { … }
В этом случае Psalm будет пытаться понять, какие конкретно значения передают в эту функцию, и выдавать ошибки, если там будут значения, отличные от Yes и No.
Подробнее об enum-ах здесь.
Type aliases
Выше при описании array shapes я упоминал, что, хотя анализаторы и позволяют описывать структуру массивов, пользоваться этим не очень удобно, так как описание массива приходится копировать в разных местах. Правильным решением, конечно же, является использование классов вместо массивов. Но в случае с многолетним legacy это не всегда возможно.
На самом деле, проблема возникает не только с массивами, а с любым типом, который не является классом:
- массив;
- closure;
- union-тип (например, несколько классов или класс и другие типы);
- enum.
Любой такой тип, если он используется в нескольких местах, нужно дублировать в PHPDoc и при его изменении, соответственно, везде исправлять. Поэтому у Psalm есть небольшое улучшение в этом плане. Вы можете объявить alias для типа и потом в PHPDoc использовать этот alias. К сожалению, есть ограничение: это работает в рамках одного PHP-файла. Но это уже упрощает описание типов. Правда, только для Psalm.
Generics aka templates
Рассмотрим эту возможность на примере. Допустим, у вас есть такая функция:
function identity($x) { return $x; }
Как описать тип этой функции? Какой тип она принимает на вход? Что она возвращает?
Наверное, первое, что приходит на ум, — mixed, то есть она может принимать на вход любое значение и возвращать любое значение.
Для статического анализатора встретить mixed — это катастрофа. Это значит, что нет абсолютно никакой информации о типе и нельзя делать никакие предположения. Но на самом деле, хотя функция identity() и принимает/возвращает любые типы, у неё есть логика: она возвращает тот же тип, который она приняла. А для статического анализатора это уже что-то. Это значит, что в коде:
$i = 5; // int $y = identity($i);
анализатор может определить тип входящего аргумента (int), а значит, может определить и тип переменной $y (тоже int).
Но как нам передать эту информацию анализатору? В Psalm для этого есть специальные PHPDoc-теги:
/**
* @template T
* @psalm-param T $x
* @psalm-return T
*/
function identity($x) { $return $x; }
То есть templates позволяют передать Psalm информацию о типе, если класс/метод может работать с любым типом.
Внутри Psalm есть хорошие примеры работы с templates:
— vendor/vimeo/psalm/src/Psalm/Stubs/CoreGenericFunctions.php;
— vendor/vimeo/psalm/src/Psalm/Stubs/CoreGenericClasses.php.
Подобный функционал есть и в Phan, но он работает только с классами: https://github.com/phan/phan/wiki/Generic-Types.
В целом, нам Psalm очень понравился. Похоже, что автор пытается «сбоку» прикрутить более умную систему типов и более умные и практически полезные подсказки для анализатора. Нам также понравилось, что Psalm сразу показывает строки кода, в которых найдены ошибки, и мы даже реализовали такое для Phan и PHPStan. Но об этом чуть ниже.
Инспекции кода в PHPStorm
У анализаторов есть общий небольшой недостаток: информацию об ошибке вы получаете не во время написания кода, а намного позже. Обычно вы пишете код, потом открываете консоль и запускаете анализаторы, после чего получаете отчёт.
Для программиста было бы удобнее получать информацию об ошибках в процессе редактирования кода. В этом направлении двигается Phan, который развивает свой language server. Но нам в PHPStorm, увы, неудобно его использовать.
Но, к счастью, у PHPStorm есть свой отличный анализатор (инспекции кода), по качеству соизмеримый с описанными выше решениями. А в дополнение к нему есть крутой плагин — Php Inspections (EA Extended). Главное отличие от анализаторов — удобство для программиста, заключающееся в том, что ошибки видны в редакторе во время написания кода. Кроме того, эти инспекции можно очень тонко настроить. Например, можно в проекте выделить разные scopes файлов и настроить инспекции по-разному для разных scopes.
Ещё отмечу такой полезный плагин, как deep-assoc-completion. Он хорошо понимает структуру массивов и упрощает автокомплит ключей.
Использование анализаторов в Badoo
Как это работает у нас?
Сегодня статический анализ кода используется несколькими командами, но в наших планах внедрить эту практику во всех.
Мы анализируем только изменённые файлы, вплоть до строк. То есть, когда девелопер завершает свою задачу, мы берём его git diff и запускаем анализаторы только для изменённых/добавленных файлов, а из полученного списка ошибок убираем те, которые относятся к старым (неизменённым) строкам. Таким образом мы прячем от девелопера ошибки, которые были сделаны ранее.
Конечно, этот подход не совсем правильный: программист может своим кодом сломать что-то за пределами своего git diff. Здесь мы пошли на компромисс. Даже в таком виде использование статического анализа даёт свои плоды в виде ошибок, найденных в новом коде. И мы не хотим заставлять программиста исправлять старые ошибки. Но, конечно, в будущем, когда наш код станет более чистым с точки зрения анализаторов, мы пересмотрим это решение.
