Специализация в data-сфере
https://t.me/alexsecondsМы все наблюдали бурный рост в области данных в последнем десятилетии, концентрацию data-профессионалов внутри нескольких команд в компаниях (зачастую, по таким областям как ETL, BI/Analytics и ML), а также повышение роли и увеличение востребованности специалистов этого направления. Там и тут появлялись позиции Chief Data Officer (CDO) в структуре топ менеджмента, что также однозначно говорит о важности (и, конечно, местами хайпе) всего того, что обеспечивает, поддерживает, развивает и предоставляет доступ к бизнес-данным.

В последние пять лет начал расцветать рынок разнообразных open source инструментов. Вместо проприетарных ETL-приложений от таких монстров как Microsoft и SAP, многие компании и команды начали делать выбор в пользу именно OSS для оркестрации пайплайнов, нацеливаясь на по сути безграничные возможности по их кастомизации, на заметную экономию денег на лицензиях и, конечно же, на огромный потенциал для горизонтальной масштабируемости. Мы своими глазами наблюдали появление таких, ныне популярных, инструментов как Prefect, Dagster и других, включая безусловного лидера Apache Airflow.
Параллельно с ETL-инструментами, которые вместе с общим движением в сторону облаков популярные cloud-провайдеры начали оборачивать в свои managed-сервисы, в виду увеличившейся доступности облачных ресурсов начали появляться и новые инструменты для простой и удобной работы с машинным обучением. В 2017 году в публичную бету выходит PyTorch, за несколько лет активного развития выходят мажорный релиз TensorFlow в 2017 году, активно развивается и также набирает популярность scikit-learn, первый мажорный релиз которой, правда, появится уже позже, в 2021. Перенимая опыт из мира open source, а заодно и делая вклад в его развитие, крупные игроки рынка облачных услуг (AWS, GCP, Microsoft и другие) стараются нарастить свой парк доступных ML- и AI-сервисов.

Не отстает и рынок сервисов и приложений для визуализации. Появляются такие монстры как Tableau. То там, то тут появляются и новые ласточки. Looker, Metabase, Redash, Superset. Проприетарное ПО соревнуется с open source. Каждый инструмент находит свою нишу и своих пользователей. В определенный момент во время пандемии наступает ситуация, когда у бизнеса появляется запрос на data story telling, в связи с чем набирают популярность такие инструменты, как Streamlit, например, после нескольких лет стагнации новый виток развития получает RAWGraphs. С ними вместе появляются все новые и новые платные инструменты и сервисы для сторителлинга, а существующие инструменты визуализации, чувствуя рост популярности нового направления, спешно добавляют функции для поддержки нового подхода к подготовке аналитических отчетов и интерактивных презентаций.
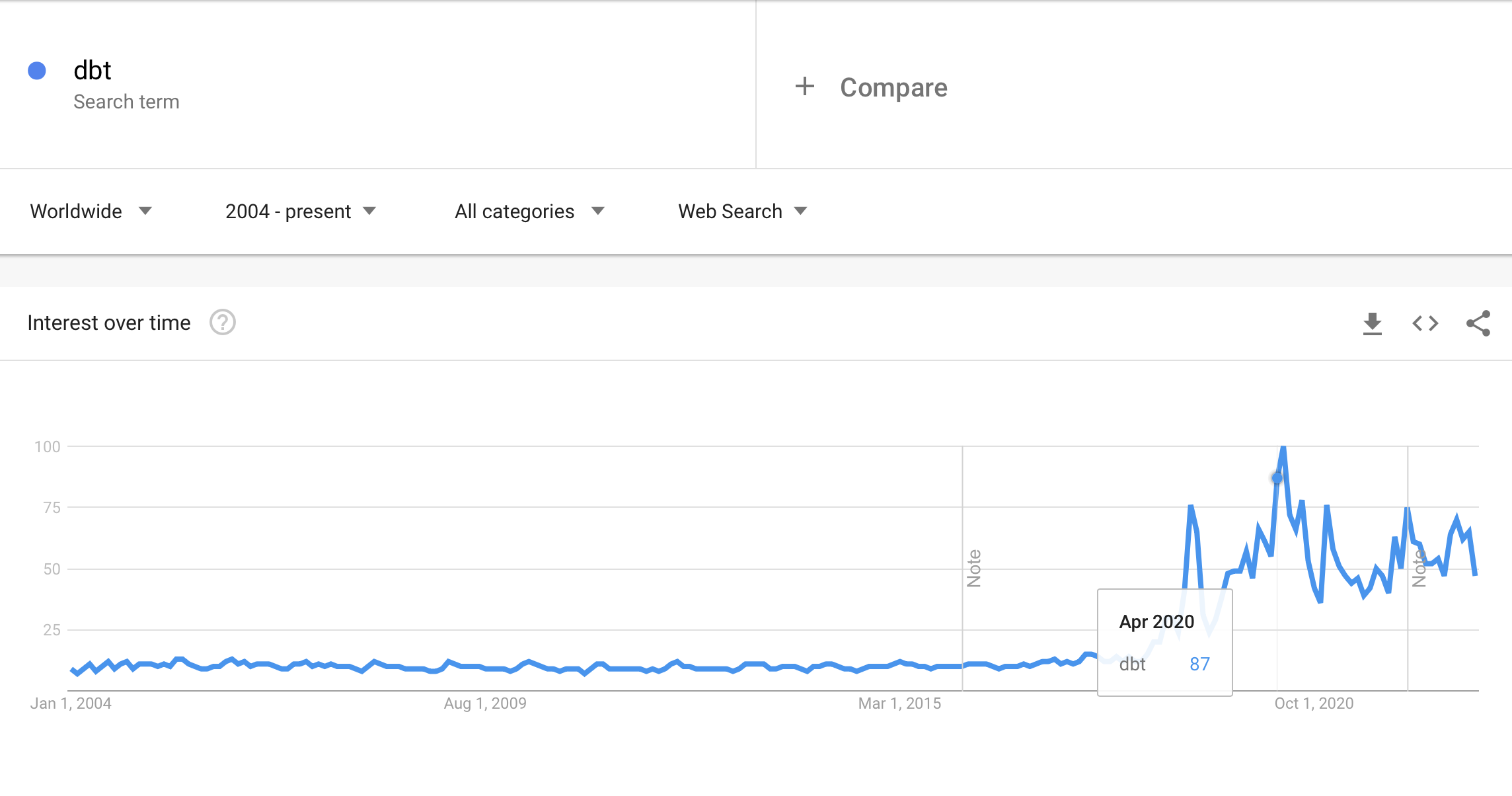
В 2020 году мир накрывает пандемия. Из-за ковидных ограничений мощно растет рынок удаленной торговли, медицинских и прочих сервисов. Объем хранимых и обрабатываемых данных растет пропорционально. В попытках систематизировать все нарастающие потоки JSON-ов, CSV и Parquet, которые в конечном счете попадают в аналитическую базу данных, индустрия развивается сразу в нескольких направлениях. Набирают популярность managed базы данных, такие как, Snowflake, а также, учитывая очередной виток популярности SQL для обработки данных, появляется необходимость систематизировать весь код. После активного роста ранее, в 2020 году происходит резкий всплеск популярности всем известного ныне инструмента для организации и систематизации потоков данных под названием dbt.
