Создаём единую инфраструктуру для параллельной разработки мобильных игр
Она помогла нам переиспользовать игровые механики в непохожих проектах и увеличила скорость разработки на 25%.

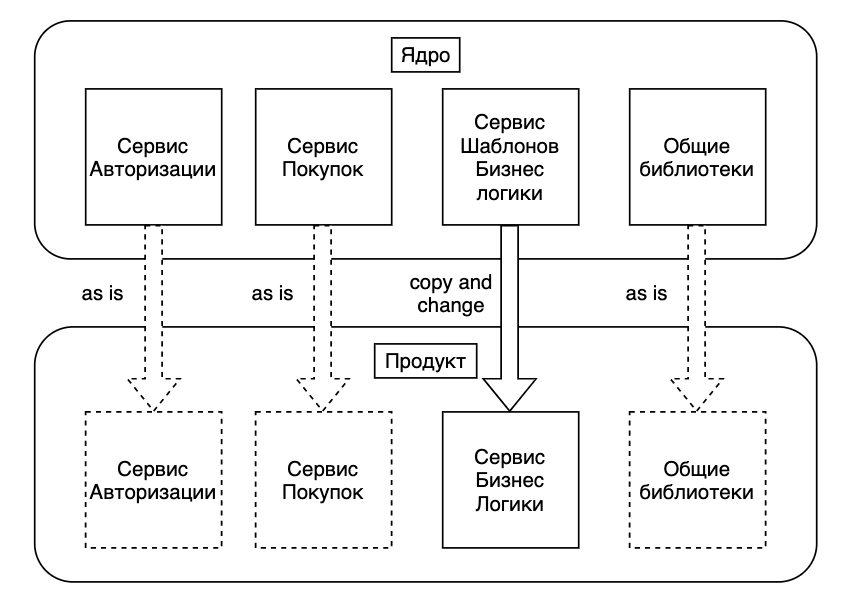
Что такое серверное ядро?
Для нас это набор микросервисов и внутренних инструментов, на основе которого можно быстро запустить работающую серверную часть с базовым набором механик для нового проекта. Магазин, модели персонажей, инвентарь, валюты, новости — мы предоставляем это разработчику проекта в абстрактной, но хорошо настраиваемой форме.
При работе над несколькими проектами в рамках одной студии обычно есть два подхода к разработке: изолированная и параллельная. При изолированной каждый проект разрабатывается с нуля и имеет свою архитектуру. Во втором варианте вначале собирается общая база проектных решений, а на её основе параллельно создаётся несколько проектов с общими механиками.
Часто такой базой становится первый проект студии. Нам в руки попало сразу четыре проекта на этапе формирования требований.
С учётом сроков и требований бизнеса у нас было только два варианта подхода: или каждый член команды берёт по проекту и работает над ним, или создаём общую кодовую базу и отталкиваемся от неё. Мы выбрали второй вариант.
Вот какие задачи решаем с помощью серверного ядра:
- Авторизация пользователя — связывание данных с уникальными идентификаторами, предоставляемыми социальными сетями.
- Обработка покупок — получение чеков платёжных систем от клиента и верификация их на стороне платёжной системы.
- Обеспечение межсерверного взаимодействия — стандартные механизмы коммуникации между микросервисами, реализованные на уровне фреймворка.
- Архитектурные подходы и паттерны для написания бизнес-логики — работа с данными игрока, работа с базой, структура взаимодействия логических сущностей внутри игры. Ядро предлагает библиотеку архитектурных решений, на которые можно опираться при выработке своих.
- Архитектура для автотестов — налаженный процесс, который можно в готовом виде использовать на всех проектах, и набор примеров автотестов, которые клиент может использовать как эталон для своих проверок.
- Пайплайны для CI/CD — это процесс организации обновлений кода в репозитории. Однажды налаженный на сервисах ядра он распространяется по остальным проектам по единой схеме.
