Сравнение типов данных VARCHAR(max) и VARCHAR(n) в SQL Server
OTUS
Тип varchar(max) часто используется как в обычных, так и во временных таблицах. Да, с ним можно не беспокоиться о длине строк или появления ошибки "Произойдет усечение строковых или двоичных данных" (String or binary data would be truncated).
Но стоит ли использовать varchar(max) повсюду?
Подробнее о varchar(n) вы можете прочитать здесь, а в этой статье мы сравним типы varchar(max) и varchar(n).
Общее описание VARCHAR(max)
Тип данных varchar(max) появился в SQL Server 2005. Он пришел на смену устаревшим типам для работы с большими бинарным данными (blob): text, ntext и image. Во всех этих типах можно хранить до 2 ГБ данных. Как вы, возможно, знаете, базовой единицей хранения в SQL Server является страница. Размер страницы фиксирован и составляет 8 КБ (8192 байта). Для заголовка страницы используется 96 байта, в остальных 8096 байтах (8192 - 96 байт) можно хранить данные. Но, помимо этого, страница еще содержит таблицу смещения строк (row offset) и на данные остается 8000 байт. Поэтому в varchar(8000) можно хранить до 8000 байт.
Давайте создадим несколько таблиц с varchar(max) и varchar(n) разной допустимой длины.
CREATE TABLE dbo.Employee_varchar_2000 (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(2000) ); CREATE TABLE dbo.Employee_Varchar_4500 (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(4500) ); CREATE TABLE dbo.Employee_Varchar_8000 (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(8000) ); CREATE TABLE dbo.Employee_Varchar_Max (id INT IDENTITY PRIMARY KEY, Col1 VARCHAR(MAX) );
Далее вставим в эти таблицы несколько записей.
INSERT INTO Employee_varchar_2000 (Col1)
SELECT REPLICATE('A', 2000);
INSERT INTO Employee_varchar_4500 (Col1)
SELECT REPLICATE('A', 4500);
INSERT INTO Employee_varchar_8000 (Col1)
SELECT REPLICATE('A', 8000);
INSERT INTO Employee_varchar_max (Col1)
SELECT REPLICATE('A', 8000);
Посмотрим длину строк в этих таблицах, используя следующие запросы:
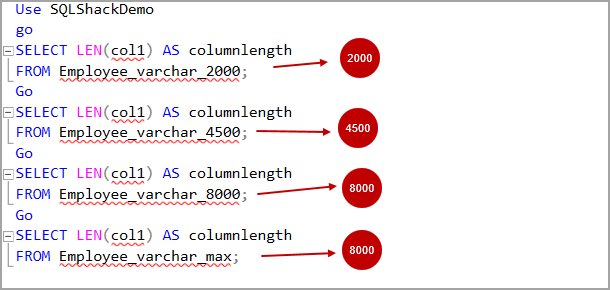
Use SQLShackDemo go SELECT LEN(col1) AS columnlength FROM Employee_varchar_2000; SELECT LEN(col1) AS columnlength FROM Employee_varchar_4500; SELECT LEN(col1) AS columnlength FROM Employee_varchar_8000; SELECT LEN(col1) AS columnlength FROM Employee_varchar_max;
И убедимся, что длина строк равна длине, указанной в определении столбца.
Теперь посмотрим количество страниц, количество строк и единицу распределения (allocation unit) для наших таблиц, используя DMV sys.dm_db_index_physical_stats.
SELECT OBJECT_NAME([object_id]) AS TableName,
alloc_unit_type_desc,
record_count,
page_count,
round(avg_page_space_used_in_percent,0) as avg_page_space_used_in_percent ,
min_record_size_in_bytes,
max_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED')
WHERE OBJECT_NAME([object_id]) LIKE 'Employee_varchar%';
Данные во всех таблицах хранятся в единице распределения IN_ROW_DATA.

В колонке с varchar(n) нельзя хранить более 8000 байт, но давайте попробуем вставить больше.
INSERT INTO Employee_varchar_8000 (Col1)
SELECT REPLICATE('A', 8001);
Go
INSERT INTO Employee_varchar_8000 (Col1)
SELECT REPLICATE('A', 10000);
Запрос выполняется успешно, но данные усекаются до 8000 символов. Аналогичное усечение происходит и для таблицы Employee_varchar_max, хотя там тип varchar(max).