Получив отчёты от трёх анализаторов, мы объединяем их в один, где ошибки группируются по файлам и строкам:
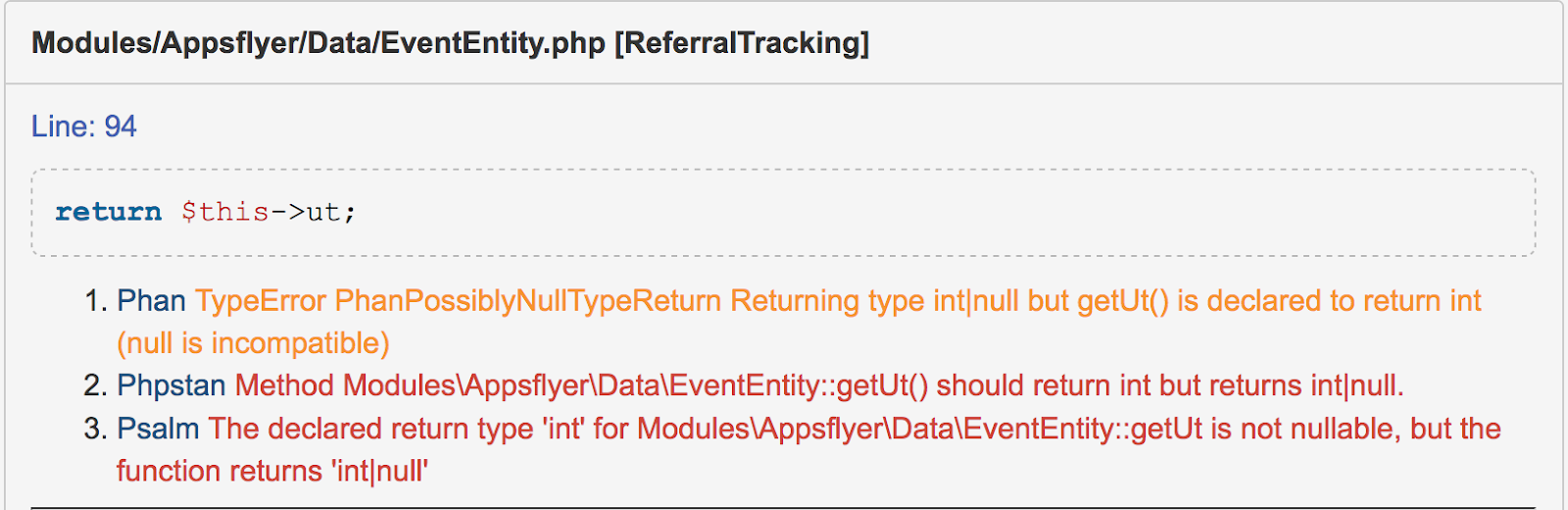
В процессе формирования этого отчёта мы также пробуем удалить некоторые false-positive. Например, мы помним, что у Phan есть проблемы с определением типа для свойств объектов, и примерно знаем, какой тип у таких ошибок. Поэтому, если на какую-то строку пожаловался только Phan и тип ошибки похож на тот, в котором он часто ошибается, мы скрываем такую ошибку от программиста.
Место анализаторов в нашем QA
Мы всячески стараемся снизить количество багов на продакшене:
- мы используем несколько видов автотестов;
- у нас есть code review;
- у нас есть ручное тестирование.
Статические анализаторы — это, по сути, ещё один инструмент в этом списке, и он хорошо его дополняет. У статических анализаторов есть ряд преимуществ:
- они могут покрыть 100% кода (в отличие от тестов, которые для каждого участка кода надо писать отдельно);
- они часто отлавливают такие ошибки, которые сложно заметить в процессе code review;
- они способны анализировать даже тот код, который сложно или невозможно запустить при ручном тестировании.
Задача внедрения статического анализа выросла из идеи внедрить strict types. Но в результате статические анализаторы дали нам намного больше проверок, чем strict types, и они более гибкие:
- анализаторы работают для всего кода, а чтобы увидеть ошибки
strict types, нужно исполнить код; - ошибку анализатора можно исправить позже, если она не критична (возможно, это не лучшая практика, но в некоторых случаях это может быть полезно);
- система типов в статических анализаторах даже более гибкая, чем в самом PHP (например, они поддерживают
union types, которых нет в PHP); - статические анализаторы приближают нас к внедрению
strict types, поскольку они умеют эмулировать такие же строгие проверки.
Отчёты анализаторов: мнение программистов
Нельзя сказать, что все программисты в восторге от статических анализаторов. Причин тут несколько.
Во-первых, многие испытывают недоверие к анализаторам, считая, что последние способны найти только какие-то примитивные ошибки, которых мы не допускаем.
Во-вторых, как уже было сказано выше, многое в отчётах анализаторов — просто неточности, например, неправильно указанные типы в PHPDoc. Некоторые программисты пренебрежительно относятся к таким ошибкам — код ведь работает.
В-третьих, у некоторых программистов завышенные ожидания. Они думали, что анализаторы будут находить какие-то хитрые баги, а вместо этого они вынуждают их добавлять проверки типов и исправлять PHPDoc. :)
Однако польза, принесённая анализаторами, перекрывает все эти незначительные недовольства. И как ни крути, это хорошая инвестиция в будущий код.