- Devops-инфраструктура — единое ядро и схема коммуникации микросервисов позволяет выстроить общую для всех проектов схему масштабирования в зависимости от нагрузки в облаке.
С единым ядром разработчик на конкретном проекте может не переживать, как правильно с нуля выстроить архитектуру. Он получает заготовку и выбирает необходимые механики, к которым добавляет нужные геймдизайнеру детали.
Универсальные решения позволяют команде работать эффективнее.
Но, как и с любой технологией, тут не обошлось без слабых мест. Если количество проектов в работе у студии ниже определённого предела, то такой подход требует дополнительных ресурсов. Кроме того, сам подход довольно требователен к экспертизе разработчиков ядра: если это ваш первый проект, вы наверняка ошибётесь. Тут важен опыт.
По предварительным оценкам, мы экономим время, начиная с четырёх параллельно разрабатываемых проектов. Каждый следующий проект экономит компании одну роль серверного разработчика. Сейчас в работе шесть проектов, так что грубая оценка экономии 0,75X от базового X времени по совокупности.
Добавление механик или инструментов в ядро
Давайте рассмотрим пример инструмента, который можно легко распространить между проектами, но не так просто придумать с первого раза.
Представим, что геймдизайнеру или тестировщику необходимо проверить игровой баланс. Им часто нужно иметь возможность настраивать данные игроков. Для этого используют чит-панель — редактор для отладки игровых данных изнутри клиента игры, геймдизайнеры не любят изменять базы данных напрямую (простим им эту слабость).
Возникает вопрос — как добавить эту механику в ядро так, чтобы не ломать архитектуру и совместимость с другими командами? Пришлось повозиться, но в итоге мы нашли решение.
В примере выше самое простое, что приходит на ум, — добавить в API конкретные запросы по просьбе клиентов. Например, чтобы начислить валюту — запрос «начислитьВалюту», а чтобы добавить сущность — запрос «добавитьСущность».
Например:
@MessagePattern(AddBusinessAssetDto.CommandName)
async addBusinessAsset(@Payload() body: AddBusinessAssetDto) {
const player = await this.getPlayer(body);
…
const { businessAssetId } = body.data;
const businessAsset = await this.service.addBusinessAsset(
player,
businessAssetId,
);
const updates = await player.save();
return buildSuccessAnswer(businessAsset, { updates });
}
В API появляются запросы:
- add-business-asset-cheat
- add-currency-cheat,
- add-item-cheat
и так далее.
Эти запросы легко добавить — и вначале это кажется отличной идеей. Но по мере развития механик игры оказывается, что сложность структуры данных игрока растёт, появляется всё больше компонентов и сущностей. У них появляются новые параметры.
Содержать и поддерживать много запросов становится всё тяжелее. Чит-панели начинают требовать сложного поведения, а оно вызывает сразу несколько запросов, и поддержка читов становится головной болью. Кроме того, у нас множество проектов, у каждого из которых отдельный и независимый набор сущностей и их параметров, а значит и запросы на каждом проекте должны создаваться независимо.
После того как чит-запросы на двух проектах начали отнимать ощутимое время разработки, мы решили пересмотреть подход. Сделали универсальный DSL (Domain-specific language) для описания трансформаций данных игрока. С помощью DSL разработчик со стороны клиента может пользоваться одним серверным запросом для любых изменений — и им больше не нужно добавлять новые или модифицировать существующие запросы для читов:
apply-modifications
…
"modifications": [
{
"type":"businessAsset",
"action":"add",
"params":{
"id": "ba_0001",
"capture": true,
"level": 5,
}
},
{
"type":"currency",
"action":"add",
"params":{
"id": "cryptoCoin"
"amount": 3000
}
}
]
Типы сущностей от проекта к проекту будут меняться, но синтаксис запроса остаётся тем же. Конечно, код, обслуживающий этот запрос, не будет простым, но его поддержка требует минимум ресурсов. Такой подход позволяет настраивать чит-панель без участия бэкенд-разработчика.