Чтобы вставить более 8000 символов в колонку varchar(max) нужно привести значение к типу varchar(max).
INSERT INTO Employee_varchar_8000 (Col1) SELECT REPLICATE(CONVERT(VARCHAR(max), 'x'), 8001);
При попытке вставить такую запись в таблицу Employee_varchar_8000 мы получим сообщение об ошибке. В таблицу Employee_varchar_max записи будут успешно вставлены.

Выполним повторно запрос, отображающий информацию о единицах распределения.

Мы видим, что в таблице Employee_Varchar_Max появилась единица распределения LOB_DATA для хранения данных размером более 8000 байт. В единице распределения IN_ROW_DATA находится указатель на эти данные.
Можно сделать следующие выводы для varchar(max):
- Если данных меньше или равны 8000 байт, то SQL Server использует страницу IN_ROW_DATA.
- Если данных больше 8000 байт, то SQL Server использует страницу LOB_DATA.
Сравнение производительности varchar(max) и varchar(n)
Давайте вставим по 10 000 записей в каждую из созданных ранее таблиц и измерим время вставки данных. Для этого можно использовать ApexSQL Generate.
У меня получились следующие результаты:
- Время вставки Employee_varchar_2000 0,08 секунды
- Время вставки Employee_varchar_4500 0,19 секунды
- Время вставки Employee_varchar_8000 0,31 секунды
- Время вставки Employee_varchar_Max 2,72 секунды

Индексы на VARCHAR(N) и VARCHAR(MAX)
Как администратор баз данных вы, скорее всего, не будете иметь возможности изменять структуру таблиц. Однако вы можете создавать индексы.
На колонке varchar(n) можно создать индекс.
CREATE INDEX IX_Employee_varchar_2000_1 ON dbo.Employee_varchar_2000(col1) GO
Попытка сделать то же самое для varchar(max) приведет к ошибке.
CREATE INDEX IX_Employee_varchar_max ON dbo.Employee_varchar_max(col1) GO
Msg 1919, Level 16, State 1, Line 23 Column ‘col1’ in table ‘dbo.Employee_varchar_max’ is of a type that is invalid for use as a key column in an index.
Хотя столбец varchar(max) можно использовать в качестве включенного (INCLUDE) в индекс, но искать по нему нельзя. Кроме того, для него потребуется дополнительное место. Поэтому стоит избегать индексов с varchar(max).
Сравнение планов выполнения
Сначала выполним запрос для таблицы Employee_Varchar_2000 и посмотрим фактический план выполнения.

В фактическом плане выполнения мы видим оператор Index Seek.
Далее запустим такой же запрос для таблицы с varchar(max).
select col1 from Employee_varchar_max where col1 like 'xxxx%'

Здесь уже видим оператор Clustered Index Scan, а он может быть весьма ресурсоемким в зависимости от количества строк в таблице.
Давайте сравним планы, используя Compare Showplan в SSMS. Чтобы сравнить два плана, сохраните один из, щелкнув правой кнопкой мыши на плане, выбрав "Save Execution Plan As…", и указав место сохранения.
В другом плане щелкните правой кнопкой мыши и выберите "Compare Showplan". Откроется окно, в котором можно выбрать ранее сохраненный план.
На скриншоте ниже показан результат сравнения планов.
- Оценка стоимости процессора (estimated CPU cost) для оператора выборки данных для
varchar(max)больше, чем дляvarchar(2000). - Для
varchar(max)используется операторClustered Index Scan— сканируются все записи. Предполагаемое количество строк (estimated number of rows) 10000. В то время как дляvarchar (2000)используется операторIndex Seekи предполагаемое количество строк составляет 1,96078. - Предполагаемый размер строки (estimated row size) у
varchar(max)4035 байт,varchar(2000)— 1011 байт.

Разница между varchar(max) и varchar(n)

Выводы
В этой статье мы поговорили о типе данных varchar(max), а также рассмотрели несколько различий между varchar(max) и varchar(n). Используйте правильные типы данных. Учитывайте схему базы данных, производительность, возможность сжатия и использования индексов. Проанализируйте используемые типы данных в ваших БД и при необходимости измените их, конечно, с тщательным тестированием.