В 2022 году компании начинают осознавать, что объем накопленных данных огромен, а обеспечение быстрого и удобного доступа к ним становится не такой уж и простой задачей. Активно развиваются и продаются как старые, так и новые инструменты из ряда data-каталогов. OpenMetaData, Apache Atlas, Datahub, Atlan и другие. Скорость набора навыков уже состоявшимися data-инженерами, а также скорость набора новых подобных специалистов, пока еще не снижается; нужны свежие идеи и дополнительные руки для работы с непрерывно расширяющимся техническим стеком.
Постепенно вместе со спросом на каталоги данных, приходит осознание того, что все знания, понимание структур и взаимосвязей между разными доменами данных, которые надо описать в этих каталогах, сложно уместить в рамки одной постоянно расширяющейся data-команды. Появляется запрос на переосмысление способов взаимодействия между подразделениями и организации процессов внутри компаний. Появляется вектор на специализацию — data-командам нужны новые роли, которые будут закрывать потребности в новой организационной структуре.
Data Product Manager
Следствием наличия громадных объемов данных для обработки и необходимости описания этих данных в дата каталогах, является децентрализация data-команд. Имея децентрализованную команду, очень важно не потерять в скорости доставки данных и наладить коммуникацию между провайдерами данных и их потребителями. На стыке всех этих проблем и будет нужен Data Product Manager. Эта роль — смесь классического Product Manager, Data Engineer и Data Analyst. Человек на этой позиции сфокусирован на доступности и демократизации данных, увеличении ROI для данных, улучшения точности инсайтов и прогнозов, а также на экономии времени как среди членов data-команды, так и среди пользователей этих данных.
Data Governor или Data Steward
Кому-то безусловно нужно будет поработать и руками, собирать описание и заполнять сущности в каталогах, и здесь как раз потребуется давно всем известная (кажется еще из 2000-х годов) роль Data Steward. Тот, кто давно работает в сфере данных, помнит, что во всех крупных проектах и системах существовали один или несколько специалистов, ответственных за ведение данных в справочниках (master data management), идентификацию проблем и ошибок в источниках данных, а также за уведомление о них. Эта роль в очередной раз обретает популярность в связи с новым витком изменений и в связи с размазыванием data-процессов среди всех команд.
Data Reliability Engineer
Чем более зрелая команда инженеров данных, тем больше времени она тратит на внедрение различных проверок и валидаций на входе, при трансформации и после публикации данных конечным пользователям. Data Reliability Engineer будет сфокусирован именно на указанных задачах, улучшении качества публикуемых данных и повышении доверия к ним. Использование data quality tools наподобие Deequ, Great Expectations и Monte Carlo, а также определение требуемых проверок и бизнес-правил для данных вместе с провайдерами и пользователями данных будет занимать большую часть рабочего времени этих специалистов.
DataOps Engineer
Ну и наконец, опять же благодаря тому, что команды становятся распределенными, управление процессами доставки данных выходит на первый план. Существующим продуктовым командам нужно уже самостоятельно загружать данные в хранилище и делать доступными эти данные для конечных пользователей. Чтобы команды имели возможность делать self-service ETL, как раз будет нужен DataOps Engineer, который будет создавать, настраивать и поддерживать shared-решения внутри компании, такие, например, как Airflow-as-a-Service в компаниях. Наряду с написанным, специалист в этой роли должен будет обеспечивать также безопасность используемых инструментов и упрощать их использование через обратную связь с другими командами и документирование.
Навеяно следующими источниками:
- Data Platforms: The Future, Alexandre Beauvois
- The rise of the Data Engineer, Maxime Beauchemin
- Our Top 5 Articles on Data Teams in 2022, Monte Carlo