…
@MessagePattern(ApplyModificationsDto.CommandName)
@UseInterceptors(PlayerModelInterceptor(false))
@UseGuards(DevelopmentGuard)
async modificatePlayer(
@Payload() data: ApplyModificationsDto,
@Ctx() { player }: ClientContext,
) {
const result = await this.modifiactionService.execute(
player,
data.data.modifications,
);
const updates = await player.save();
return buildSuccessAnswer(result, { updates });
}
public async execute(player: Player, modifications: TModification[]) {
const invalidModifications = await this.validateModifications(
modifications,
);
if (invalidModifications.length) {
Logger.warn(
`Bad modifications. Validation result: ${JSON.stringify(
invalidModifications
)}`,
this.constructor.name,
);
return { success: false, invalidModifications };
}
for (const modification of modifications) {
await this.modificationExecutorsProvider
.getExecutor(modification.type)
.execute(player, modification);
}
return { success: true };
}…
И как приятный бонус: разработчик не забудет изолировать чит-запросы от продакшена, потому что он уже архитектурно изолирован.
Передача обновлений ядра другим клиентам
В процессе работы нет необходимости придумывать какие-то специальные абстракции для ядра — сам процесс разработки игры подсказывает, что должно обобщаться, а что может быть сделано в самом проекте. Сейчас практически все изменения для ядра формируются «снизу» — на проектах.
Например, из одного к нам пришла механика универсальной проверки условий, а из другого мы добавили механику ежедневных квестов и наград. Эти две механики, удачно соединившись, отправились в третий проект, где нужны были квесты, для появления которых требуется проверка условий.
После того как ядро получило изменения от клиента, мы можем передать их в базы данных других клиентов. Чтобы добавить механики или инструменты на конкретный проект, надо обновить код их проекта.
Обновление ядра — двунаправленная история. Часть изменений проектов попадает в ядро, необходимые изменения ядра распределяются по остальным проектам. Это происходит через Git Merge и иногда болезненный процесс ручного слияния. Мы пока не нашли варианты, как сделать это автоматизировано.
Полная изоляция модулей ядра от логики игры пока требует слишком большого вложения сил, и мы не идём в этом направлении. Предполагается, что разработчик должен понимать, что он делает, какой код и куда встраивает.
Единая функциональность при различных требованиях
Не становится ли единое ядро ограничением в выборе архитектурных решений на разных проектах? Иногда у клиентских программистов возникают противоречивые требования к модулям ядра. И это естественно.
У каждой из команд своё видение, как должна быть устроена их архитектура, и у нас нет желания навязывать собственное. И мы готовы делать уступки клиентам, потому что игра — их основной продукт. Наша история — инфраструктура. Мы стараемся предлагать командам механики, которые им подходят.
Одним из таких случаев было проектирование механики отправки обновлений пользователей. Первый вариант — использование JSON Patch в качестве списка изменений в данных клиентах — был разработан совместно с клиентской командой, которая предпочитала UniRX и реактивщину. Но не на всех проектах клиентские разработчики оценили подход, и нам пришлось расширить функциональность ядра.
А не ограничивает ли ядро клиентских разработчиков детским выбором определённых инструментов? Был случай, когда нашим клиентам не подошёл предложенный нами способ доставки обновлений ядра.
После раздумий и проб мы реализовали три подхода к получению обновления доступные нашим проектам. Для того, чтобы клиентские разработчики могли получать обновления так, как им удобно.
- В первом случае — это список того, что изменилось в данных клиента в формате JSON Patch.
- Второй вариант представляет перечень изменений корневых сущностей. Мы пишем, что поменялось, и передаём объект клиенту целиком. Тут сохраняется совместимость с JSON Patch, но клиенту нет необходимости самому разбирать каждую строку, он может загружать все данные объекта.
- И в третьем случае — это JSON-структура. Сама модель, но содержащая только изменённые поля. Здесь клиенту уже нет необходимости поддерживать формат JSON Patch.
