Специальный выпуск - шифр Виженера. Часть четвёртая (1).
CHe_Love_Vek
Постепенно наш выпуск добрался до самой интересной своей части - взлому рассматриваемого шифра. Несомненная его сложность компенсируется удовольствием от проделанной работы. Рекомендуем немного размять извилины перед дальнейшим чтением - представленная ниже информация может вызвать лёгкое недомогание и нагрев пятой точки у человека без предварительной подготовки.
Warning : все расчёты и поиски НАСТОЯТЕЛЬНО рекомендуется проводить НЕ ВРУЧНУЮ. В противном случае, на момент взлома информация перестанет быть актуальной )
Нестареющая классика
Несмотря на почтенный возраст, метод Касиски продолжает использоваться при взломе шифра Виженера, хоть и в качестве вспомогательного варианта. Его идея состоит в том, что в открытом сообщении повторяющиеся одинаковые наборы букв в словах ( которые называются для двух букв - биграммы, а для трёх - триграммы ), шифруемые одним и тем же отрезком ключа, будут представлены в шифротексте одними и теми же символами ( логично, не правда ли ? ). В этом случае, расстояние между первой буквой первой повторяющейся би/триграммы и между первой буквой второй или любой другой по счёту повторяющейся би/триграммой будет кратно длине ключа :
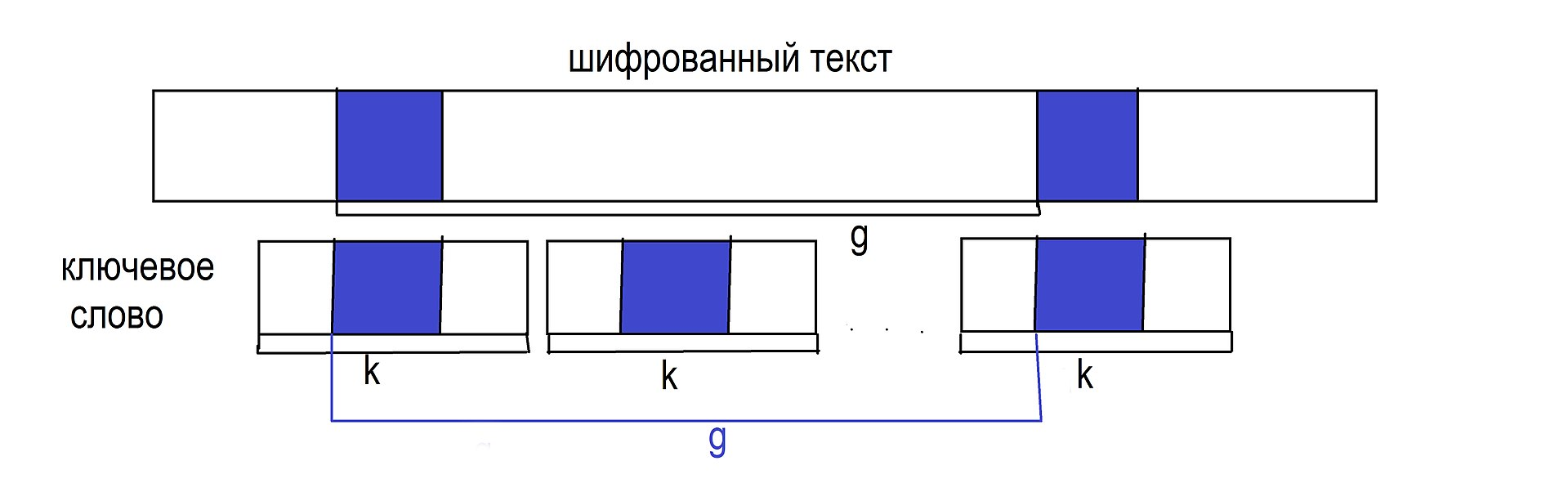
Следует пояснить обозначения : k - длина ключевого слова, g - так называемая подстрока, расстояние от первой буквы би/триграммы до первой буквы следующей за ней би/триграммы. Длина этой самой подстроки, согласно идее, будет кратна длине ключевого слова.
Рассмотрим некоторые особенности работы метода на примере следующего сообщения :
Текст ......THE......THE.......NIJ.....
Ключевое слово ......ION.......ION......IONI.....
Шифротекст ......BVR.......BVR......BVR.....
Ключом в данном случае является триграмма "ION". Отрывок открытого текста "THE", дважды попадая на один и тот же участок ключа, в шифротексте принимает значение "BVR". Однако, мы видим и третье значение "BVR", которое было получено в открытом тексте шифрованием триграммы "NIJ" с помощью отрывка "ONI", а не "ION", как в двух предыдущих случаях. В этом случае расстояние между двумя "B" во втором и третьем "BVR" может быть не кратно длине ключевого слова, а если даже и кратно, то являться случайностью. Этот недостаток метода Касиски накладывает определённые ограничения на поиск повторяющихся отрывков, требуя от взломщика повышенной внимательности.
