Spring Data JDBC

⚡️ В 2018 году разработчики Spring Data представили альтернативу JPA — Spring Data JDBC. Она стремится быть концептуально проще по трём критериям:
1) Никаких ленивых загрузок или кеширования. При получении сущности, она загружается сразу, как только выполняется SQL запрос.
2) Если вы сохраняете сущность, она сохранится. Или же нет, если вы этого не делаете. Нет сессий и отслеживаний.
3) Простая модель сопоставления сущностей, решающая простые задачи. Для сложных стоит посмотреть другие варианты.
🦾 Если работали с JPA, то вам будет несложно освоить и Spring Data JDBC — здесь можно использовать интерфейс CrudRepository<T, id> и имплементировать его, добавлять новые методы, например:

С недавнего обновления, методы научились принимать в себя объекты Pageable для постраничного вывода данных — раньше необходимо было писать @Query
с offset и limit параметрами.
Чего не умеет JDBC так это принимать спецификации или Criteria API для динамических запросов. Поэтому необходимо использовать аннотацию @Query и писать динамический запрос как на нативном запросе, так и на HQL.
👾 Мапинг сущностей здесь отличается от JPA. У Spring Data JDBC нет аннотаций @OneToOne, @ManyToOne и других, но здесь присутствует аннотация @MappedCollection(idColumn=objectId)
Когда мы мапим наши сущности, JDBC загружает полностью все объекты. И так как разработчики использовали Domain Driven Design, то Spring Data JDBC использует такую модель как “repository”, “aggregate”, and “aggregate root”.
Теперь рассмотрим агрегаты и рут агрегат (корень агрегата)
Агрегат — это группа сущностей, которая гарантированно непротиворечива между атомарными изменениями в ней.
Каждый агрегат имеет ровно один корень агрегата, который является одним из объектов агрегата. Агрегатом можно манипулировать только с помощью методов этого корня агрегата. Это атомарные изменения.
👀 В текущей реализация Spring Data JDBC работает так: все сущности из корневого агрегата удаляются и пересоздаются с помощью нашего JDBC. Поэтому при создании ссылок на другие сущности, необходимо быть осторожным — иначе получите, например, SqlException при запросе обновления. Рассмотрим на примере.
👨💻 У нас есть сущность Company, у которой есть сущность User:
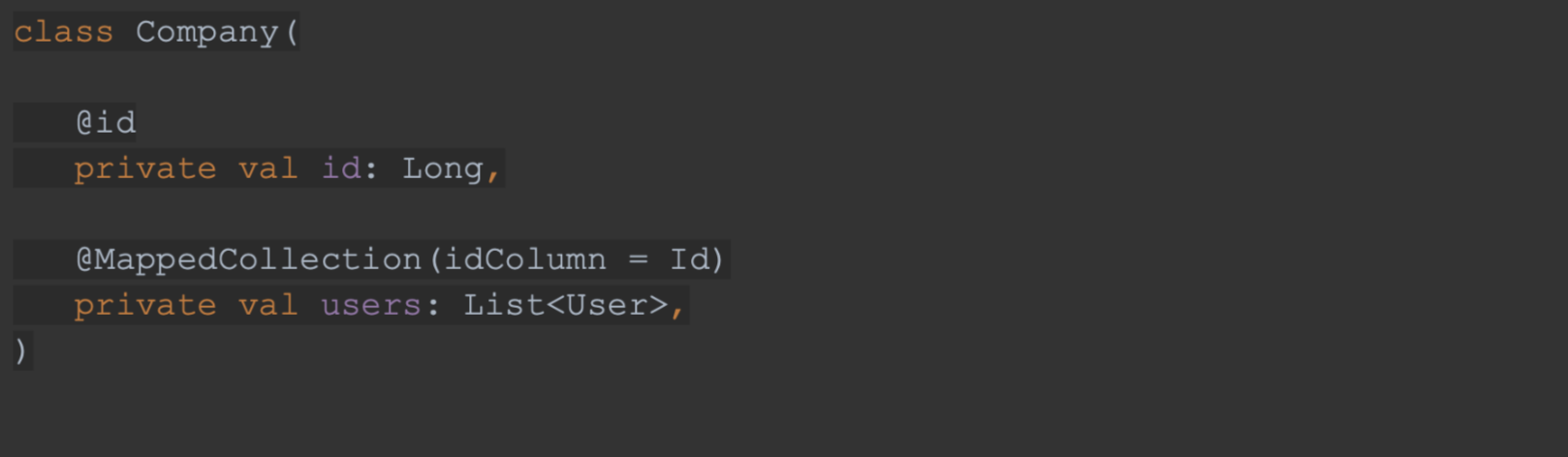

Когда мы попытаемся обновить сущность компании, то при выполнении метода save(company) Spring Data JDBC удалит все сущности User в базе данных и создает по новой.
🙋♀️ Теперь представим на минуту, что наш класс User представлен в таком виде:
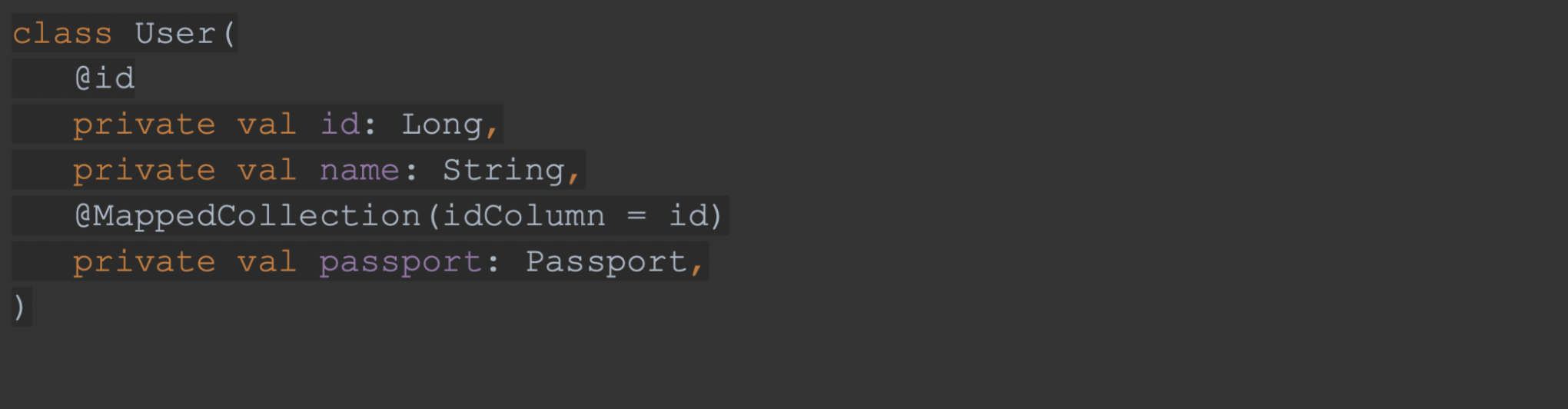
А в базе данных у таблицы юзера есть forgein key на таблицу passport.
Тогда при вызове метода save(company) для обновления команды мы получим SQLException:

В общем, Spring Data JDBC — отличный инструмент, за исключением пары деталей. Если не хотите увязнуть в проблемах ленивой загрузки и dirty tracking в JPA, то стоит взглянуть на данную реализацию Spring DATA.