Каждый вариант по-своему хорош и используется разными командами.
Для наглядности пример первого варианта апдейта:
[
{
"op": "replace",
"path": "/kicks/random/seed",
"value": 2926611012
},
{
"op": "add",
"path": "/dailyRewards/slots/0",
"value": {
"id": 2,
"status": 0
}
},
{
"op": "replace",
"path": "/dailyRewards/slots/1/status",
"value": 0
},
{
"op": "replace",
"path": "/dailyRewards/resetTime",
"value": 1643362211
},
{
"op": "remove",
"path": "/foo"
}
]
Во втором варианте передача производится в том же формате JSON Patch за одним изменением — будут передаваться заранее определённые сущности целиком и всегда в контексте op = "replace" или "add". "remove" будет передаваться как "replace" cо значением null.
Модифицированный под реализацию апдейт из примера выше:
[
{
"op": "replace",
"path": "/kicks/random",
"value": {
"seed": 2926611012
}
},
{
"op": "add",
"path": "/dailyRewards/slots/0",
"value": {
"id": 2,
"status": 0
}
},
{
"op": "replace",
"path": "/dailyRewards/slots/1",
"value": {
"id": 1,
"status": 0
}
},
{
"op": "replace",
"path": "/dailyRewards/resetTime",
"value": 1643362211
},
{
"op": "replace",
"path": "/foo",
"value": null
}
]
В третьем древовидном варианте передача производится в том же формате, что и сама клиентская модель, но в модели апдейта присутствуют только изменённые сущности.
Модифицированный под реализацию апдейт из примера выше:
{
"kicks": {
"random": {
"seed": 2926611012
}
},
"dailyRewards": {
"slots": {
"0": {
"id": 2,
"status": 0
},
"1": {
"id": 1,
"status": 0
}
},
"resetTime": 1643362211
},
"artefacts": {
"map": {
"02": null
}
},
"foo": null
}
Чтобы успешно добавить все механики и инструменты в ядро, передать их клиентам и поддерживать их работу, требуются классные разработчики, которые должны понимать архитектуру нашей системы.
Чтобы они быстрее разобрались с нюансами, мы улучшили процесс онбординга.
Как мы проводим онбординг новых разработчиков
Наши проекты работают на Node.js, а пишем мы на TypeScript. В качестве фреймворка мы используем Nest.js. Для коммуникации сервисов использовался RabbitMQ, и недавно мы переехали на NATS, основная база данных MongoDB. В качестве основного облака используем AWS. Мы старались выбирать инструменты максимально близкие к SoTA серверной разработки.
Сейчас мы активно набираем разработчиков в команду — она уже выросла до шести человек, и мы планируем нанять ещё троих специалистов. Когда к нам присоединяется новый разработчик, перед нами стоит задача рассказать, что и как в нашей системе устроено. Научить его пользоваться уже выстроенной архитектурой.
Конечно, новые члены команды получают от нас документацию. Но документация без живого общения работает плохо, а поскольку работаем мы удалённо, разговоры в курилках достаточно сложно организовать. Зато у нас есть свой дискорд-канал для обсуждения любых текущих вопросов. На совместных синках мы рассказываем, что происходит, какие решения и по каким процессам принимаются, держим друг друга в курсе. У нас не экзотическая архитектура, и мы стараемся принимать логичные и прозрачные решения, поэтому такой подход работает.
Весь код, который пишет команда, проходит через внутреннее ревью. Плюс в процессе написания кода каждый может задавать вопросы, как по деталям реализации, так и по архитектуре. Новичкам всегда подскажут, какие решения можно выбрать, есть ли уже похожие механики в ядре и как устроен процесс отладки.
Говорим, что хорошо, а что нет. Что-то, например, может не укладываться в наш подход. Обязательно слушаем аргументы и в результате приходим к консенсусу. После двух или трёх циклов человек уже понимает схему нашей работы и может в этом процессе участвовать на правах полноценного члена команды. Обычно это занимает две-три недели.