Наглядным примером будет случай, когда метод не работает совсем :
Текст : MICHI GANTE CHNOL OGICA LUNIV ERSIT Y Ключевое слово : BOYBO YBOYB OYBOY BOYBO YBOYB OYBOY B Шифротекст : NWAIW EBBRF QFOCJ PUGDO JVBGW SPTWR Z
Текст "Michigan Technological University" разбили для удобства на группы по пять букв и зашифровали ключом "boy". Проблема в том, что сообщение в данном случае слишком короткое, а ключевое слово для него - длинное. Поэтому, пытаясь расшифровать текст, мы не найдём повторяющихся подстрок длиннее двух символов. К тому же, их содержание, как и в предыдущем примере, может быть чистой случайностью.
Это всё хорошо ( или не очень ). Но хочется взглянуть на рабочий, удачный пример дешифровки. И такой, к счастью, имеется. Приводим ниже цитату Чарльза Энтони Ричарда, английского учёного в области информатики и вычислительной техники :
There are two ways of constructing a software design:One way is to make it so simple that there are obviouslyno deficiencies, and the other way is to make it so complicatedthat there are no obvious deficiencies.The first method is far more difficult.
Удаляем знаки препинания и разбиваем текст в группы по пять букв :
THERE ARETW OWAYS OFCON STRUC TINGA SOFTW AREDE SIGNO NEWAY ISTOM AKEIT SOSIM PLETH ATTHE REARE OBVIO USLYN ODEFI CIENC IESAN DTHEO THERW AYIST OMAKE ITSOC OMPLI CATED THATT HEREA RENOO BVIOU SDEFI CIENC IESTH EFIRS TMETH ODISF ARMOR EDIFF ICULT
После чего шифруем текст ключом "System" :
LFWKI MJCLP SISWK HJOGL KMVGU RAGKM KMXMA MJCVX WUYLG GIISW ALXAE YCXMF KMKBQ BDCLA EFLFW KIMJC GUZUG SKECZ GBWYM OACFV MQKYF WXTWM LAIDO YQBWF GKSDI ULQGV SYHJA VEFWB LAEFL FWKIM JCFHS NNGGN WPWDA VMQFA AXWFZ CXBVE LKWML AVGKY EDEMJ XHUXD AVYXL
И ищем повторяющиеся строки. После сложных поисков и расчётов ( на компьютере, конечно ), выясняем, что строка открытого текста "THERE ARE" длиной аж 8 символов повторяется 3 раза, причём шифруется она одной и той же подстрокой ключа "SYSTEMSY". На этих же позициях в шифротексте располагается подстрока "LFWKIMJC". Конечно же, это не просто совпадение. Эти строки встречаются на позициях 0, 72 и 144. И 72, и 144 кратны 6, что соответствует длине ключевого слова.
Следующая по длине повторяющаяся подстрока шифротекста "WMLA" имеет длину 4 и встречается на позициях 108 и 182. Расстояние между ними равно 74. На позиции 108 слову соответствует часть ключа "SYST" и подстрока открытого текста "EOTH". Однако, на 182 позиции подстроки и ключа, и открытого текста другие - "STEM" и "ETHO" соответственно. Пусть и отрывки шифротекста на этих позициях идентичны, но шифруются они разными отрывками ключа и из разных подстрок открытого текста. Значит, эти отрезки можно не принимать во внимание и не проводить для них вычисления.
В шифротексте встречаются пять подстрок с длиной 3: "MJC" в позициях 5 и 35, "ISW" в позициях 11 и 47, "KMK" в положениях 28 и 60, "VMQ" в позициях 99 и 165, и "DAV" в положениях 163 и 199.
Расстояния между одинаковыми подстроками следующие :
Для "MJC" - 30 ( 35 - 5 )
Для "ISW" - 36 ( 47 - 11 )
Для "KMK" - 32 (60 - 28 )
Для "VMQ" - 66 ( 165 - 99 )
Для "DAV" - 36 ( 199 - 163 )
Однако, мы вынуждены выбросить из рассматриваемого нами списка "KMK", поскольку каждому из этих отрезков шифротекста соответствуют разные отрезки открытого текста и разные отрезки ключа ( Как в случае с "WMLA" ).
После того, как все строки найдены, нам необходимо составить таблицу соответствий: длина повторяющейся подстроки - расстояние между одинаковыми подстроками - все делители расстояния :
Длина Расстояние Делители
8 72 2 3 4 6 8 9 12 18 24 36 72
66 2 3 6 11 22 33 66
36 2 3 4 6 9 12 18 36
3 32 2 4 8 16 32
30 2 3 5 6 10 15
Диапазон делителей получился внушительным. Теперь попытаемся найти наибольший общий делитель ( НОД ) для всех значений расстояний, сверяясь с таблицей.
Как видим, 32 не делится на 3, как остальные числа, поэтому его мы откидываем, поскольку это показатель того, что число не больше, чем случайность и рассматриваться нами не должно. Для всех остальных чисел, а это 72,66,36,30 наибольший общий делитель 6 - это и есть значение длины ключевого слова. А зная её, мы ломаем Шифр Виженера по алгоритму, представленному в первой части цикла :)
В этой части цикла были представлены стандартные ситуации. Однако, этот алгоритм работает не для всех случаев. Их мы и рассмотрим в следующих выпусках.
============
============